Product
Marengo 2.6: A State-of-the-Art Video Foundation Model for Any-to-Any Search
Aiden Lee, James Le
This blog post introduces Marengo-2.6, a new state-of-the-art multimodal embedding model capable of performing any-to-any search tasks.
This blog post introduces Marengo-2.6, a new state-of-the-art multimodal embedding model capable of performing any-to-any search tasks.

In this article
Join our newsletter
Join our newsletter
Receive the latest advancements, tutorials, and industry insights in video understanding
Receive the latest advancements, tutorials, and industry insights in video understanding
Search, analyze, and explore your videos with AI.
Mar 1, 2024
5 Min
Copy link to article
1 - Bullet Point Summary
Introduction to Marengo-2.6: A new state-of-the-art (SOTA) multimodal foundation model capable of performing any-to-any search tasks, including Text-To-Video, Text-To-Image, Text-To-Audio, Audio-To-Video, Image-To-Video, and more. This model represents a significant leap in video understanding technology, enabling more intuitive and comprehensive search capabilities across various media types.
New State-of-the-Art Performance: Marengo-2.6 sets new benchmarks in zero-shot text-to-video, text-to-image, and text-to-audio retrieval tasks with a single embedding model. It outperforms Google's VideoPrism-G model by +10% on the MSR-VTT dataset and +3% on the ActivityNet dataset. Additionally, it surpasses the state-of-the-art image foundation model in zero-shot text-to-image retrieval tasks, showcasing its ability to understand and process visual content The results bolster the efficacy of our video-first research ethos. An AI system that learns from video can exhibit impressive perceptual reasoning abilities across multiple modalities.
Expanded Multimodal Capabilities: The model's expanded capabilities allow for any-to-any (cross-modality) retrieval tasks, making it a versatile tool for a wide range of applications. This includes text-to-video, text-to-image, text-to-audio, audio-to-video, and image-to-video tasks, bridging different media types.
Enhanced Temporal Localization: The model introduces a Reranker model for better temporal localization. This enhancement allows for more precise search results.
2 - The Rise of Video Foundation Models

Video data is inherently redundant, high-dimensional, and temporally structured, closely resembling sensory data but difficult to parse and interpret. Traditional models often struggle to capture the nuanced interplay between frames, missing out on the rich contextual cues that give video its meaning.
The journey towards effective video understanding has seen significant advancements in multimodal embedding models. The understanding that human perception is inherently multimodal has led to the development of models capable of processing and integrating multiple types of data.
By integrating visual, textual, and auditory information, multimodal embedding models learn much more robust representations of the world. Marengo-2.6 is the culmination of our efforts, offering unparalleled capabilities in video understanding and any-to-any retrieval tasks.
3 - Marengo 2.6 Model Overview
3.1 - Architecture: Gated Modality Experts
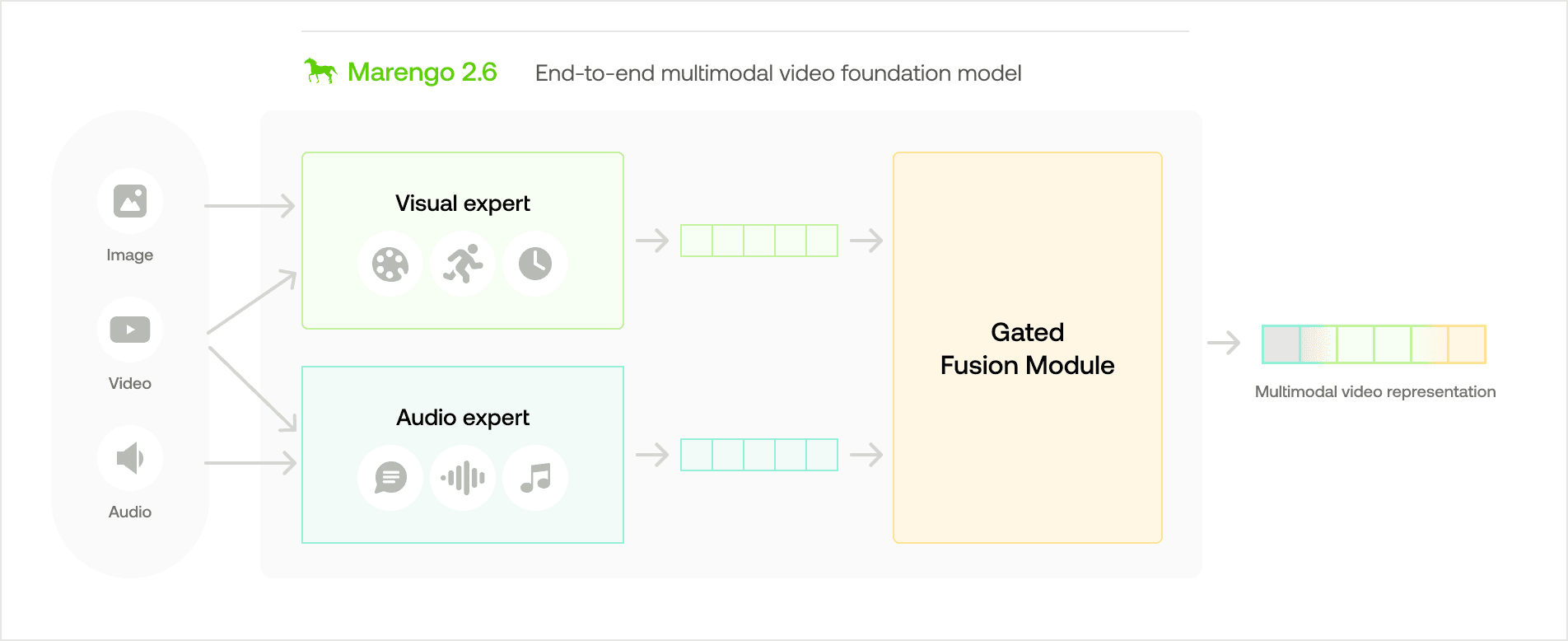
Marengo-2.6's architecture, as shown in the visual diagram above, is based on the concept of "Gated Modality Experts". This allows for the processing of multimodal inputs through specialized encoders before combining them into a comprehensive multimodal representation.
The architecture consists of several key components:
The Visual Expert processes visual information to capture appearance, motion, and temporal changes within the video.
The Audio Expert processes auditory information to capture both verbal and non-verbal audio signals related to the video.
The Gated Fusion Module assesses the contribution of each expert for videos, and merges them into a unified multimodal representation for any-to-any retrieval tasks.
3.2 - Training and Data
Training for Marengo-2.6 focuses on self-supervised learning with contrastive loss on a comprehensive multimodal dataset. As we mentioned in our previous blog, we've curated and augmented a dataset that's beneficial for training the model. It contains:
Video Data: 60 million videos, with both visual and auditory information extracted
Image Data: 500 million images
Audio Data: 500k sounds, including both general non-verbal sounds and music
This diverse, large-scale dataset has allowed Marengo-2.6 to gain a deep understanding of various modalities, equipping it to handle a wide range of retrieval tasks.
4 - Evaluation and Results
4.1 - Quantitative Results
Marengo-2.6 model has been evaluated against a range of state-of-the-art foundation models from diverse modalities. Quantitative results show its superior performance in various text-to-any retrieval tasks.
The model sets new state-of-the-art performance records across all text-to-any retrieval datasets, surpassing existing models by a considerable margin. We plan to release broader benchmark results for general embedding-based tasks soon.
Baseline Models
Data Filtering Network-H/14-378 (Fang et al, Apple & University of Washington, 2023.09): This open-source image foundation model is based on the CLIP training objective. It was trained on 5 billion image-text pairs with a 378x378 image resolution.
LanguageBind-H (Zhu et al, Peking University, 2024.02): This open-source video foundation model processes both audio and visual information and was reportedly trained on 10 million video-text pairs (VIDAL-10m dataset).
VideoPrism-G (Zhao et al, Google, 2024.02): This video foundation model processes visual information and was reportedly trained on 618 million video-text pairs.
(Commercial) Google Gemini(GenAI) Multimodal Embedding API
Zero-shot Video Retrieval (ZS-T2V):

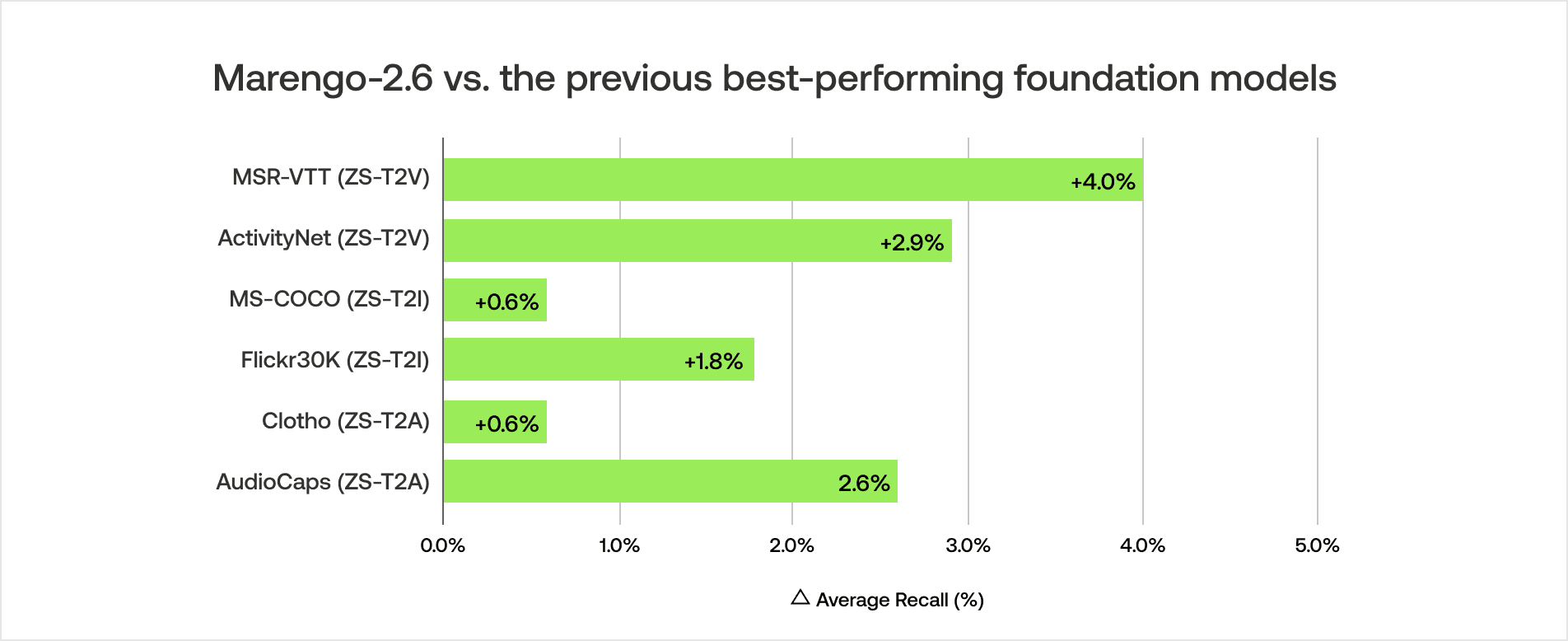
Marengo-2.6 has set a new state-of-the-art on MSR-VTT and ActivityNet datasets, with average recall improvements of +4% on MSR-VTT and +2.9% on ActivityNet compared to the previous best models. (Average recall is calculated as the mean of Recall@1 and Recall@5)
Zero-shot Image Retrieval (ZS-T2I):

The model also establishes the new state-of-the-art performance on the MS-COCO and Flickr30k datasets. Remarkably, it surpasses the previous state-of-the-art image foundation model, which was exclusively trained on a large corpus of image data. This suggests that Marengo-2.6 is capable of learning spatial visual cues effectively through a large video corpus. (Average recall is calculated as the mean of Recall@1 and Recall@5)
Zero-shot Audio Retrieval (ZS-T2A):

Lastly, the model sets the new state-of-the-art performance on Clotho and AudioCaps datasets by learning auditory cues from videos. However, compared to the visual retrieval benchmark, the absolute performance is lower. This discrepancy highlights an area for potential improvement in future model iterations. (Average recall is calculated as the mean of Recall@1 and Recall@10)
These results not only validate the effectiveness of our model's architecture and training but also underscore its potential to accelerate the advancement in the field of multimodal data retrieval and understanding.
4.2 - Qualitative Retrieval Results
Text-To-Video (T2V)
Query: Number 3 Seattle Seahawks avoids sack, throws to Number 83 David Moore in end zone for touchdown.
Top-3 Results:
Text-To-Image (T2I)
Query: A child holding a flowered umbrella and petting a yak.
Top-3 Results:



Query: Two giraffe standing next to each other on a grassy field.
Top-3 Results:



Text-To-Audio (T2A)
Query: After blustering loudly, the wind eventually dies down.
Top-3 Results:
Query: A group of kids are playing together and cheer.
Top-3 Results:
Audio-To-Video (A2V)
Query (Subway Sound)
Top-3 Results (Audio is not used):
Query (Sound of Sheep)
Top-3 Results (Audio is not used):
Image-To-Video (I2V)
Query (Image):

Top-3 Results:
Query (Image):

Top-3 Results:
Video-To-Video (V2V)
Query:
Top-3 Results:
Query:
Top-3 Results:
Closing Remarks
Twelve Labs is proud to introduce Marengo-2.6. Our video foundation model offers a pioneering approach to multimodal representations tasks not just to video but also image and audio. It is a meaningful first step towards achieving our mission of making videos just as easy as text.
In the upcoming week of March 2024, we will make Marengo-2.6 available on our Playground and API environments. This will provide users with the opportunity to interact with the model firsthand, experiencing its capabilities and integrating its state-of-the-art performance into their own applications and workflows.
Our team is committed to continuous improvement and transparency in the performance of our models. To that end, we will soon release a broader benchmark that compares Marengo-2.6 against other embedding tasks. This will offer a more comprehensive view of the model's performance and its standing in the field.
We are a group of friendly, curious, and passionate people from all walks of life with a vision of driving the technological singularity for the betterment of humanity.
More coming soon.
Acknowledgement - Twelve Labs Team:
This is a joint team effort across multiple functional groups including model and data (”core” indicates Core Contributor), engineering, product and business development. (First-name alphabetical order)
Model: Aiden Lee, Cooper Han, Flynn Jang, Jae Lee, Jay Yi, Jeff Kim (core), Jeremy Kim, Kyle Park, Lucas Lee, Mars Ha (core), Minjoon Seo, Ray Jung, William Go
Data: Daniel Kim (core), Jay Suh (core)
Deployment: Abraham Jo, Ed Park, Hassan Kianinejad, SJ Kim, Tony Moon, Wade Jeong
Product: Andrei Popescu, Esther Kim, EK Yoon, Genie Heo, Henry Choi, Jenna Kang, Kevin Han, Noah Seo, Sunny Nguyen, Ryan Won, Yeonhoo Park
Business & Operations: Anthony Giuliani, Dave Chung, Hans Yoon, James Le, Jenny Ahn, June Lee, Maninder Saini, Meredith Sanders, Soyoung Lee, Sue Kim, Travis Couture
Resources:
Link to sign up and play with our API (Marengo-2.6 will be available in our Playground in the upcoming week of March)
Link to the API documentation
Link to our Discord community to connect with fellow users and developers
If you use this model in your work, please use the following BibTeX citation and cite the author as Twelve Labs:
1 - Bullet Point Summary
Introduction to Marengo-2.6: A new state-of-the-art (SOTA) multimodal foundation model capable of performing any-to-any search tasks, including Text-To-Video, Text-To-Image, Text-To-Audio, Audio-To-Video, Image-To-Video, and more. This model represents a significant leap in video understanding technology, enabling more intuitive and comprehensive search capabilities across various media types.
New State-of-the-Art Performance: Marengo-2.6 sets new benchmarks in zero-shot text-to-video, text-to-image, and text-to-audio retrieval tasks with a single embedding model. It outperforms Google's VideoPrism-G model by +10% on the MSR-VTT dataset and +3% on the ActivityNet dataset. Additionally, it surpasses the state-of-the-art image foundation model in zero-shot text-to-image retrieval tasks, showcasing its ability to understand and process visual content The results bolster the efficacy of our video-first research ethos. An AI system that learns from video can exhibit impressive perceptual reasoning abilities across multiple modalities.
Expanded Multimodal Capabilities: The model's expanded capabilities allow for any-to-any (cross-modality) retrieval tasks, making it a versatile tool for a wide range of applications. This includes text-to-video, text-to-image, text-to-audio, audio-to-video, and image-to-video tasks, bridging different media types.
Enhanced Temporal Localization: The model introduces a Reranker model for better temporal localization. This enhancement allows for more precise search results.
2 - The Rise of Video Foundation Models
Video data is inherently redundant, high-dimensional, and temporally structured, closely resembling sensory data but difficult to parse and interpret. Traditional models often struggle to capture the nuanced interplay between frames, missing out on the rich contextual cues that give video its meaning.
The journey towards effective video understanding has seen significant advancements in multimodal embedding models. The understanding that human perception is inherently multimodal has led to the development of models capable of processing and integrating multiple types of data.
By integrating visual, textual, and auditory information, multimodal embedding models learn much more robust representations of the world. Marengo-2.6 is the culmination of our efforts, offering unparalleled capabilities in video understanding and any-to-any retrieval tasks.
3 - Marengo 2.6 Model Overview
3.1 - Architecture: Gated Modality Experts
Marengo-2.6's architecture, as shown in the visual diagram above, is based on the concept of "Gated Modality Experts". This allows for the processing of multimodal inputs through specialized encoders before combining them into a comprehensive multimodal representation.
The architecture consists of several key components:
The Visual Expert processes visual information to capture appearance, motion, and temporal changes within the video.
The Audio Expert processes auditory information to capture both verbal and non-verbal audio signals related to the video.
The Gated Fusion Module assesses the contribution of each expert for videos, and merges them into a unified multimodal representation for any-to-any retrieval tasks.
3.2 - Training and Data
Training for Marengo-2.6 focuses on self-supervised learning with contrastive loss on a comprehensive multimodal dataset. As we mentioned in our previous blog, we've curated and augmented a dataset that's beneficial for training the model. It contains:
Video Data: 60 million videos, with both visual and auditory information extracted
Image Data: 500 million images
Audio Data: 500k sounds, including both general non-verbal sounds and music
This diverse, large-scale dataset has allowed Marengo-2.6 to gain a deep understanding of various modalities, equipping it to handle a wide range of retrieval tasks.
4 - Evaluation and Results
4.1 - Quantitative Results
Marengo-2.6 model has been evaluated against a range of state-of-the-art foundation models from diverse modalities. Quantitative results show its superior performance in various text-to-any retrieval tasks.
The model sets new state-of-the-art performance records across all text-to-any retrieval datasets, surpassing existing models by a considerable margin. We plan to release broader benchmark results for general embedding-based tasks soon.
Baseline Models
Data Filtering Network-H/14-378 (Fang et al, Apple & University of Washington, 2023.09): This open-source image foundation model is based on the CLIP training objective. It was trained on 5 billion image-text pairs with a 378x378 image resolution.
LanguageBind-H (Zhu et al, Peking University, 2024.02): This open-source video foundation model processes both audio and visual information and was reportedly trained on 10 million video-text pairs (VIDAL-10m dataset).
VideoPrism-G (Zhao et al, Google, 2024.02): This video foundation model processes visual information and was reportedly trained on 618 million video-text pairs.
(Commercial) Google Gemini(GenAI) Multimodal Embedding API
Zero-shot Video Retrieval (ZS-T2V):
Marengo-2.6 has set a new state-of-the-art on MSR-VTT and ActivityNet datasets, with average recall improvements of +4% on MSR-VTT and +2.9% on ActivityNet compared to the previous best models. (Average recall is calculated as the mean of Recall@1 and Recall@5)
Zero-shot Image Retrieval (ZS-T2I):
The model also establishes the new state-of-the-art performance on the MS-COCO and Flickr30k datasets. Remarkably, it surpasses the previous state-of-the-art image foundation model, which was exclusively trained on a large corpus of image data. This suggests that Marengo-2.6 is capable of learning spatial visual cues effectively through a large video corpus. (Average recall is calculated as the mean of Recall@1 and Recall@5)
Zero-shot Audio Retrieval (ZS-T2A):
Lastly, the model sets the new state-of-the-art performance on Clotho and AudioCaps datasets by learning auditory cues from videos. However, compared to the visual retrieval benchmark, the absolute performance is lower. This discrepancy highlights an area for potential improvement in future model iterations. (Average recall is calculated as the mean of Recall@1 and Recall@10)
These results not only validate the effectiveness of our model's architecture and training but also underscore its potential to accelerate the advancement in the field of multimodal data retrieval and understanding.
4.2 - Qualitative Retrieval Results
Text-To-Video (T2V)
Query: Number 3 Seattle Seahawks avoids sack, throws to Number 83 David Moore in end zone for touchdown.
Top-3 Results:
Text-To-Image (T2I)
Query: A child holding a flowered umbrella and petting a yak.
Top-3 Results:
Query: Two giraffe standing next to each other on a grassy field.
Top-3 Results:
Text-To-Audio (T2A)
Query: After blustering loudly, the wind eventually dies down.
Top-3 Results:
Query: A group of kids are playing together and cheer.
Top-3 Results:
Audio-To-Video (A2V)
Query (Subway Sound)
Top-3 Results (Audio is not used):
Query (Sound of Sheep)
Top-3 Results (Audio is not used):
Image-To-Video (I2V)
Query (Image):
Top-3 Results:
Query (Image):
Top-3 Results:
Video-To-Video (V2V)
Query:
Top-3 Results:
Query:
Top-3 Results:
Closing Remarks
Twelve Labs is proud to introduce Marengo-2.6. Our video foundation model offers a pioneering approach to multimodal representations tasks not just to video but also image and audio. It is a meaningful first step towards achieving our mission of making videos just as easy as text.
In the upcoming week of March 2024, we will make Marengo-2.6 available on our Playground and API environments. This will provide users with the opportunity to interact with the model firsthand, experiencing its capabilities and integrating its state-of-the-art performance into their own applications and workflows.
Our team is committed to continuous improvement and transparency in the performance of our models. To that end, we will soon release a broader benchmark that compares Marengo-2.6 against other embedding tasks. This will offer a more comprehensive view of the model's performance and its standing in the field.
We are a group of friendly, curious, and passionate people from all walks of life with a vision of driving the technological singularity for the betterment of humanity.
More coming soon.
Acknowledgement - Twelve Labs Team:
This is a joint team effort across multiple functional groups including model and data (”core” indicates Core Contributor), engineering, product and business development. (First-name alphabetical order)
Model: Aiden Lee, Cooper Han, Flynn Jang, Jae Lee, Jay Yi, Jeff Kim (core), Jeremy Kim, Kyle Park, Lucas Lee, Mars Ha (core), Minjoon Seo, Ray Jung, William Go
Data: Daniel Kim (core), Jay Suh (core)
Deployment: Abraham Jo, Ed Park, Hassan Kianinejad, SJ Kim, Tony Moon, Wade Jeong
Product: Andrei Popescu, Esther Kim, EK Yoon, Genie Heo, Henry Choi, Jenna Kang, Kevin Han, Noah Seo, Sunny Nguyen, Ryan Won, Yeonhoo Park
Business & Operations: Anthony Giuliani, Dave Chung, Hans Yoon, James Le, Jenny Ahn, June Lee, Maninder Saini, Meredith Sanders, Soyoung Lee, Sue Kim, Travis Couture
Resources:
Link to sign up and play with our API (Marengo-2.6 will be available in our Playground in the upcoming week of March)
Link to the API documentation
Link to our Discord community to connect with fellow users and developers
If you use this model in your work, please use the following BibTeX citation and cite the author as Twelve Labs:
1 - Bullet Point Summary
Introduction to Marengo-2.6: A new state-of-the-art (SOTA) multimodal foundation model capable of performing any-to-any search tasks, including Text-To-Video, Text-To-Image, Text-To-Audio, Audio-To-Video, Image-To-Video, and more. This model represents a significant leap in video understanding technology, enabling more intuitive and comprehensive search capabilities across various media types.
New State-of-the-Art Performance: Marengo-2.6 sets new benchmarks in zero-shot text-to-video, text-to-image, and text-to-audio retrieval tasks with a single embedding model. It outperforms Google's VideoPrism-G model by +10% on the MSR-VTT dataset and +3% on the ActivityNet dataset. Additionally, it surpasses the state-of-the-art image foundation model in zero-shot text-to-image retrieval tasks, showcasing its ability to understand and process visual content The results bolster the efficacy of our video-first research ethos. An AI system that learns from video can exhibit impressive perceptual reasoning abilities across multiple modalities.
Expanded Multimodal Capabilities: The model's expanded capabilities allow for any-to-any (cross-modality) retrieval tasks, making it a versatile tool for a wide range of applications. This includes text-to-video, text-to-image, text-to-audio, audio-to-video, and image-to-video tasks, bridging different media types.
Enhanced Temporal Localization: The model introduces a Reranker model for better temporal localization. This enhancement allows for more precise search results.
2 - The Rise of Video Foundation Models
Video data is inherently redundant, high-dimensional, and temporally structured, closely resembling sensory data but difficult to parse and interpret. Traditional models often struggle to capture the nuanced interplay between frames, missing out on the rich contextual cues that give video its meaning.
The journey towards effective video understanding has seen significant advancements in multimodal embedding models. The understanding that human perception is inherently multimodal has led to the development of models capable of processing and integrating multiple types of data.
By integrating visual, textual, and auditory information, multimodal embedding models learn much more robust representations of the world. Marengo-2.6 is the culmination of our efforts, offering unparalleled capabilities in video understanding and any-to-any retrieval tasks.
3 - Marengo 2.6 Model Overview
3.1 - Architecture: Gated Modality Experts
Marengo-2.6's architecture, as shown in the visual diagram above, is based on the concept of "Gated Modality Experts". This allows for the processing of multimodal inputs through specialized encoders before combining them into a comprehensive multimodal representation.
The architecture consists of several key components:
The Visual Expert processes visual information to capture appearance, motion, and temporal changes within the video.
The Audio Expert processes auditory information to capture both verbal and non-verbal audio signals related to the video.
The Gated Fusion Module assesses the contribution of each expert for videos, and merges them into a unified multimodal representation for any-to-any retrieval tasks.
3.2 - Training and Data
Training for Marengo-2.6 focuses on self-supervised learning with contrastive loss on a comprehensive multimodal dataset. As we mentioned in our previous blog, we've curated and augmented a dataset that's beneficial for training the model. It contains:
Video Data: 60 million videos, with both visual and auditory information extracted
Image Data: 500 million images
Audio Data: 500k sounds, including both general non-verbal sounds and music
This diverse, large-scale dataset has allowed Marengo-2.6 to gain a deep understanding of various modalities, equipping it to handle a wide range of retrieval tasks.
4 - Evaluation and Results
4.1 - Quantitative Results
Marengo-2.6 model has been evaluated against a range of state-of-the-art foundation models from diverse modalities. Quantitative results show its superior performance in various text-to-any retrieval tasks.
The model sets new state-of-the-art performance records across all text-to-any retrieval datasets, surpassing existing models by a considerable margin. We plan to release broader benchmark results for general embedding-based tasks soon.
Baseline Models
Data Filtering Network-H/14-378 (Fang et al, Apple & University of Washington, 2023.09): This open-source image foundation model is based on the CLIP training objective. It was trained on 5 billion image-text pairs with a 378x378 image resolution.
LanguageBind-H (Zhu et al, Peking University, 2024.02): This open-source video foundation model processes both audio and visual information and was reportedly trained on 10 million video-text pairs (VIDAL-10m dataset).
VideoPrism-G (Zhao et al, Google, 2024.02): This video foundation model processes visual information and was reportedly trained on 618 million video-text pairs.
(Commercial) Google Gemini(GenAI) Multimodal Embedding API
Zero-shot Video Retrieval (ZS-T2V):
Marengo-2.6 has set a new state-of-the-art on MSR-VTT and ActivityNet datasets, with average recall improvements of +4% on MSR-VTT and +2.9% on ActivityNet compared to the previous best models. (Average recall is calculated as the mean of Recall@1 and Recall@5)
Zero-shot Image Retrieval (ZS-T2I):
The model also establishes the new state-of-the-art performance on the MS-COCO and Flickr30k datasets. Remarkably, it surpasses the previous state-of-the-art image foundation model, which was exclusively trained on a large corpus of image data. This suggests that Marengo-2.6 is capable of learning spatial visual cues effectively through a large video corpus. (Average recall is calculated as the mean of Recall@1 and Recall@5)
Zero-shot Audio Retrieval (ZS-T2A):
Lastly, the model sets the new state-of-the-art performance on Clotho and AudioCaps datasets by learning auditory cues from videos. However, compared to the visual retrieval benchmark, the absolute performance is lower. This discrepancy highlights an area for potential improvement in future model iterations. (Average recall is calculated as the mean of Recall@1 and Recall@10)
These results not only validate the effectiveness of our model's architecture and training but also underscore its potential to accelerate the advancement in the field of multimodal data retrieval and understanding.
4.2 - Qualitative Retrieval Results
Text-To-Video (T2V)
Query: Number 3 Seattle Seahawks avoids sack, throws to Number 83 David Moore in end zone for touchdown.
Top-3 Results:
Text-To-Image (T2I)
Query: A child holding a flowered umbrella and petting a yak.
Top-3 Results:
Query: Two giraffe standing next to each other on a grassy field.
Top-3 Results:
Text-To-Audio (T2A)
Query: After blustering loudly, the wind eventually dies down.
Top-3 Results:
Query: A group of kids are playing together and cheer.
Top-3 Results:
Audio-To-Video (A2V)
Query (Subway Sound)
Top-3 Results (Audio is not used):
Query (Sound of Sheep)
Top-3 Results (Audio is not used):
Image-To-Video (I2V)
Query (Image):
Top-3 Results:
Query (Image):
Top-3 Results:
Video-To-Video (V2V)
Query:
Top-3 Results:
Query:
Top-3 Results:
Closing Remarks
Twelve Labs is proud to introduce Marengo-2.6. Our video foundation model offers a pioneering approach to multimodal representations tasks not just to video but also image and audio. It is a meaningful first step towards achieving our mission of making videos just as easy as text.
In the upcoming week of March 2024, we will make Marengo-2.6 available on our Playground and API environments. This will provide users with the opportunity to interact with the model firsthand, experiencing its capabilities and integrating its state-of-the-art performance into their own applications and workflows.
Our team is committed to continuous improvement and transparency in the performance of our models. To that end, we will soon release a broader benchmark that compares Marengo-2.6 against other embedding tasks. This will offer a more comprehensive view of the model's performance and its standing in the field.
We are a group of friendly, curious, and passionate people from all walks of life with a vision of driving the technological singularity for the betterment of humanity.
More coming soon.
Acknowledgement - Twelve Labs Team:
This is a joint team effort across multiple functional groups including model and data (”core” indicates Core Contributor), engineering, product and business development. (First-name alphabetical order)
Model: Aiden Lee, Cooper Han, Flynn Jang, Jae Lee, Jay Yi, Jeff Kim (core), Jeremy Kim, Kyle Park, Lucas Lee, Mars Ha (core), Minjoon Seo, Ray Jung, William Go
Data: Daniel Kim (core), Jay Suh (core)
Deployment: Abraham Jo, Ed Park, Hassan Kianinejad, SJ Kim, Tony Moon, Wade Jeong
Product: Andrei Popescu, Esther Kim, EK Yoon, Genie Heo, Henry Choi, Jenna Kang, Kevin Han, Noah Seo, Sunny Nguyen, Ryan Won, Yeonhoo Park
Business & Operations: Anthony Giuliani, Dave Chung, Hans Yoon, James Le, Jenny Ahn, June Lee, Maninder Saini, Meredith Sanders, Soyoung Lee, Sue Kim, Travis Couture
Resources:
Link to sign up and play with our API (Marengo-2.6 will be available in our Playground in the upcoming week of March)
Link to the API documentation
Link to our Discord community to connect with fellow users and developers
If you use this model in your work, please use the following BibTeX citation and cite the author as Twelve Labs:
Related articles








© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved
© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved
© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved