
WHAT OUR PARTNERS ARE SAYING
Video Intelligence is Going Agentic

James Le
The emergence of video foundation models has evolved our capabilities from simple frame-by-frame video analysis to sophisticated spatial understanding and temporal reasoning. However, a critical gap remains between raw model capabilities and real-world applications. This is where agentic video intelligence enters the picture—representing a paradigm shift from passive analysis to active, goal-oriented interaction with video content. Let's dive in!
The emergence of video foundation models has evolved our capabilities from simple frame-by-frame video analysis to sophisticated spatial understanding and temporal reasoning. However, a critical gap remains between raw model capabilities and real-world applications. This is where agentic video intelligence enters the picture—representing a paradigm shift from passive analysis to active, goal-oriented interaction with video content. Let's dive in!

In this article
No headings found on page
Join our newsletter
Join our newsletter
Receive the latest advancements, tutorials, and industry insights in video understanding
Receive the latest advancements, tutorials, and industry insights in video understanding
Search, analyze, and explore your videos with AI.
Apr 4, 2025
30 Min Read
Copy link to article
TLDR: The Rise of Agentic Video Intelligence
We are witnessing a seismic shift: video AI is evolving from a basic analysis tool into an intelligent collaborator that can understand context, reason about content, and execute complex creative tasks.
TwelveLabs' Jockey isn't just another AI tool—it's a sophisticated orchestrator that conducts our video-native foundation models like a symphony, turning chaotic video workflows into harmonious creative processes.
Forget clunky video interfaces: these new video agents speak your language while letting you get hands-on with the visuals, finally bridging the gap between human creativity and machine efficiency.
The days of wrestling with technical video tools are numbered—imagine telling your AI assistant
Find the most compelling customer storiesand watching it assemble a perfect highlight reel.For enterprises drowning in video content, this isn't just an upgrade—it's a revolution that transforms overwhelming media libraries into accessible, actionable assets through natural conversation.
You can listen to this article via this NotebookLM-generated conversation here: https://soundcloud.com/james-le-56344460/agentic-video-intelligence
1 - Introduction: The Video Intelligence Evolution
In 2025, we stand at the precipice of a fundamental shift in how machines understand and manipulate visual media. With billion hours of video content uploaded daily across platforms, traditional processing tools—designed for an era of limited content and predefined tasks—are becoming obsolete. This explosion of content has created both unprecedented opportunities and formidable challenges.
The emergence of video foundation models has evolved our capabilities from simple frame-by-frame video analysis to sophisticated spatial understanding and temporal reasoning. However, a critical gap remains between raw model capabilities and real-world applications. This is where agentic video intelligence enters the picture—representing a paradigm shift from passive analysis to active, goal-oriented interaction with video content. These systems combine video foundation models with large language models through agent planning frameworks - creating AI systems that understand not just what appears in a video, but why it matters and what actions to take.
At TwelveLabs, we're addressing these challenges through Jockey—a conversational video agent that combines video foundation models with LLM-based reasoning through a purpose-built agent architecture. In this article, we'll explore how video intelligence is becoming increasingly agentic by way of examining technical innovations from both engineering and design perspectives. From media production to sports highlight generation, this shift enables entirely new approaches to content creation and analysis that weren't previously possible. For organizations building the next generation of video applications, this represents a transformative opportunity to combine human creativity with machine efficiency. The revolution in video intelligence isn't just coming—it's already here. And it's agentic.
2 - The Rise of AI Agents in the LLM Domain
The emergence of Large Language Models (LLMs) has revolutionized AI by enabling autonomous agents that can understand, plan, and act. These LLM-powered agents use natural language as their interface, allowing them to comprehend goals and execute complex tasks through sophisticated reasoning and tool integration. This capability evolved from basic prompt engineering into more advanced approaches that leverage chain-of-thought prompting, enabling agents to break down complex problems step-by-step.

Source: https://www.letta.com/blog/ai-agents-stack
Advanced agent frameworks like Open AI Agents SDK, Letta, and LangGraph have emerged as critical infrastructure, providing structured approaches for building reliable agents. These frameworks implement essential capabilities including planning, tool integration, memory management, and self-reflection. Modern agent architectures separate cognitive functions into specialized components - planners for strategy, executors for actions, and critics for evaluation - enabling them to handle increasingly complex tasks.
In real-world applications, LLM agents have proven highly adaptable. They can perform diverse tasks from software development and customer service to research synthesis - all by combining LLMs' reasoning capabilities with domain-specific tools and workflows. This architecture allows them to navigate complex problem spaces more flexibly than traditional automation while providing greater reliability than raw LLM outputs.

Source: https://weaviate.io/blog/what-are-agentic-workflows#planning-pattern
The field has identified several key design patterns that drive agent success. These include task decomposition (breaking goals into manageable steps), recursive reasoning (applying logic to intermediate results), tool augmentation (expanding capabilities through APIs), and human-in-the-loop collaboration (incorporating user feedback). These patterns work across different domains, establishing core principles for effective agent design.
These insights from LLM agent development provide crucial guidance for video intelligence systems. They show that foundation models work best within structured architectures that align with specific task requirements. They emphasize the importance of explicit planning and reflection for reliability. Most critically, they demonstrate that the most effective systems balance automation with human collaboration, creating true partnerships that leverage both machine and human intelligence. As we develop video agents, these principles will help us navigate the unique challenges of understanding and manipulating visual media.
3 - The Emergence of Video Agents: A New Paradigm
The convergence of video foundation models and LLM-based agent architectures has given rise to video agents—systems uniquely designed to understand, manipulate, and reason about visual media with unprecedented sophistication. Unlike their predecessors, these agents don't merely analyze video content; they interact with it purposefully, leveraging specialized knowledge about visual narratives, temporal relationships, and multimodal context. This new paradigm addresses fundamental limitations of both traditional video processing pipelines, which lack semantic understanding, and general-purpose AI agents, which struggle with the complex temporal and spatial dimensions inherent to video content.
What makes video agents distinct is their ability to navigate the unique challenges of video intelligence. Video data exists in a high-dimensional space combining visual, audio, and temporal elements, requiring specialized perception capabilities beyond those needed for text or static images. Computational demands scale dramatically with video length and resolution, necessitating efficient approaches to attention and memory. Perhaps most significantly, video understanding requires reasoning across multiple timescales simultaneously—from frame-level details to scene-level composition to narrative-level structure—a capability rarely needed in other domains. A system like OmAgent has pioneered a solution to these challenges through an innovative architecture combining multimodal RAG with a divide-and-conquer reasoning approach.
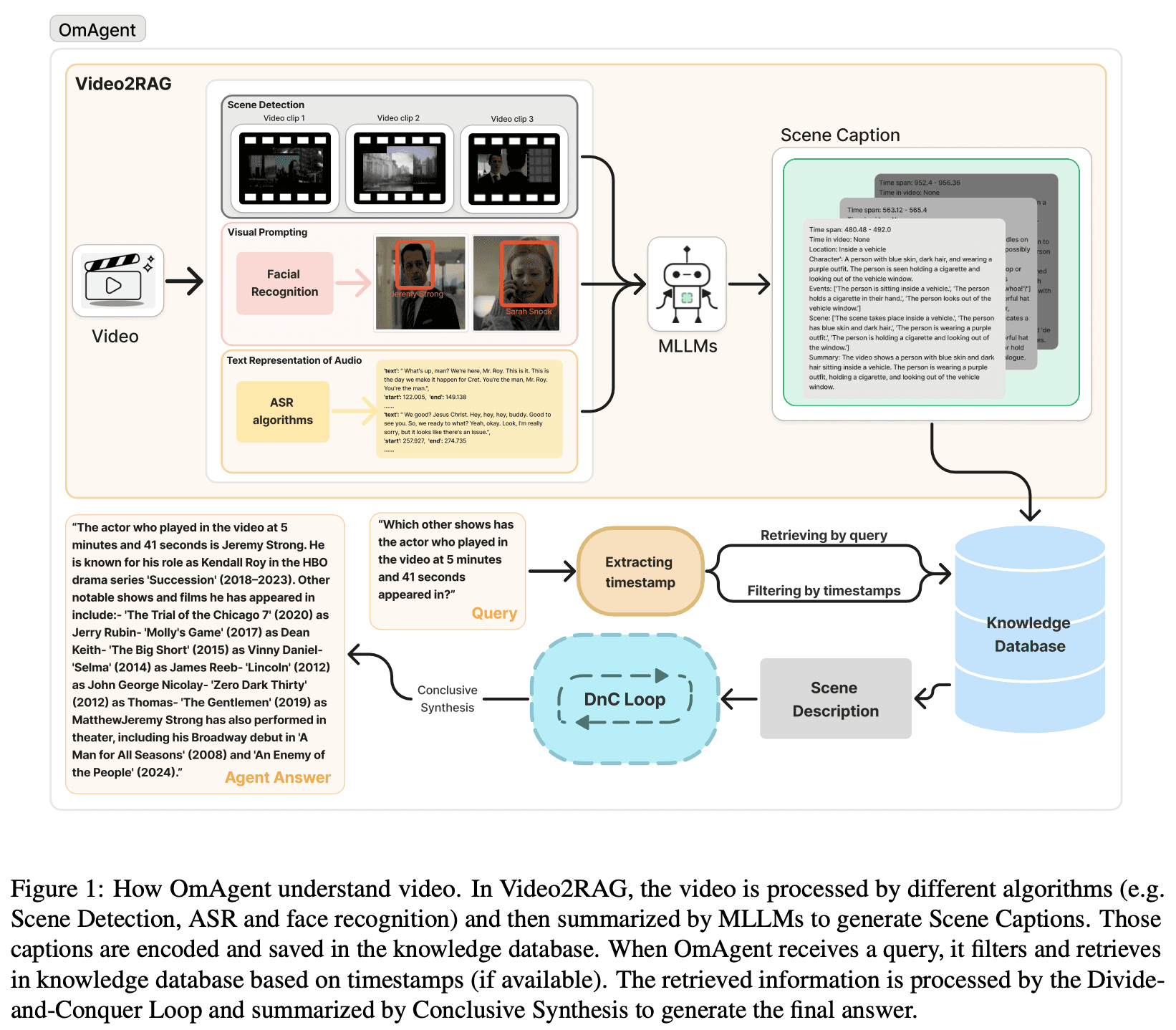
Source: https://www.om-agent.com/
Recent academic work has accelerated this shift, with researchers increasingly focusing on agentic frameworks for video understanding. Papers like "VideoAgent: A Memory-augmented Multimodal Agent for Video Understanding" from Peking University demonstrate how memory mechanisms can enhance temporal reasoning, while Stanford's research on "VideoAgent: Long-form Video Understanding with Large Language Model as Agent" explores efficient searching and aggregation of relevant information from lengthy videos. These approaches share a common insight: rather than processing all video content exhaustively, effective agents should reason about what's important, selectively attend to relevant segments, and dynamically build understanding through iterative analysis.

Source: https://wxh1996.github.io/VideoAgent-Website/
There are also works such as LAVE that combines LLM reasoning with video-specific tools. These systems typically structure their workflow around specialized components: perception systems for extracting multimodal features, memory mechanisms for storing and retrieving video context, planning modules for decomposing complex queries, and execution components for interfacing with video processing tools. This modularity allows them to combine the strengths of foundation models with domain-specific knowledge about video content and editing operations.
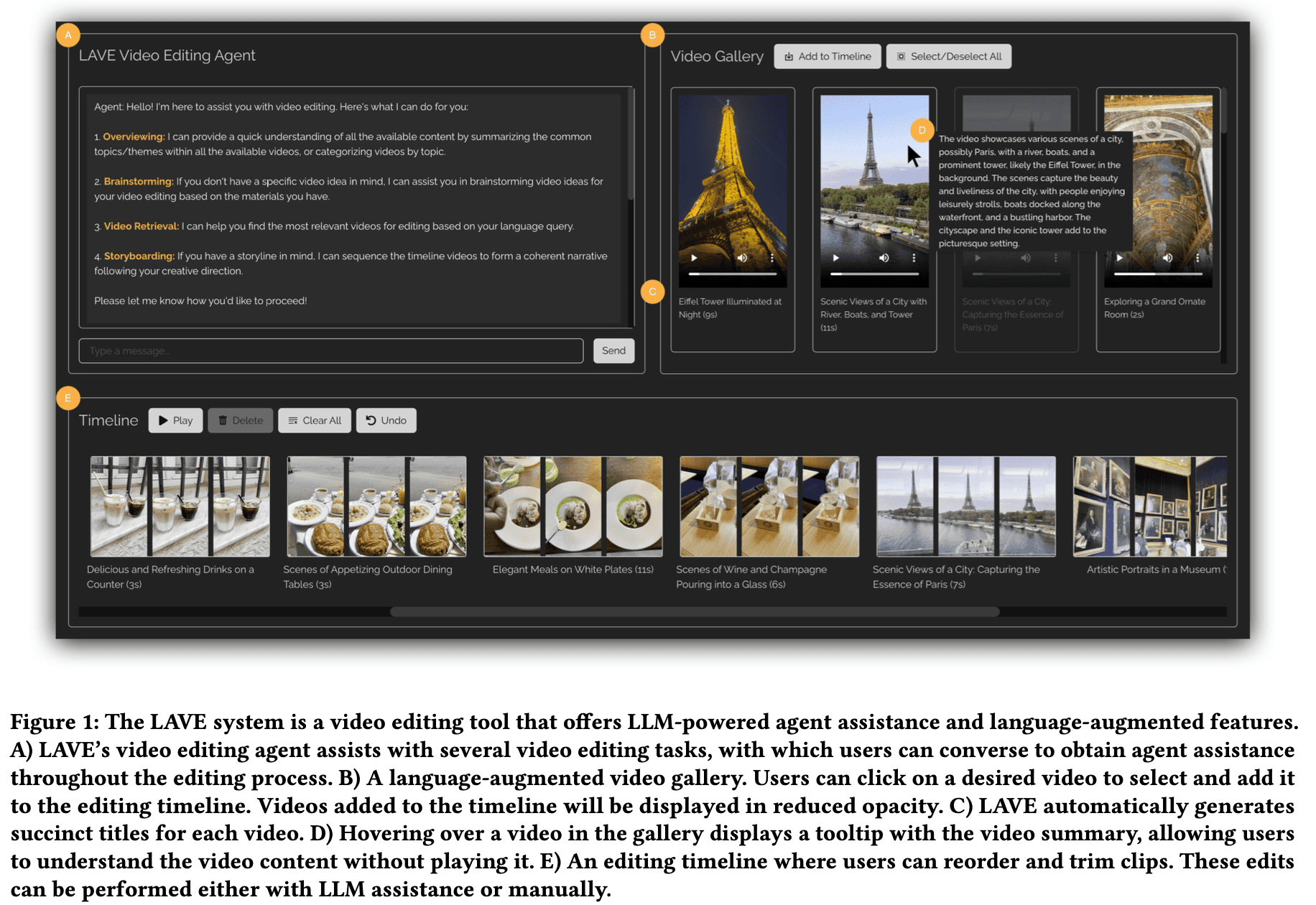
Source: https://arxiv.org/abs/2402.10294
As video agents evolve from research prototypes to production systems, they are increasingly addressing real-world challenges in content creation, media analysis, and information retrieval. Early adopters in broadcasting, film production, and social media are already leveraging these capabilities to automate previously manual tasks like highlight generation, content moderation, and promotional clip creation. The most advanced systems demonstrate an emerging ability to understand not just the surface content of videos, but their underlying purpose, style, and narrative structure—enabling interactions that feel more like collaborating with a knowledgeable assistant than operating a complex tool. This transition from passive analysis to active collaboration represents perhaps the most significant paradigm shift in video intelligence since the advent of multimodal AI.
4 - TwelveLabs Approach: Jockey as a Video Agent Framework
Incubated since last year, Jockey represents a significant evolution in video intelligence - built on the foundation of TwelveLabs' core video foundation models while adding a crucial orchestration layer to address the complexity gap. At its heart, Jockey leverages our two powerful video-native models: Marengo 2.7 for semantic video search and Pegasus 1.2 for advanced video-to-text understanding. Rather than replacing these models, Jockey strategically coordinates them through a planner-worker-reflector architecture that distributes cognitive tasks according to each component's strengths—using an LLM for planning and reasoning while delegating perception-intensive operations to specialized video models.

This architecture solves a fundamental challenge in video intelligence: while foundation models excel at perception and reasoning tasks, they often struggle with complex workflow sequencing. Jockey's multi-agent approach addresses this limitation by implementing a planner that creates detailed execution sequences, specialized workers that interface directly with video APIs, and a reflector that summarizes action steps. This separation of concerns allows each component to focus on what it does best—the LLMs handles reasoning and natural language understanding, while video foundation models manage the complex multimodal analysis.
What makes Jockey particularly powerful is its ability to maintain context across complex multi-step workflows. For video highlight generation, for instance, Jockey doesn't just execute a single search operation; it sequences searches with precise criteria, combines result sets intelligently, and applies post-processing operations that reflect the user's actual intent. The system maintains persistent state through a graph-based framework built on LangGraph, allowing it to track clips across multiple operations and maintain awareness of the overall task objective even as it executes granular subtasks.

Source: https://github.com/twelvelabs-io/tl-jockey/blob/main/jockey/stirrups/stirrup.py
The design of Jockey prioritizes adaptability—an essential quality for production deployments. Its modular architecture allows customization at multiple levels, from prompt-driven behavior adjustments to the addition of entirely new worker modules. This enables developers to extend Jockey's capabilities for specific workflows while maintaining the reliability of the core system.
5 - Bringing Transparency to Jockey
Creating an effective video agent presents unique engineering challenges specific to video manipulation that extend beyond typical LLM applications. The most notable challenge involves performance optimization in video processing pipelines, particularly for complex operations like clip extraction and combination. The approach we have taken is two-fold:
First, designing asynchronous processing pipelines using function dispatchers that handle discrete steps like
base_search(),process_clips(), anddownload_remaining()independently.Second, exposing these processing stages to users through transparent "thinking" states shown in the interface (more in Section 6).
This transparency isn't just about status updates—it builds essential trust by revealing how the system reaches its conclusions, showing which processing components are being leveraged at each moment.

Throughout Jockey's development, we have found that users develop stronger trust in systems that explain their reasoning, even when this slightly increases response time. This insight has fundamentally shaped our UI design, which explicitly displays processing states and the specific model components—whether Marengo's search capabilities or Pegasus's contextual understanding—being applied to each query. This transparency becomes particularly important when working with enterprise clients who need verifiable processes rather than black-box solutions.
Jockey’s future extension will be a bidirectional thinking system, which not only displays the agent's processing steps but also allows users to modify these steps directly. This capability transforms Jockey from a passive tool into a collaborative partner where users can interactively refine queries (changing chameleons in Japan to lizards in Japan), validate processing decisions, or redirect the agent's focus—essentially "steering" the AI rather than merely accepting its outputs. This approach aligns with findings from our work with the MLSE team and other enterprise customers, who consistently prioritize understanding and control over pure automation speed, particularly when dealing with high-value creative assets like video content.

Source: https://www.latent.space/p/why-mcp-won
The Model Context Protocol (MCP) framework offers intriguing possibilities for Jockey's future evolution, particularly as we expand into third-party integrations. MCP could provide a standardized integration layer between Jockey's core components and external services like video generation tools (RunwayML, Luma Labs), audio generation software (ElevenLabs, Suno), and advanced video operations tasks like scene segmentation and object tracking (Meta's SAM).
Rather than building custom connectors for each integration, MCP would enable us to define a consistent interface for tool invocation, context sharing, and response handling. This approach would transform an n×m integration problem (n agent frameworks × m tools) into a more manageable n+m problem, dramatically reducing implementation complexity while increasing system extensibility.
For Jockey specifically, MCP could enable more sophisticated workflows where, for instance, clips identified through Marengo could be seamlessly passed to external enhancement tools, then to generative audio services for voiceover, and finally to editing systems—all while maintaining coherent context throughout the entire process.
6 - The Power of Multimodal Interfaces
Traditional video interfaces have typically forced users to choose between text-based search that ignores visual context and video players with minimal interactive capabilities. Jockey reimagines this relationship through a fundamentally multimodal interface that combines conversational interaction with video-native elements, treating both modalities as first-class citizens rather than forcing one to accommodate the other. The interface shown in the screenshot below demonstrates this approach: a conversational area captures user intent through natural language, a visual thinking display reveals the agent's reasoning process, and a video gallery presents results with relevant context like timestamps and descriptions. This unified experience allows users to seamlessly transition between expressing high-level goals (find inspiring stories of people overcoming obstacles) and interacting directly with visual results.
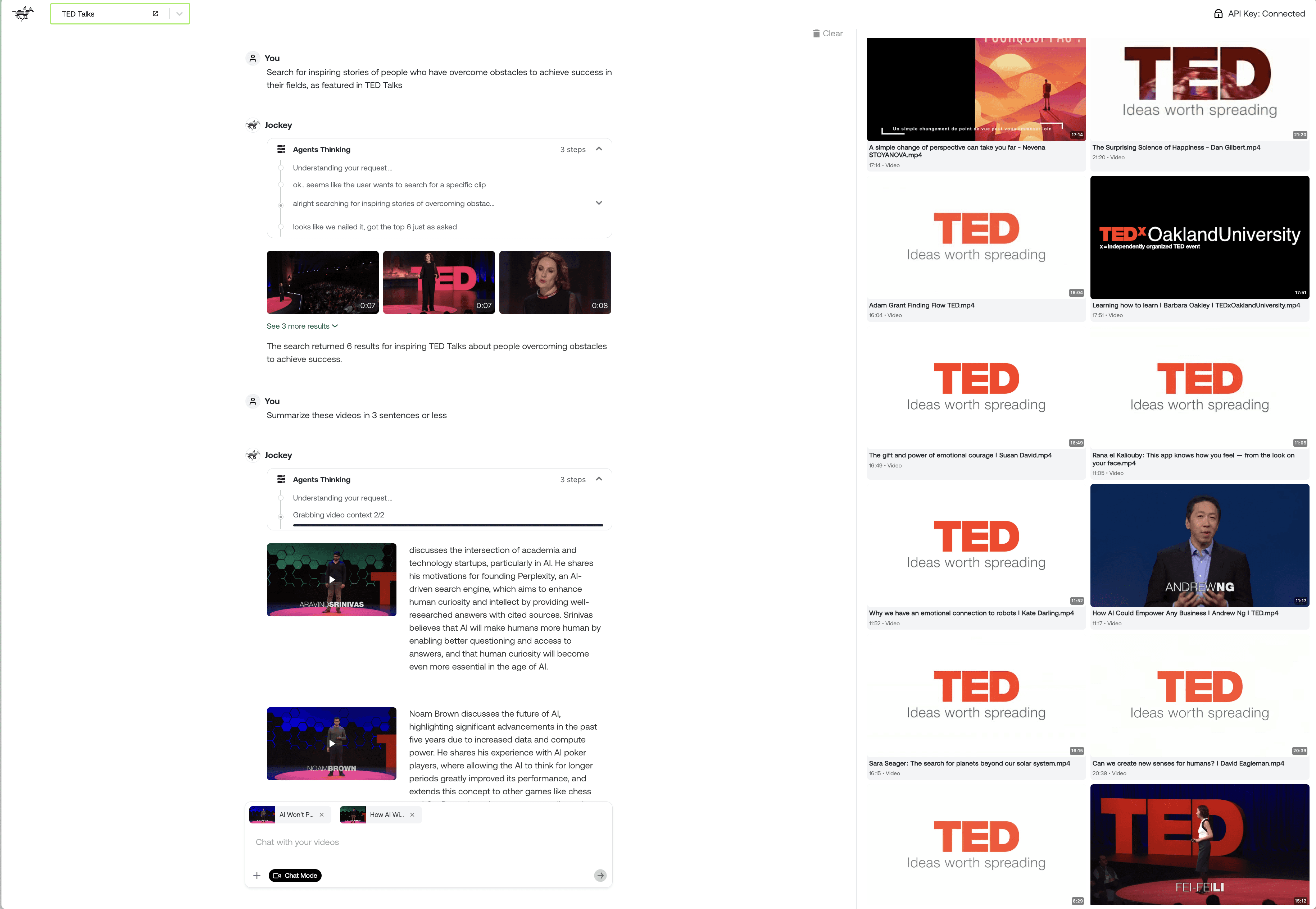
What makes this approach powerful is the bidirectional flow of information between textual and visual elements. When a user issues a natural language query, Jockey provides responses that include both text explanations and direct links to relevant video segments, with precise timestamps marking where specific concepts appear in the footage. This temporal anchoring creates a clear bridge between Jockey's text responses and the actual video content being referenced.
Additionally, users can directly interact with the video segments through thumbnails, thereby enhancing the navigation experience. This creates a virtuous cycle where each modality enhances the other: language provides precision in specifying intent, while visual elements provide richness and context that would be inefficient to communicate textually. For instance, the screenshot below shows how Jockey displays agent thinking steps alongside timestamped video segments, helping users understand not just what content was found but why it was selected.
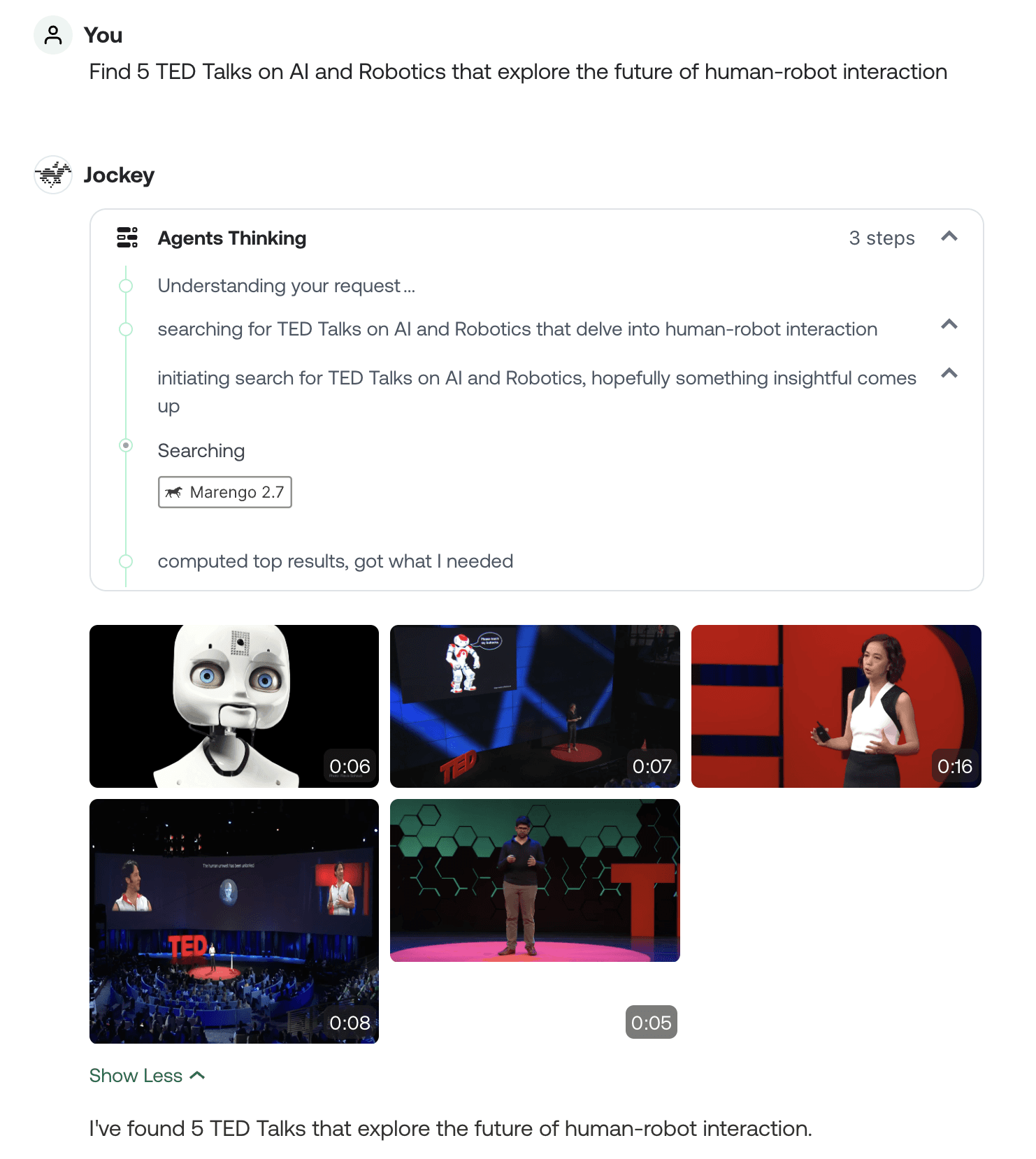
The interface addresses several cognitive challenges unique to video interaction. Video content is inherently temporal and dense with information, making it difficult to scan, browse, or compare in the way users can with text. Jockey's multimodal approach mitigates these challenges by providing multiple points of entry: users can browse visually through thumbnails, scan through agent-generated summaries, or jump directly to specific moments based on conceptual descriptions. By combining these approaches, the interface substantially reduces cognitive load, allowing users to maintain context when working with multiple videos simultaneously—as seen in the screenshot below where the user asks to Summarize these videos in an emotional tone after reviewing search results.

Perhaps most significantly, the interface evolves beyond simple query-response patterns into a true collaborative workspace. The agent thinking display shown in the screenshot below reveals how Jockey breaks down complex tasks into discrete steps like Understanding your request and Grabbing video context - creating transparency that builds user trust and allows for timely intervention. This transparency extends to displaying both the algorithmic confidence (via numbered steps) and thinking process, helping users calibrate their reliance on the system and make informed decisions about where human judgment might be needed. When combined with the ability to interrupt, redirect, or refine the agent's approach at any point in the workflow, this creates a genuinely collaborative relationship rather than the transactional model typical of traditional video interfaces.

The future evolution of this multimodal approach points toward what we call "flow-aware trajectories"—interfaces that anticipate the user's next likely actions based on emerging patterns in their workflow (more in Section 8). As shown in the agent's progressive reasoning in the screenshot above, Jockey already demonstrates early capabilities in this direction by maintaining context across conversation turns and building on previous interactions. As these capabilities mature, the interface will increasingly blur the line between agent and tool, becoming an extension of the user's creative process that anticipates needs, suggests alternative approaches, and handles technical details without breaking the user's creative flow. This represents a fundamental shift from interfaces that merely process requests to true collaborators that actively contribute to the creative and analytical process.
7 - Transforming Content Creation: Jockey's Vision for Enterprise Media Workflows
The enterprise media landscape is experiencing unprecedented challenges with content demands increasing exponentially while production resources remain constrained. Marketing teams must produce more video content across multiple platforms, each with different format requirements and audience expectations. Documentary filmmakers need to identify relevant moments from hundreds of hours of footage. Corporate communication departments struggle to maintain consistent messaging across global markets. These workflows share common pain points: they're time-intensive, require specialized skills, and don't scale effectively with traditional approaches.
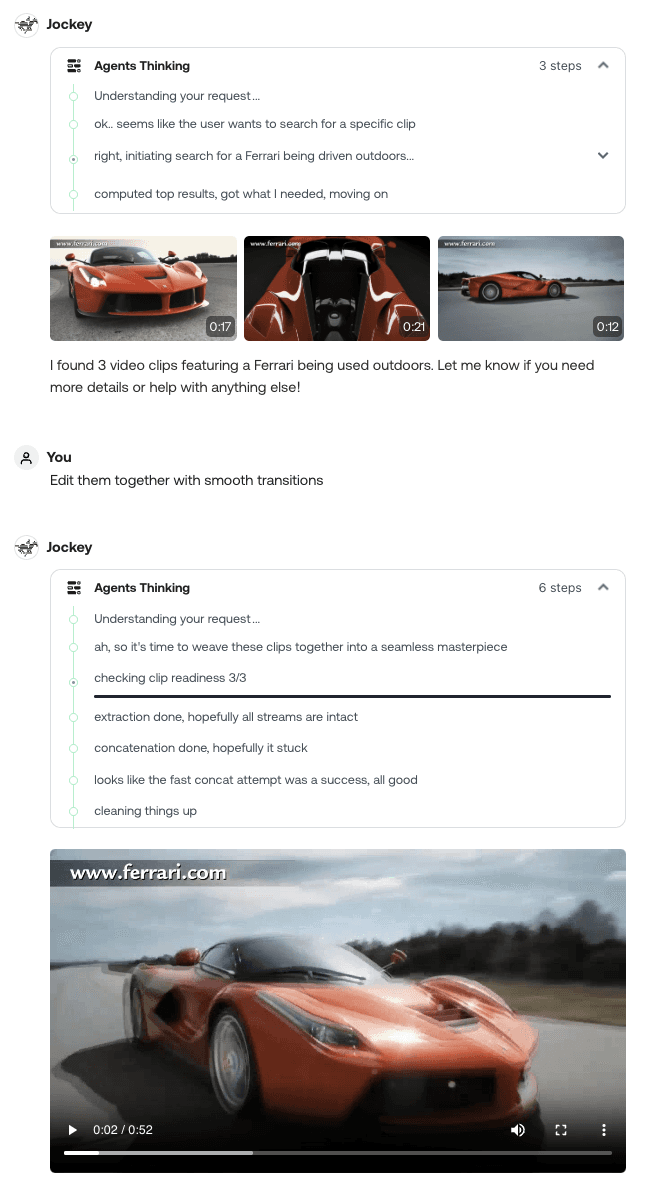
Jockey's vision addresses these challenges by reimagining how enterprises interact with video content. Rather than simply automating existing processes, Jockey creates new possibilities for content workflows through its conversational interface and intelligent orchestration of video understanding capabilities. For example, a marketing team creating product demonstrations can instruct Jockey to find clips showing the product being used outdoors and then edit them together with smooth transitions. This natural language approach eliminates the technical barriers that typically slow production, allowing teams to focus on creative decisions rather than mechanical execution.
One particularly compelling application is in advertising and marketing workflows, where Jockey demonstrates immediate value. Creative teams often spend countless hours reviewing raw footage to identify moments that align with brand messaging or campaign themes. Jockey transforms this process by enabling teams to search video libraries using natural language queries like find clips where people express excitement after using our product or identify scenes with our logo prominently displayed in urban environments.The agent leverages Marengo's multimodal understanding to retrieve relevant footage and Pegasus's contextual awareness to assemble these moments into cohesive sequences, dramatically reducing the time from concept to finished asset.

The true power of Jockey's approach becomes evident in end-to-end creative workflows. Consider a corporate communications team tasked with creating product announcement videos. Traditionally, this requires storyboarding, filming, cataloging footage, editing rough cuts, adding graphics, recording voiceovers, and finalizing for distribution—each step involving different specialists and tools. The vision of Jockey is to consolidate these workflows by allowing teams to retrieve relevant footage, assemble initial cuts, generate accompanying audio, and prepare distribution-ready assets through natural language instructions. While still in its early stages, Jockey's development roadmap includes expanding these capabilities through third-party integrations with relevant tools —thereby creating a comprehensive platform that adapts to enterprise requirements rather than forcing organizations to adapt their workflows to technical limitations.
8 - The Future of Video Agents: Our Vision and Roadmap
The future evolution of video agents will be guided by three core principles that extend beyond incremental improvements to fundamentally transform how humans interact with visual media. With Jockey, we're building toward a vision where video intelligence becomes a natural extension of creative and analytical workflows, anticipating needs and adapting to individual preferences while maintaining the balance between automation and human creative control.

Flow-Aware Trajectories represent our first guiding principle—systems that anticipate user needs several steps ahead to maintain creative momentum. In practice, this means Jockey will predict which clips might be needed next during highlight creation, suggest appropriate transitions based on content, and even pre-assemble rough cuts that align with a user's editing patterns. As these capabilities mature, editors will experience fewer interruptions to their creative process, with the system handling technical details while preserving creative direction. For example, a sports producer could assemble a highlights package with Jockey automatically suggesting key plays based on crowd reactions, maintaining consistent pacing, and ensuring narrative flow—all while the producer maintains creative control over the final selection.

Contextual Meta-Learning enables Jockey to evolve with each interaction, building persistent understanding of user preferences across projects and sessions. Rather than requiring explicit instruction for every operation, the system will recognize patterns in user behavior—preferred transition styles, typical scene structures, or common editing sequences—and adapt its suggestions accordingly. This creates a virtuous cycle where the system becomes more valuable over time, remembering project-specific requirements and adapting to feedback. Organizations working on recurring content types (like weekly sports highlights or product reviews) will find their workflows becoming increasingly efficient as Jockey learns to prioritize relevant content and apply consistent styling without explicit direction.

Multimodal Intelligence at Scale allows Jockey to make sophisticated connections across video, audio, and textual elements without relying on rigid rules. This principle enables complex operations like retrieving scenes based on thematic relevance rather than just visual similarity, analyzing narrative flow across multiple clips, or identifying emotionally resonant sequences automatically. As we integrate additional third-party capabilities—such as audio generation for voiceovers, video generation for alternative scenes, or avatar creation for presentations—Jockey will orchestrate these specialized tools into cohesive workflows, maintaining context across operations and ensuring consistent quality in the final output. The integration roadmap includes partnerships with leading tools for segmentation, background replacement, synthetic media generation, and audio creation, significantly expanding Jockey's capabilities without requiring users to manage complex technical integrations.
The evolution of Jockey from tool to collaborative partner represents a paradigm shift in how organizations approach video assets. By focusing on these three principles and building an extensible ecosystem of capabilities, we're creating a platform that adapts to how people naturally think about video content rather than forcing users to adapt to technical limitations. For developers building on this platform, Jockey offers the opportunity to create applications that leverage sophisticated video intelligence without the complexity of integrating disparate models. For enterprises seeking to scale visual content creation, it provides a foundation for consistent, high-quality output that respects established workflows while dramatically improving efficiency.
9 - Conclusion: Embracing the Video Agent Revolution
The convergence of video foundation models and agent architectures represents a fundamental shift in how we create, analyze, and distribute video content. Jockey demonstrates that we can move beyond treating video as a monolithic medium requiring specialized expertise toward a programmatically accessible resource that adapts to varied workflows and creative needs. Through its combination of intelligent task allocation, native video processing, and human-collaborative design, it transforms previously labor-intensive tasks into fluid, conversational interactions—dramatically reducing production time while preserving creative control.
It's important to acknowledge Jockey's current limitations as an alpha-stage proof-of-concept. The agent sometimes requires specific phrasing to achieve optimal results, occasionally struggles with complex queries, and hasn't yet been optimized for specific workflows. The agent frameworks supporting Jockey are themselves rapidly evolving, as developers across the industry experiment with different approaches to planning, memory management, and multimodal reasoning. These limitations, however, are not fundamental barriers but stepping stones on a clear development pathway toward increasingly capable and intuitive video intelligence.
We invite you to join us in shaping this future for an early access to Jockey. We are specifically looking for adventurous early adopters who are willing to test our technology and provide valuable feedback. Please register your interest using this form: https://form.typeform.com/to/JCKz0aBA
Whether you're a content creator seeking to streamline production workflows, a developer looking to integrate video intelligence into your applications, or an enterprise needing to scale video operations, your feedback and use cases will directly influence our development priorities. By participating in this private alpha, you'll not only gain hands-on experience with cutting-edge video agent technology but contribute to a broader transformation in how we work with visual media. The video agent revolution isn't just coming—it's here, and your perspective can help define its path forward.
Thanks to my TwelveLabs colleagues (Kingston Yip, Simon Shim, Simon Lecointe, Yeonhoo Park, Sean Barclay, and Sunny Nguyen) for comments, feedback, and suggestions that helped with this post.
TLDR: The Rise of Agentic Video Intelligence
We are witnessing a seismic shift: video AI is evolving from a basic analysis tool into an intelligent collaborator that can understand context, reason about content, and execute complex creative tasks.
TwelveLabs' Jockey isn't just another AI tool—it's a sophisticated orchestrator that conducts our video-native foundation models like a symphony, turning chaotic video workflows into harmonious creative processes.
Forget clunky video interfaces: these new video agents speak your language while letting you get hands-on with the visuals, finally bridging the gap between human creativity and machine efficiency.
The days of wrestling with technical video tools are numbered—imagine telling your AI assistant
Find the most compelling customer storiesand watching it assemble a perfect highlight reel.For enterprises drowning in video content, this isn't just an upgrade—it's a revolution that transforms overwhelming media libraries into accessible, actionable assets through natural conversation.
You can listen to this article via this NotebookLM-generated conversation here: https://soundcloud.com/james-le-56344460/agentic-video-intelligence
1 - Introduction: The Video Intelligence Evolution
In 2025, we stand at the precipice of a fundamental shift in how machines understand and manipulate visual media. With billion hours of video content uploaded daily across platforms, traditional processing tools—designed for an era of limited content and predefined tasks—are becoming obsolete. This explosion of content has created both unprecedented opportunities and formidable challenges.
The emergence of video foundation models has evolved our capabilities from simple frame-by-frame video analysis to sophisticated spatial understanding and temporal reasoning. However, a critical gap remains between raw model capabilities and real-world applications. This is where agentic video intelligence enters the picture—representing a paradigm shift from passive analysis to active, goal-oriented interaction with video content. These systems combine video foundation models with large language models through agent planning frameworks - creating AI systems that understand not just what appears in a video, but why it matters and what actions to take.
At TwelveLabs, we're addressing these challenges through Jockey—a conversational video agent that combines video foundation models with LLM-based reasoning through a purpose-built agent architecture. In this article, we'll explore how video intelligence is becoming increasingly agentic by way of examining technical innovations from both engineering and design perspectives. From media production to sports highlight generation, this shift enables entirely new approaches to content creation and analysis that weren't previously possible. For organizations building the next generation of video applications, this represents a transformative opportunity to combine human creativity with machine efficiency. The revolution in video intelligence isn't just coming—it's already here. And it's agentic.
2 - The Rise of AI Agents in the LLM Domain
The emergence of Large Language Models (LLMs) has revolutionized AI by enabling autonomous agents that can understand, plan, and act. These LLM-powered agents use natural language as their interface, allowing them to comprehend goals and execute complex tasks through sophisticated reasoning and tool integration. This capability evolved from basic prompt engineering into more advanced approaches that leverage chain-of-thought prompting, enabling agents to break down complex problems step-by-step.
Source: https://www.letta.com/blog/ai-agents-stack
Advanced agent frameworks like Open AI Agents SDK, Letta, and LangGraph have emerged as critical infrastructure, providing structured approaches for building reliable agents. These frameworks implement essential capabilities including planning, tool integration, memory management, and self-reflection. Modern agent architectures separate cognitive functions into specialized components - planners for strategy, executors for actions, and critics for evaluation - enabling them to handle increasingly complex tasks.
In real-world applications, LLM agents have proven highly adaptable. They can perform diverse tasks from software development and customer service to research synthesis - all by combining LLMs' reasoning capabilities with domain-specific tools and workflows. This architecture allows them to navigate complex problem spaces more flexibly than traditional automation while providing greater reliability than raw LLM outputs.
Source: https://weaviate.io/blog/what-are-agentic-workflows#planning-pattern
The field has identified several key design patterns that drive agent success. These include task decomposition (breaking goals into manageable steps), recursive reasoning (applying logic to intermediate results), tool augmentation (expanding capabilities through APIs), and human-in-the-loop collaboration (incorporating user feedback). These patterns work across different domains, establishing core principles for effective agent design.
These insights from LLM agent development provide crucial guidance for video intelligence systems. They show that foundation models work best within structured architectures that align with specific task requirements. They emphasize the importance of explicit planning and reflection for reliability. Most critically, they demonstrate that the most effective systems balance automation with human collaboration, creating true partnerships that leverage both machine and human intelligence. As we develop video agents, these principles will help us navigate the unique challenges of understanding and manipulating visual media.
3 - The Emergence of Video Agents: A New Paradigm
The convergence of video foundation models and LLM-based agent architectures has given rise to video agents—systems uniquely designed to understand, manipulate, and reason about visual media with unprecedented sophistication. Unlike their predecessors, these agents don't merely analyze video content; they interact with it purposefully, leveraging specialized knowledge about visual narratives, temporal relationships, and multimodal context. This new paradigm addresses fundamental limitations of both traditional video processing pipelines, which lack semantic understanding, and general-purpose AI agents, which struggle with the complex temporal and spatial dimensions inherent to video content.
What makes video agents distinct is their ability to navigate the unique challenges of video intelligence. Video data exists in a high-dimensional space combining visual, audio, and temporal elements, requiring specialized perception capabilities beyond those needed for text or static images. Computational demands scale dramatically with video length and resolution, necessitating efficient approaches to attention and memory. Perhaps most significantly, video understanding requires reasoning across multiple timescales simultaneously—from frame-level details to scene-level composition to narrative-level structure—a capability rarely needed in other domains. A system like OmAgent has pioneered a solution to these challenges through an innovative architecture combining multimodal RAG with a divide-and-conquer reasoning approach.
Source: https://www.om-agent.com/
Recent academic work has accelerated this shift, with researchers increasingly focusing on agentic frameworks for video understanding. Papers like "VideoAgent: A Memory-augmented Multimodal Agent for Video Understanding" from Peking University demonstrate how memory mechanisms can enhance temporal reasoning, while Stanford's research on "VideoAgent: Long-form Video Understanding with Large Language Model as Agent" explores efficient searching and aggregation of relevant information from lengthy videos. These approaches share a common insight: rather than processing all video content exhaustively, effective agents should reason about what's important, selectively attend to relevant segments, and dynamically build understanding through iterative analysis.
Source: https://wxh1996.github.io/VideoAgent-Website/
There are also works such as LAVE that combines LLM reasoning with video-specific tools. These systems typically structure their workflow around specialized components: perception systems for extracting multimodal features, memory mechanisms for storing and retrieving video context, planning modules for decomposing complex queries, and execution components for interfacing with video processing tools. This modularity allows them to combine the strengths of foundation models with domain-specific knowledge about video content and editing operations.
Source: https://arxiv.org/abs/2402.10294
As video agents evolve from research prototypes to production systems, they are increasingly addressing real-world challenges in content creation, media analysis, and information retrieval. Early adopters in broadcasting, film production, and social media are already leveraging these capabilities to automate previously manual tasks like highlight generation, content moderation, and promotional clip creation. The most advanced systems demonstrate an emerging ability to understand not just the surface content of videos, but their underlying purpose, style, and narrative structure—enabling interactions that feel more like collaborating with a knowledgeable assistant than operating a complex tool. This transition from passive analysis to active collaboration represents perhaps the most significant paradigm shift in video intelligence since the advent of multimodal AI.
4 - TwelveLabs Approach: Jockey as a Video Agent Framework
Incubated since last year, Jockey represents a significant evolution in video intelligence - built on the foundation of TwelveLabs' core video foundation models while adding a crucial orchestration layer to address the complexity gap. At its heart, Jockey leverages our two powerful video-native models: Marengo 2.7 for semantic video search and Pegasus 1.2 for advanced video-to-text understanding. Rather than replacing these models, Jockey strategically coordinates them through a planner-worker-reflector architecture that distributes cognitive tasks according to each component's strengths—using an LLM for planning and reasoning while delegating perception-intensive operations to specialized video models.
This architecture solves a fundamental challenge in video intelligence: while foundation models excel at perception and reasoning tasks, they often struggle with complex workflow sequencing. Jockey's multi-agent approach addresses this limitation by implementing a planner that creates detailed execution sequences, specialized workers that interface directly with video APIs, and a reflector that summarizes action steps. This separation of concerns allows each component to focus on what it does best—the LLMs handles reasoning and natural language understanding, while video foundation models manage the complex multimodal analysis.
What makes Jockey particularly powerful is its ability to maintain context across complex multi-step workflows. For video highlight generation, for instance, Jockey doesn't just execute a single search operation; it sequences searches with precise criteria, combines result sets intelligently, and applies post-processing operations that reflect the user's actual intent. The system maintains persistent state through a graph-based framework built on LangGraph, allowing it to track clips across multiple operations and maintain awareness of the overall task objective even as it executes granular subtasks.
Source: https://github.com/twelvelabs-io/tl-jockey/blob/main/jockey/stirrups/stirrup.py
The design of Jockey prioritizes adaptability—an essential quality for production deployments. Its modular architecture allows customization at multiple levels, from prompt-driven behavior adjustments to the addition of entirely new worker modules. This enables developers to extend Jockey's capabilities for specific workflows while maintaining the reliability of the core system.
5 - Bringing Transparency to Jockey
Creating an effective video agent presents unique engineering challenges specific to video manipulation that extend beyond typical LLM applications. The most notable challenge involves performance optimization in video processing pipelines, particularly for complex operations like clip extraction and combination. The approach we have taken is two-fold:
First, designing asynchronous processing pipelines using function dispatchers that handle discrete steps like
base_search(),process_clips(), anddownload_remaining()independently.Second, exposing these processing stages to users through transparent "thinking" states shown in the interface (more in Section 6).
This transparency isn't just about status updates—it builds essential trust by revealing how the system reaches its conclusions, showing which processing components are being leveraged at each moment.
Throughout Jockey's development, we have found that users develop stronger trust in systems that explain their reasoning, even when this slightly increases response time. This insight has fundamentally shaped our UI design, which explicitly displays processing states and the specific model components—whether Marengo's search capabilities or Pegasus's contextual understanding—being applied to each query. This transparency becomes particularly important when working with enterprise clients who need verifiable processes rather than black-box solutions.
Jockey’s future extension will be a bidirectional thinking system, which not only displays the agent's processing steps but also allows users to modify these steps directly. This capability transforms Jockey from a passive tool into a collaborative partner where users can interactively refine queries (changing chameleons in Japan to lizards in Japan), validate processing decisions, or redirect the agent's focus—essentially "steering" the AI rather than merely accepting its outputs. This approach aligns with findings from our work with the MLSE team and other enterprise customers, who consistently prioritize understanding and control over pure automation speed, particularly when dealing with high-value creative assets like video content.
Source: https://www.latent.space/p/why-mcp-won
The Model Context Protocol (MCP) framework offers intriguing possibilities for Jockey's future evolution, particularly as we expand into third-party integrations. MCP could provide a standardized integration layer between Jockey's core components and external services like video generation tools (RunwayML, Luma Labs), audio generation software (ElevenLabs, Suno), and advanced video operations tasks like scene segmentation and object tracking (Meta's SAM).
Rather than building custom connectors for each integration, MCP would enable us to define a consistent interface for tool invocation, context sharing, and response handling. This approach would transform an n×m integration problem (n agent frameworks × m tools) into a more manageable n+m problem, dramatically reducing implementation complexity while increasing system extensibility.
For Jockey specifically, MCP could enable more sophisticated workflows where, for instance, clips identified through Marengo could be seamlessly passed to external enhancement tools, then to generative audio services for voiceover, and finally to editing systems—all while maintaining coherent context throughout the entire process.
6 - The Power of Multimodal Interfaces
Traditional video interfaces have typically forced users to choose between text-based search that ignores visual context and video players with minimal interactive capabilities. Jockey reimagines this relationship through a fundamentally multimodal interface that combines conversational interaction with video-native elements, treating both modalities as first-class citizens rather than forcing one to accommodate the other. The interface shown in the screenshot below demonstrates this approach: a conversational area captures user intent through natural language, a visual thinking display reveals the agent's reasoning process, and a video gallery presents results with relevant context like timestamps and descriptions. This unified experience allows users to seamlessly transition between expressing high-level goals (find inspiring stories of people overcoming obstacles) and interacting directly with visual results.
What makes this approach powerful is the bidirectional flow of information between textual and visual elements. When a user issues a natural language query, Jockey provides responses that include both text explanations and direct links to relevant video segments, with precise timestamps marking where specific concepts appear in the footage. This temporal anchoring creates a clear bridge between Jockey's text responses and the actual video content being referenced.
Additionally, users can directly interact with the video segments through thumbnails, thereby enhancing the navigation experience. This creates a virtuous cycle where each modality enhances the other: language provides precision in specifying intent, while visual elements provide richness and context that would be inefficient to communicate textually. For instance, the screenshot below shows how Jockey displays agent thinking steps alongside timestamped video segments, helping users understand not just what content was found but why it was selected.
The interface addresses several cognitive challenges unique to video interaction. Video content is inherently temporal and dense with information, making it difficult to scan, browse, or compare in the way users can with text. Jockey's multimodal approach mitigates these challenges by providing multiple points of entry: users can browse visually through thumbnails, scan through agent-generated summaries, or jump directly to specific moments based on conceptual descriptions. By combining these approaches, the interface substantially reduces cognitive load, allowing users to maintain context when working with multiple videos simultaneously—as seen in the screenshot below where the user asks to Summarize these videos in an emotional tone after reviewing search results.
Perhaps most significantly, the interface evolves beyond simple query-response patterns into a true collaborative workspace. The agent thinking display shown in the screenshot below reveals how Jockey breaks down complex tasks into discrete steps like Understanding your request and Grabbing video context - creating transparency that builds user trust and allows for timely intervention. This transparency extends to displaying both the algorithmic confidence (via numbered steps) and thinking process, helping users calibrate their reliance on the system and make informed decisions about where human judgment might be needed. When combined with the ability to interrupt, redirect, or refine the agent's approach at any point in the workflow, this creates a genuinely collaborative relationship rather than the transactional model typical of traditional video interfaces.
The future evolution of this multimodal approach points toward what we call "flow-aware trajectories"—interfaces that anticipate the user's next likely actions based on emerging patterns in their workflow (more in Section 8). As shown in the agent's progressive reasoning in the screenshot above, Jockey already demonstrates early capabilities in this direction by maintaining context across conversation turns and building on previous interactions. As these capabilities mature, the interface will increasingly blur the line between agent and tool, becoming an extension of the user's creative process that anticipates needs, suggests alternative approaches, and handles technical details without breaking the user's creative flow. This represents a fundamental shift from interfaces that merely process requests to true collaborators that actively contribute to the creative and analytical process.
7 - Transforming Content Creation: Jockey's Vision for Enterprise Media Workflows
The enterprise media landscape is experiencing unprecedented challenges with content demands increasing exponentially while production resources remain constrained. Marketing teams must produce more video content across multiple platforms, each with different format requirements and audience expectations. Documentary filmmakers need to identify relevant moments from hundreds of hours of footage. Corporate communication departments struggle to maintain consistent messaging across global markets. These workflows share common pain points: they're time-intensive, require specialized skills, and don't scale effectively with traditional approaches.
Jockey's vision addresses these challenges by reimagining how enterprises interact with video content. Rather than simply automating existing processes, Jockey creates new possibilities for content workflows through its conversational interface and intelligent orchestration of video understanding capabilities. For example, a marketing team creating product demonstrations can instruct Jockey to find clips showing the product being used outdoors and then edit them together with smooth transitions. This natural language approach eliminates the technical barriers that typically slow production, allowing teams to focus on creative decisions rather than mechanical execution.
One particularly compelling application is in advertising and marketing workflows, where Jockey demonstrates immediate value. Creative teams often spend countless hours reviewing raw footage to identify moments that align with brand messaging or campaign themes. Jockey transforms this process by enabling teams to search video libraries using natural language queries like find clips where people express excitement after using our product or identify scenes with our logo prominently displayed in urban environments.The agent leverages Marengo's multimodal understanding to retrieve relevant footage and Pegasus's contextual awareness to assemble these moments into cohesive sequences, dramatically reducing the time from concept to finished asset.
The true power of Jockey's approach becomes evident in end-to-end creative workflows. Consider a corporate communications team tasked with creating product announcement videos. Traditionally, this requires storyboarding, filming, cataloging footage, editing rough cuts, adding graphics, recording voiceovers, and finalizing for distribution—each step involving different specialists and tools. The vision of Jockey is to consolidate these workflows by allowing teams to retrieve relevant footage, assemble initial cuts, generate accompanying audio, and prepare distribution-ready assets through natural language instructions. While still in its early stages, Jockey's development roadmap includes expanding these capabilities through third-party integrations with relevant tools —thereby creating a comprehensive platform that adapts to enterprise requirements rather than forcing organizations to adapt their workflows to technical limitations.
8 - The Future of Video Agents: Our Vision and Roadmap
The future evolution of video agents will be guided by three core principles that extend beyond incremental improvements to fundamentally transform how humans interact with visual media. With Jockey, we're building toward a vision where video intelligence becomes a natural extension of creative and analytical workflows, anticipating needs and adapting to individual preferences while maintaining the balance between automation and human creative control.
Flow-Aware Trajectories represent our first guiding principle—systems that anticipate user needs several steps ahead to maintain creative momentum. In practice, this means Jockey will predict which clips might be needed next during highlight creation, suggest appropriate transitions based on content, and even pre-assemble rough cuts that align with a user's editing patterns. As these capabilities mature, editors will experience fewer interruptions to their creative process, with the system handling technical details while preserving creative direction. For example, a sports producer could assemble a highlights package with Jockey automatically suggesting key plays based on crowd reactions, maintaining consistent pacing, and ensuring narrative flow—all while the producer maintains creative control over the final selection.
Contextual Meta-Learning enables Jockey to evolve with each interaction, building persistent understanding of user preferences across projects and sessions. Rather than requiring explicit instruction for every operation, the system will recognize patterns in user behavior—preferred transition styles, typical scene structures, or common editing sequences—and adapt its suggestions accordingly. This creates a virtuous cycle where the system becomes more valuable over time, remembering project-specific requirements and adapting to feedback. Organizations working on recurring content types (like weekly sports highlights or product reviews) will find their workflows becoming increasingly efficient as Jockey learns to prioritize relevant content and apply consistent styling without explicit direction.
Multimodal Intelligence at Scale allows Jockey to make sophisticated connections across video, audio, and textual elements without relying on rigid rules. This principle enables complex operations like retrieving scenes based on thematic relevance rather than just visual similarity, analyzing narrative flow across multiple clips, or identifying emotionally resonant sequences automatically. As we integrate additional third-party capabilities—such as audio generation for voiceovers, video generation for alternative scenes, or avatar creation for presentations—Jockey will orchestrate these specialized tools into cohesive workflows, maintaining context across operations and ensuring consistent quality in the final output. The integration roadmap includes partnerships with leading tools for segmentation, background replacement, synthetic media generation, and audio creation, significantly expanding Jockey's capabilities without requiring users to manage complex technical integrations.
The evolution of Jockey from tool to collaborative partner represents a paradigm shift in how organizations approach video assets. By focusing on these three principles and building an extensible ecosystem of capabilities, we're creating a platform that adapts to how people naturally think about video content rather than forcing users to adapt to technical limitations. For developers building on this platform, Jockey offers the opportunity to create applications that leverage sophisticated video intelligence without the complexity of integrating disparate models. For enterprises seeking to scale visual content creation, it provides a foundation for consistent, high-quality output that respects established workflows while dramatically improving efficiency.
9 - Conclusion: Embracing the Video Agent Revolution
The convergence of video foundation models and agent architectures represents a fundamental shift in how we create, analyze, and distribute video content. Jockey demonstrates that we can move beyond treating video as a monolithic medium requiring specialized expertise toward a programmatically accessible resource that adapts to varied workflows and creative needs. Through its combination of intelligent task allocation, native video processing, and human-collaborative design, it transforms previously labor-intensive tasks into fluid, conversational interactions—dramatically reducing production time while preserving creative control.
It's important to acknowledge Jockey's current limitations as an alpha-stage proof-of-concept. The agent sometimes requires specific phrasing to achieve optimal results, occasionally struggles with complex queries, and hasn't yet been optimized for specific workflows. The agent frameworks supporting Jockey are themselves rapidly evolving, as developers across the industry experiment with different approaches to planning, memory management, and multimodal reasoning. These limitations, however, are not fundamental barriers but stepping stones on a clear development pathway toward increasingly capable and intuitive video intelligence.
We invite you to join us in shaping this future for an early access to Jockey. We are specifically looking for adventurous early adopters who are willing to test our technology and provide valuable feedback. Please register your interest using this form: https://form.typeform.com/to/JCKz0aBA
Whether you're a content creator seeking to streamline production workflows, a developer looking to integrate video intelligence into your applications, or an enterprise needing to scale video operations, your feedback and use cases will directly influence our development priorities. By participating in this private alpha, you'll not only gain hands-on experience with cutting-edge video agent technology but contribute to a broader transformation in how we work with visual media. The video agent revolution isn't just coming—it's here, and your perspective can help define its path forward.
Thanks to my TwelveLabs colleagues (Kingston Yip, Simon Shim, Simon Lecointe, Yeonhoo Park, Sean Barclay, and Sunny Nguyen) for comments, feedback, and suggestions that helped with this post.
TLDR: The Rise of Agentic Video Intelligence
We are witnessing a seismic shift: video AI is evolving from a basic analysis tool into an intelligent collaborator that can understand context, reason about content, and execute complex creative tasks.
TwelveLabs' Jockey isn't just another AI tool—it's a sophisticated orchestrator that conducts our video-native foundation models like a symphony, turning chaotic video workflows into harmonious creative processes.
Forget clunky video interfaces: these new video agents speak your language while letting you get hands-on with the visuals, finally bridging the gap between human creativity and machine efficiency.
The days of wrestling with technical video tools are numbered—imagine telling your AI assistant
Find the most compelling customer storiesand watching it assemble a perfect highlight reel.For enterprises drowning in video content, this isn't just an upgrade—it's a revolution that transforms overwhelming media libraries into accessible, actionable assets through natural conversation.
You can listen to this article via this NotebookLM-generated conversation here: https://soundcloud.com/james-le-56344460/agentic-video-intelligence
1 - Introduction: The Video Intelligence Evolution
In 2025, we stand at the precipice of a fundamental shift in how machines understand and manipulate visual media. With billion hours of video content uploaded daily across platforms, traditional processing tools—designed for an era of limited content and predefined tasks—are becoming obsolete. This explosion of content has created both unprecedented opportunities and formidable challenges.
The emergence of video foundation models has evolved our capabilities from simple frame-by-frame video analysis to sophisticated spatial understanding and temporal reasoning. However, a critical gap remains between raw model capabilities and real-world applications. This is where agentic video intelligence enters the picture—representing a paradigm shift from passive analysis to active, goal-oriented interaction with video content. These systems combine video foundation models with large language models through agent planning frameworks - creating AI systems that understand not just what appears in a video, but why it matters and what actions to take.
At TwelveLabs, we're addressing these challenges through Jockey—a conversational video agent that combines video foundation models with LLM-based reasoning through a purpose-built agent architecture. In this article, we'll explore how video intelligence is becoming increasingly agentic by way of examining technical innovations from both engineering and design perspectives. From media production to sports highlight generation, this shift enables entirely new approaches to content creation and analysis that weren't previously possible. For organizations building the next generation of video applications, this represents a transformative opportunity to combine human creativity with machine efficiency. The revolution in video intelligence isn't just coming—it's already here. And it's agentic.
2 - The Rise of AI Agents in the LLM Domain
The emergence of Large Language Models (LLMs) has revolutionized AI by enabling autonomous agents that can understand, plan, and act. These LLM-powered agents use natural language as their interface, allowing them to comprehend goals and execute complex tasks through sophisticated reasoning and tool integration. This capability evolved from basic prompt engineering into more advanced approaches that leverage chain-of-thought prompting, enabling agents to break down complex problems step-by-step.
Source: https://www.letta.com/blog/ai-agents-stack
Advanced agent frameworks like Open AI Agents SDK, Letta, and LangGraph have emerged as critical infrastructure, providing structured approaches for building reliable agents. These frameworks implement essential capabilities including planning, tool integration, memory management, and self-reflection. Modern agent architectures separate cognitive functions into specialized components - planners for strategy, executors for actions, and critics for evaluation - enabling them to handle increasingly complex tasks.
In real-world applications, LLM agents have proven highly adaptable. They can perform diverse tasks from software development and customer service to research synthesis - all by combining LLMs' reasoning capabilities with domain-specific tools and workflows. This architecture allows them to navigate complex problem spaces more flexibly than traditional automation while providing greater reliability than raw LLM outputs.
Source: https://weaviate.io/blog/what-are-agentic-workflows#planning-pattern
The field has identified several key design patterns that drive agent success. These include task decomposition (breaking goals into manageable steps), recursive reasoning (applying logic to intermediate results), tool augmentation (expanding capabilities through APIs), and human-in-the-loop collaboration (incorporating user feedback). These patterns work across different domains, establishing core principles for effective agent design.
These insights from LLM agent development provide crucial guidance for video intelligence systems. They show that foundation models work best within structured architectures that align with specific task requirements. They emphasize the importance of explicit planning and reflection for reliability. Most critically, they demonstrate that the most effective systems balance automation with human collaboration, creating true partnerships that leverage both machine and human intelligence. As we develop video agents, these principles will help us navigate the unique challenges of understanding and manipulating visual media.
3 - The Emergence of Video Agents: A New Paradigm
The convergence of video foundation models and LLM-based agent architectures has given rise to video agents—systems uniquely designed to understand, manipulate, and reason about visual media with unprecedented sophistication. Unlike their predecessors, these agents don't merely analyze video content; they interact with it purposefully, leveraging specialized knowledge about visual narratives, temporal relationships, and multimodal context. This new paradigm addresses fundamental limitations of both traditional video processing pipelines, which lack semantic understanding, and general-purpose AI agents, which struggle with the complex temporal and spatial dimensions inherent to video content.
What makes video agents distinct is their ability to navigate the unique challenges of video intelligence. Video data exists in a high-dimensional space combining visual, audio, and temporal elements, requiring specialized perception capabilities beyond those needed for text or static images. Computational demands scale dramatically with video length and resolution, necessitating efficient approaches to attention and memory. Perhaps most significantly, video understanding requires reasoning across multiple timescales simultaneously—from frame-level details to scene-level composition to narrative-level structure—a capability rarely needed in other domains. A system like OmAgent has pioneered a solution to these challenges through an innovative architecture combining multimodal RAG with a divide-and-conquer reasoning approach.
Source: https://www.om-agent.com/
Recent academic work has accelerated this shift, with researchers increasingly focusing on agentic frameworks for video understanding. Papers like "VideoAgent: A Memory-augmented Multimodal Agent for Video Understanding" from Peking University demonstrate how memory mechanisms can enhance temporal reasoning, while Stanford's research on "VideoAgent: Long-form Video Understanding with Large Language Model as Agent" explores efficient searching and aggregation of relevant information from lengthy videos. These approaches share a common insight: rather than processing all video content exhaustively, effective agents should reason about what's important, selectively attend to relevant segments, and dynamically build understanding through iterative analysis.
Source: https://wxh1996.github.io/VideoAgent-Website/
There are also works such as LAVE that combines LLM reasoning with video-specific tools. These systems typically structure their workflow around specialized components: perception systems for extracting multimodal features, memory mechanisms for storing and retrieving video context, planning modules for decomposing complex queries, and execution components for interfacing with video processing tools. This modularity allows them to combine the strengths of foundation models with domain-specific knowledge about video content and editing operations.
Source: https://arxiv.org/abs/2402.10294
As video agents evolve from research prototypes to production systems, they are increasingly addressing real-world challenges in content creation, media analysis, and information retrieval. Early adopters in broadcasting, film production, and social media are already leveraging these capabilities to automate previously manual tasks like highlight generation, content moderation, and promotional clip creation. The most advanced systems demonstrate an emerging ability to understand not just the surface content of videos, but their underlying purpose, style, and narrative structure—enabling interactions that feel more like collaborating with a knowledgeable assistant than operating a complex tool. This transition from passive analysis to active collaboration represents perhaps the most significant paradigm shift in video intelligence since the advent of multimodal AI.
4 - TwelveLabs Approach: Jockey as a Video Agent Framework
Incubated since last year, Jockey represents a significant evolution in video intelligence - built on the foundation of TwelveLabs' core video foundation models while adding a crucial orchestration layer to address the complexity gap. At its heart, Jockey leverages our two powerful video-native models: Marengo 2.7 for semantic video search and Pegasus 1.2 for advanced video-to-text understanding. Rather than replacing these models, Jockey strategically coordinates them through a planner-worker-reflector architecture that distributes cognitive tasks according to each component's strengths—using an LLM for planning and reasoning while delegating perception-intensive operations to specialized video models.
This architecture solves a fundamental challenge in video intelligence: while foundation models excel at perception and reasoning tasks, they often struggle with complex workflow sequencing. Jockey's multi-agent approach addresses this limitation by implementing a planner that creates detailed execution sequences, specialized workers that interface directly with video APIs, and a reflector that summarizes action steps. This separation of concerns allows each component to focus on what it does best—the LLMs handles reasoning and natural language understanding, while video foundation models manage the complex multimodal analysis.
What makes Jockey particularly powerful is its ability to maintain context across complex multi-step workflows. For video highlight generation, for instance, Jockey doesn't just execute a single search operation; it sequences searches with precise criteria, combines result sets intelligently, and applies post-processing operations that reflect the user's actual intent. The system maintains persistent state through a graph-based framework built on LangGraph, allowing it to track clips across multiple operations and maintain awareness of the overall task objective even as it executes granular subtasks.
Source: https://github.com/twelvelabs-io/tl-jockey/blob/main/jockey/stirrups/stirrup.py
The design of Jockey prioritizes adaptability—an essential quality for production deployments. Its modular architecture allows customization at multiple levels, from prompt-driven behavior adjustments to the addition of entirely new worker modules. This enables developers to extend Jockey's capabilities for specific workflows while maintaining the reliability of the core system.
5 - Bringing Transparency to Jockey
Creating an effective video agent presents unique engineering challenges specific to video manipulation that extend beyond typical LLM applications. The most notable challenge involves performance optimization in video processing pipelines, particularly for complex operations like clip extraction and combination. The approach we have taken is two-fold:
First, designing asynchronous processing pipelines using function dispatchers that handle discrete steps like
base_search(),process_clips(), anddownload_remaining()independently.Second, exposing these processing stages to users through transparent "thinking" states shown in the interface (more in Section 6).
This transparency isn't just about status updates—it builds essential trust by revealing how the system reaches its conclusions, showing which processing components are being leveraged at each moment.
Throughout Jockey's development, we have found that users develop stronger trust in systems that explain their reasoning, even when this slightly increases response time. This insight has fundamentally shaped our UI design, which explicitly displays processing states and the specific model components—whether Marengo's search capabilities or Pegasus's contextual understanding—being applied to each query. This transparency becomes particularly important when working with enterprise clients who need verifiable processes rather than black-box solutions.
Jockey’s future extension will be a bidirectional thinking system, which not only displays the agent's processing steps but also allows users to modify these steps directly. This capability transforms Jockey from a passive tool into a collaborative partner where users can interactively refine queries (changing chameleons in Japan to lizards in Japan), validate processing decisions, or redirect the agent's focus—essentially "steering" the AI rather than merely accepting its outputs. This approach aligns with findings from our work with the MLSE team and other enterprise customers, who consistently prioritize understanding and control over pure automation speed, particularly when dealing with high-value creative assets like video content.
Source: https://www.latent.space/p/why-mcp-won
The Model Context Protocol (MCP) framework offers intriguing possibilities for Jockey's future evolution, particularly as we expand into third-party integrations. MCP could provide a standardized integration layer between Jockey's core components and external services like video generation tools (RunwayML, Luma Labs), audio generation software (ElevenLabs, Suno), and advanced video operations tasks like scene segmentation and object tracking (Meta's SAM).
Rather than building custom connectors for each integration, MCP would enable us to define a consistent interface for tool invocation, context sharing, and response handling. This approach would transform an n×m integration problem (n agent frameworks × m tools) into a more manageable n+m problem, dramatically reducing implementation complexity while increasing system extensibility.
For Jockey specifically, MCP could enable more sophisticated workflows where, for instance, clips identified through Marengo could be seamlessly passed to external enhancement tools, then to generative audio services for voiceover, and finally to editing systems—all while maintaining coherent context throughout the entire process.
6 - The Power of Multimodal Interfaces
Traditional video interfaces have typically forced users to choose between text-based search that ignores visual context and video players with minimal interactive capabilities. Jockey reimagines this relationship through a fundamentally multimodal interface that combines conversational interaction with video-native elements, treating both modalities as first-class citizens rather than forcing one to accommodate the other. The interface shown in the screenshot below demonstrates this approach: a conversational area captures user intent through natural language, a visual thinking display reveals the agent's reasoning process, and a video gallery presents results with relevant context like timestamps and descriptions. This unified experience allows users to seamlessly transition between expressing high-level goals (find inspiring stories of people overcoming obstacles) and interacting directly with visual results.
What makes this approach powerful is the bidirectional flow of information between textual and visual elements. When a user issues a natural language query, Jockey provides responses that include both text explanations and direct links to relevant video segments, with precise timestamps marking where specific concepts appear in the footage. This temporal anchoring creates a clear bridge between Jockey's text responses and the actual video content being referenced.
Additionally, users can directly interact with the video segments through thumbnails, thereby enhancing the navigation experience. This creates a virtuous cycle where each modality enhances the other: language provides precision in specifying intent, while visual elements provide richness and context that would be inefficient to communicate textually. For instance, the screenshot below shows how Jockey displays agent thinking steps alongside timestamped video segments, helping users understand not just what content was found but why it was selected.
The interface addresses several cognitive challenges unique to video interaction. Video content is inherently temporal and dense with information, making it difficult to scan, browse, or compare in the way users can with text. Jockey's multimodal approach mitigates these challenges by providing multiple points of entry: users can browse visually through thumbnails, scan through agent-generated summaries, or jump directly to specific moments based on conceptual descriptions. By combining these approaches, the interface substantially reduces cognitive load, allowing users to maintain context when working with multiple videos simultaneously—as seen in the screenshot below where the user asks to Summarize these videos in an emotional tone after reviewing search results.
Perhaps most significantly, the interface evolves beyond simple query-response patterns into a true collaborative workspace. The agent thinking display shown in the screenshot below reveals how Jockey breaks down complex tasks into discrete steps like Understanding your request and Grabbing video context - creating transparency that builds user trust and allows for timely intervention. This transparency extends to displaying both the algorithmic confidence (via numbered steps) and thinking process, helping users calibrate their reliance on the system and make informed decisions about where human judgment might be needed. When combined with the ability to interrupt, redirect, or refine the agent's approach at any point in the workflow, this creates a genuinely collaborative relationship rather than the transactional model typical of traditional video interfaces.
The future evolution of this multimodal approach points toward what we call "flow-aware trajectories"—interfaces that anticipate the user's next likely actions based on emerging patterns in their workflow (more in Section 8). As shown in the agent's progressive reasoning in the screenshot above, Jockey already demonstrates early capabilities in this direction by maintaining context across conversation turns and building on previous interactions. As these capabilities mature, the interface will increasingly blur the line between agent and tool, becoming an extension of the user's creative process that anticipates needs, suggests alternative approaches, and handles technical details without breaking the user's creative flow. This represents a fundamental shift from interfaces that merely process requests to true collaborators that actively contribute to the creative and analytical process.
7 - Transforming Content Creation: Jockey's Vision for Enterprise Media Workflows
The enterprise media landscape is experiencing unprecedented challenges with content demands increasing exponentially while production resources remain constrained. Marketing teams must produce more video content across multiple platforms, each with different format requirements and audience expectations. Documentary filmmakers need to identify relevant moments from hundreds of hours of footage. Corporate communication departments struggle to maintain consistent messaging across global markets. These workflows share common pain points: they're time-intensive, require specialized skills, and don't scale effectively with traditional approaches.
Jockey's vision addresses these challenges by reimagining how enterprises interact with video content. Rather than simply automating existing processes, Jockey creates new possibilities for content workflows through its conversational interface and intelligent orchestration of video understanding capabilities. For example, a marketing team creating product demonstrations can instruct Jockey to find clips showing the product being used outdoors and then edit them together with smooth transitions. This natural language approach eliminates the technical barriers that typically slow production, allowing teams to focus on creative decisions rather than mechanical execution.
One particularly compelling application is in advertising and marketing workflows, where Jockey demonstrates immediate value. Creative teams often spend countless hours reviewing raw footage to identify moments that align with brand messaging or campaign themes. Jockey transforms this process by enabling teams to search video libraries using natural language queries like find clips where people express excitement after using our product or identify scenes with our logo prominently displayed in urban environments.The agent leverages Marengo's multimodal understanding to retrieve relevant footage and Pegasus's contextual awareness to assemble these moments into cohesive sequences, dramatically reducing the time from concept to finished asset.
The true power of Jockey's approach becomes evident in end-to-end creative workflows. Consider a corporate communications team tasked with creating product announcement videos. Traditionally, this requires storyboarding, filming, cataloging footage, editing rough cuts, adding graphics, recording voiceovers, and finalizing for distribution—each step involving different specialists and tools. The vision of Jockey is to consolidate these workflows by allowing teams to retrieve relevant footage, assemble initial cuts, generate accompanying audio, and prepare distribution-ready assets through natural language instructions. While still in its early stages, Jockey's development roadmap includes expanding these capabilities through third-party integrations with relevant tools —thereby creating a comprehensive platform that adapts to enterprise requirements rather than forcing organizations to adapt their workflows to technical limitations.
8 - The Future of Video Agents: Our Vision and Roadmap
The future evolution of video agents will be guided by three core principles that extend beyond incremental improvements to fundamentally transform how humans interact with visual media. With Jockey, we're building toward a vision where video intelligence becomes a natural extension of creative and analytical workflows, anticipating needs and adapting to individual preferences while maintaining the balance between automation and human creative control.
Flow-Aware Trajectories represent our first guiding principle—systems that anticipate user needs several steps ahead to maintain creative momentum. In practice, this means Jockey will predict which clips might be needed next during highlight creation, suggest appropriate transitions based on content, and even pre-assemble rough cuts that align with a user's editing patterns. As these capabilities mature, editors will experience fewer interruptions to their creative process, with the system handling technical details while preserving creative direction. For example, a sports producer could assemble a highlights package with Jockey automatically suggesting key plays based on crowd reactions, maintaining consistent pacing, and ensuring narrative flow—all while the producer maintains creative control over the final selection.
Contextual Meta-Learning enables Jockey to evolve with each interaction, building persistent understanding of user preferences across projects and sessions. Rather than requiring explicit instruction for every operation, the system will recognize patterns in user behavior—preferred transition styles, typical scene structures, or common editing sequences—and adapt its suggestions accordingly. This creates a virtuous cycle where the system becomes more valuable over time, remembering project-specific requirements and adapting to feedback. Organizations working on recurring content types (like weekly sports highlights or product reviews) will find their workflows becoming increasingly efficient as Jockey learns to prioritize relevant content and apply consistent styling without explicit direction.
Multimodal Intelligence at Scale allows Jockey to make sophisticated connections across video, audio, and textual elements without relying on rigid rules. This principle enables complex operations like retrieving scenes based on thematic relevance rather than just visual similarity, analyzing narrative flow across multiple clips, or identifying emotionally resonant sequences automatically. As we integrate additional third-party capabilities—such as audio generation for voiceovers, video generation for alternative scenes, or avatar creation for presentations—Jockey will orchestrate these specialized tools into cohesive workflows, maintaining context across operations and ensuring consistent quality in the final output. The integration roadmap includes partnerships with leading tools for segmentation, background replacement, synthetic media generation, and audio creation, significantly expanding Jockey's capabilities without requiring users to manage complex technical integrations.
The evolution of Jockey from tool to collaborative partner represents a paradigm shift in how organizations approach video assets. By focusing on these three principles and building an extensible ecosystem of capabilities, we're creating a platform that adapts to how people naturally think about video content rather than forcing users to adapt to technical limitations. For developers building on this platform, Jockey offers the opportunity to create applications that leverage sophisticated video intelligence without the complexity of integrating disparate models. For enterprises seeking to scale visual content creation, it provides a foundation for consistent, high-quality output that respects established workflows while dramatically improving efficiency.
9 - Conclusion: Embracing the Video Agent Revolution
The convergence of video foundation models and agent architectures represents a fundamental shift in how we create, analyze, and distribute video content. Jockey demonstrates that we can move beyond treating video as a monolithic medium requiring specialized expertise toward a programmatically accessible resource that adapts to varied workflows and creative needs. Through its combination of intelligent task allocation, native video processing, and human-collaborative design, it transforms previously labor-intensive tasks into fluid, conversational interactions—dramatically reducing production time while preserving creative control.
It's important to acknowledge Jockey's current limitations as an alpha-stage proof-of-concept. The agent sometimes requires specific phrasing to achieve optimal results, occasionally struggles with complex queries, and hasn't yet been optimized for specific workflows. The agent frameworks supporting Jockey are themselves rapidly evolving, as developers across the industry experiment with different approaches to planning, memory management, and multimodal reasoning. These limitations, however, are not fundamental barriers but stepping stones on a clear development pathway toward increasingly capable and intuitive video intelligence.
We invite you to join us in shaping this future for an early access to Jockey. We are specifically looking for adventurous early adopters who are willing to test our technology and provide valuable feedback. Please register your interest using this form: https://form.typeform.com/to/JCKz0aBA
Whether you're a content creator seeking to streamline production workflows, a developer looking to integrate video intelligence into your applications, or an enterprise needing to scale video operations, your feedback and use cases will directly influence our development priorities. By participating in this private alpha, you'll not only gain hands-on experience with cutting-edge video agent technology but contribute to a broader transformation in how we work with visual media. The video agent revolution isn't just coming—it's here, and your perspective can help define its path forward.
Thanks to my TwelveLabs colleagues (Kingston Yip, Simon Shim, Simon Lecointe, Yeonhoo Park, Sean Barclay, and Sunny Nguyen) for comments, feedback, and suggestions that helped with this post.
Related articles








© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved
© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved
© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved