WHAT OUR PARTNERS ARE SAYING
Marengo 2.7: Pioneering Multi-Vector Embeddings for Advanced Video Understanding
Jeff Kim, Mars Ha, James Le
We are excited to announce Marengo 2.7 - a breakthrough in video understanding powered by our innovative multi-vector embedding architecture!
We are excited to announce Marengo 2.7 - a breakthrough in video understanding powered by our innovative multi-vector embedding architecture!

In this article
No headings found on page
Join our newsletter
Join our newsletter
Receive the latest advancements, tutorials, and industry insights in video understanding
Receive the latest advancements, tutorials, and industry insights in video understanding
Search, analyze, and explore your videos with AI.
Dec 4, 2024
18 Min
Copy link to article
1 - Introduction
Twelve Labs is excited to announce Marengo 2.7, a new state-of-the-art multimodal embedding model that achieves over 15% improvement over its predecessor Marengo 2.6.
Introduction to multi-vector video representation
Unlike text, where a single word embedding can effectively capture semantic meaning, video content is inherently more complex and multifaceted. A video clip simultaneously contains visual elements (objects, scenes, actions), temporal dynamics (motion, transitions), audio components (speech, ambient sounds, music), and often textual information (overlays, subtitles). Traditional single-vector approaches struggle to effectively compress all these diverse aspects into one representation without losing critical information. This complexity necessitates a more sophisticated approach to video understanding.
To address this complexity, Marengo 2.7 uses a unique multi-vector approach. Instead of compressing everything into a single vector, it creates separate vectors for different aspects of the video. One vector might capture what things look like (e.g., "a man in a black shirt"), another tracks movement (e.g., "waving his hand"), and another remembers what was said (e.g., "video foundation model is fun"). This approach helps the model better understand videos that contain many different types of information, leading to more accurate video analysis across all aspects - visual, motion, and audio.
Evaluated on 60+ multimodal retrieval datasets
Existing benchmarks for video understanding models often rely on detailed, narrative-style descriptions that capture the main events in a video. However, this approach doesn't reflect real-world usage patterns, where users typically make shorter, more ambiguous queries like "find the red car" or "show me the celebration scene." Users also frequently search for peripheral details, background elements, or specific objects that may only appear briefly. Additionally, queries often combine multiple modalities - visual elements with audio cues, or text overlays with specific actions. This disconnect between benchmark evaluation and actual use cases necessitated a more comprehensive evaluation approach for Marengo 2.7.
Understanding the limitations of existing benchmarks in capturing real-world use cases, we developed an extensive evaluation framework encompassing over 60 diverse datasets. This framework rigorously tests the model's capabilities across:
Generic visual understanding
Complex query comprehension
Small object detection
OCR interpretation
Logo recognition
Audio processing (verbal and non-verbal)
State-of-the-Art Performance with unparalleled Image-to-Visual Search Capabilities
Marengo 2.7 demonstrates state-of-the-art performance across all main benchmarks, with particularly remarkable achievements in image-to-visual search capabilities. While the model shows strong performance across all metrics, its performance in image object search and image logo search represent a significant leap forward in the field.
General text-to-visual search: 74.9% average performance across MSRVTT and COCO datasets, surpassing external SOTA models by 4.6%.
Motion(text)-to-visual search: 78.1% average recall in Something Something v2, surpassing external SOTA model by 30.0%.
OCR(text) search: 77.0% average performance across TextCaps and BLIP3-OCR datasets, surpassing external SOTA models by 13.4%.
Small object(text)-to-visual search: 52.7% average performance across obj365-medium, bdd-medium, and mapillary-medium datasets, surpassing external SOTA models by 10.1%.
General image-to-visual search: An outstanding 90.6% average performance across obj365-easy, obj365-medium, and LaSOT datasets, demonstrating a remarkable 35.0% improvement over external SOTA models - our biggest performance leap yet.
Logo(image)-to-visual search: An impressive 56.0% average performance across OpenLogo, ads-logo, and basketball-logo datasets, showcasing significant advancement with a 19.2% improvement over external SOTA models.
General text-to-audio search: 57.7% average performance across AudioCaps, Clotho, and GTZAN datasets, surpassing Marengo-2.6 by 7.7%.
2 - Marengo 2.7 Overview
Building upon the success of Marengo 2.6, our latest Marengo 2.7 video foundation model represents a significant advancement in multimodal video understanding. We also introduce a novel multi-vector approach that enables more precise and comprehensive video content analysis.
2.1 - Unified Framework with a Multi-Vector Architecture

At its core, Marengo-2.7 employs a Transformer-based architecture that processes video content through a single unified framework, capable of understanding:
Visual elements: fine-grained object detection, motion dynamics, temporal relationships, and appearance features
Audio elements: native speech understanding, non-verbal sound recognition, and music interpretation
A core element of Marengo-2.7 is its unique multi-vector representation. Unlike Marengo-2.6 that compress all information into a single embedding, Marengo-2.7 decomposes the raw inputs into multiple specialized vectors. Each vector independently captures distinct aspects of the video content - from visual appearance and motion dynamics to OCR text and speech patterns. This granular representation enables more nuanced and accurate multimodal search capabilities. The approach shows particular strength in detecting small objects while maintaining exceptional performance in general text-based search tasks.
2.2 - Training and Data
Training for Marengo 2.7 focuses on self-supervised learning with contrastive loss on a comprehensive multimodal dataset. Based on our business and customers’ needs, we have carefully curated and augmented an enormous and diverse dataset that's beneficial for training the model.
Additionally, we enhanced our training data through re-captioning with Pegasus, our own large video-language model. This process generated high-quality descriptions that capture world knowledge and complex motion and spatio-temporal relationships. This is based on the insight that text descriptions are extremely important in training a very robust model (Fan et.al., LaCLIP, 2023.10 and Gu et. al., RWKV-CLIP, 2024.06).
The comprehensive training data allows Marengo 2.7 to develop a robust understanding across domains and modalities. With its extensive video content, the model learns sophisticated temporal relationships and cross-modal interactions.
3 - Quantitative Evaluation

The performance of Marengo 2.7 has been extensively evaluated against leading multimodal retrieval models and specialized solutions across multiple domains on 60+ benchmark datasets. Our evaluation framework encompasses text-to-visual, image-to-visual, and text-to-audio search capabilities, providing a comprehensive assessment of the model's multimodal understanding.
3.1 - Baseline Models
We selected these strong baseline models for comparison:
Data Filtering Network-H/14-378 (Fang et al, Apple & University of Washington, 2023.09): This open-source image foundation model is based on the CLIP training objective. It was trained on 5 billion image-text pairs with a 378x378 image resolution.
InternVideo2-1B (Wang et al, OpenGVLab, 2024.08): This open-source video foundation model is based on the video ViT architecture trained with contrastive training objective. It was trained on datasets comprising 100M videos and 300M images.
(Commercial) Google Vertex Multimodal Embedding API, (multimodalembedding@001, 2024.10): This commercial API from Google Cloud provides multimodal embeddings for images, videos, and text. It leverages Google's research in multimodal understanding and was trained on their large-scale proprietary dataset.
Marengo 2.6 (Twelve Labs, 2024.03): Marengo 2.6 is a our own video foundation model trained with contrastive loss on a comprehensive multimodal dataset curated consisting of 60M videos, 500M images, and 500K audios.
3.2 - Evaluation Datasets
The evaluation framework utilizes diverse datasets:
Text-to-Visual Datasets
MSRVTT: 1,000 videos for web domain text-to-video evaluation
COCO: 5,000 images for text-to-image retrieval
Something-Something v2: 1,989 videos for motion understanding
TextCaps: 5,000 images for OCR-focused text-to-image retrieval
BLIP3-OCR: 9,687 images with multi-level OCR annotations to test text-to-OCR retrieval
Custom small object datasets: These are custom datasets we created to evaluate search queries targeting small objects (1-10% coverage) in images, which better reflect real user behavior. They include Object365-medium (10,000 images), Mapillary-medium (278 images), and BDD-medium (636 images).
Text-to-Audio Datasets
AudioCaps and Clotho: Text-to-generic audio evaluation - AudioCaps consist of 957 audios and 4785 text queries, while Clotho consist of 1045 audios and 5225 text queries.
GTZAN: Genre classification with 10 templated queries.
Image-to-Visual Datasets
Object365: Image detection dataset with objects split into "obj365-easy" (>10% image coverage) and "obj365-medium" (1-10% coverage) sets based on bounding box annotations. Object boxes were cropped to create image queries with source images as targets.
LaSOT: Video tracking dataset converted for image-to-video retrieval
OpenLogo: Object detection dataset in logo domain. We convert the dataset into image to image task by selecting 289 logo images as the query and 2039 images as targets.
Custom logo datasets: We created ads-logo (287 videos, 233 logos) and basketball-logo (300 videos, 154 logos) datasets with custom annotations to assess the model's ability to find specific logos in video content in diverse domains.
To ensure transparency and reproducibility, we will open-source our comprehensive evaluation framework for video retrieval. While our current evaluation datasets are primarily machine-generated and effectively demonstrate performance trends, they require further refinement and human validation before public release. We are actively working on polishing these datasets to ensure they meet the high standards expected for public research use.
3.3 - Text-to-Visual Search Performance
General Visual Search

In general visual search, Marengo 2.7 achieves a 74.9% average recall across two benchmark datasets. These results represent a 4.7% improvement over Marengo 2.6 and a 4.6% advantage over external SOTA models.
Motion Search

In motion search, Marengo 2.7 achieves a 78.1% average recall in Something Something v2 These results represent a 22.5% improvement over Marengo 2.6 and a 30.0% advantage over external SOTA models.
OCR Search

In OCR search, Marengo 2.7 achieves a 77.0% mean average precision across two benchmark datasets. This represents a 10.1% improvement over Marengo 2.6 and a 13.4% advantage over external SOTA models.
Small Object Search

In small object search, Marengo 2.7 achieves a 52.7% average recall across three custom benchmark datasets. These results represent a 10.14% improvement over Marengo 2.6 and a 10.08% advantage over external SOTA models.
3.4 - Image-to-Visual Search Performance
General (Small Object) Search

In object search, Marengo 2.7 achieves a 90.6% average recall across three benchmark datasets. This result shows improvements over both Marengo 2.6 (32.6% increase) and external SOTA models (35.0% increase).
Logo Search

In logo search, Marengo 2.7 achieves an average mean average precision of 56.0% across three benchmark datasets. This represents a 31.8% improvement over its predecessor and a 19.2% advantage over external SOTA models. Note that the Logo Expert Model mentioned above is Google Cloud Vision API - Detect Logos.
3.5 - Text-to-Audio Search Performance
General Audio Search

In general audio search, Marengo 2.7 achieves a 57.7% average recall across three benchmark datasets. This represents a 7.7% improvement over Marengo 2.6.
4 - Qualitative Results
To illustrate Marengo 2.7's capabilities across different search modalities, we present several representative examples that showcase its real-world performance.
Text-to-Visual (Marengo 2.7)
The model demonstrates sophisticated understanding of complex events and scenes through two examples:
A detailed sports play involving multiple actions
Query: Multiple New England Patriots pressure and block punt, ball rolls out of bounds, turnover on downs.
Top-3 Results:
Sequential visual elements in an urban setting
Query: A car is passing by BEST BUY, a Jeep dealership, and THE HOME DEPOT.
Top-3 Results:
Image-to-Video (Marengo 2.7)
Marengo 2.7 supports searching on low resolution image (64x64) while achieving remarkable result, such as finding small logos or objects in the background of the video frame. Let’s see its visual search capabilities:
Logo detection
Query (Image): Identifying the Chase bank logo in a complex viewing angle

Top-3 Results:
Object search
Query (Image): Identifying Clorox wipes on the shelf

Top-3 Results:
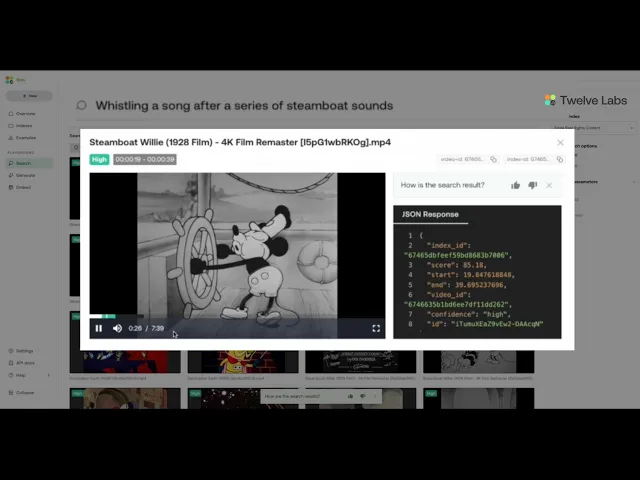
Text-to-Audio (Marengo 2.7)
The model's audio understanding is showcased through:
Speech comprehension: Processing and matching conversational content
Query 1: “tell me what's happening”
Top-3 Results:
Query 2: “I have devised a couple of ways to kind of give you a better idea of how each golf bag performs in its given field while standing in a golf cart.”
Top-3 Results:
Query 3: “I was planning on buying a keyboard for my mom, who likes to use a physical keyboard and has a tablet at home and at work.”
Top-3 Results:
Instrument recognition: Identifying specific musical elements (”violin sound”)
Top-3 Results:
These examples demonstrate Marengo 2.7's ability to handle diverse query types while maintaining high precision across different modalities.
5 - Limitations and Future Work
While Marengo 2.7 demonstrates significant improvements across multiple modalities, several challenges remain in achieving comprehensive video understanding.
Complex Scene Understanding
While the excels at identifying primary actions and objects, it may miss subtle background activities or parallel events that occur simultaneously in the video.
Visual Exact Match Challenges
The model can sometimes struggle with finding exact visual matches, particularly when searching for specific instances of objects or people that may appear multiple times in slightly different contexts.
Query Interpretation
While Marengo 2.7 handles most queries effectively, it can encounter challenges with:
Highly compositional queries involving multiple temporal relationships
Complex negation patterns beyond simple cases
Queries requiring abstract reasoning or world knowledge
Performance in Logo Search, Conversation Search, and OCR Search
Additionally, Marengo 2.7 shows limitations in text-to-logo search scenarios, particularly when dealing with logos occupy less than 1% of the frame or appear in challenging viewing angles.
In conversation and OCR search, the model struggles with heavily accented speech, overlapping conversations, and text in unusual fonts or orientations. These challenges are particularly evident in real-world scenarios with poor lighting conditions or complex backgrounds.
These limitations represent natural areas for future research and development as we continue to advance the capabilities of multimodal video understanding. Our ongoing work focuses on addressing these challenges while maintaining the model's current strengths in cross-modal understanding and temporal reasoning.
6 - Conclusion
Marengo 2.7 represents a significant leap forward in multimodal video understanding, demonstrating substantial improvements across visual, audio, and text modalities. Through its innovative multi-vector approach and comprehensive evaluation framework, we've shown that it's possible to achieve state-of-the-art performance in complex video understanding tasks while maintaining high precision across different use cases.
To support transparency and reproducibility in the field, we will be releasing a detailed technical report along with our comprehensive evaluation framework. This framework, which includes testing across 60+ datasets, will be open-sourced and regularly maintained to enable researchers and practitioners to validate our results and contribute to advancing multimodal video understanding.
Acknowledgements
This is a joint team effort across multiple functional groups including science, engineering, product, business development, and operation. It is co-authored by the Marengo team under Twelve Labs Research Science division.
Resources
Link to sign up and play with our API and Playground
Link to the API documentation
Link to our Discord community to connect with fellow users and developers
1 - Introduction
Twelve Labs is excited to announce Marengo 2.7, a new state-of-the-art multimodal embedding model that achieves over 15% improvement over its predecessor Marengo 2.6.
Introduction to multi-vector video representation
Unlike text, where a single word embedding can effectively capture semantic meaning, video content is inherently more complex and multifaceted. A video clip simultaneously contains visual elements (objects, scenes, actions), temporal dynamics (motion, transitions), audio components (speech, ambient sounds, music), and often textual information (overlays, subtitles). Traditional single-vector approaches struggle to effectively compress all these diverse aspects into one representation without losing critical information. This complexity necessitates a more sophisticated approach to video understanding.
To address this complexity, Marengo 2.7 uses a unique multi-vector approach. Instead of compressing everything into a single vector, it creates separate vectors for different aspects of the video. One vector might capture what things look like (e.g., "a man in a black shirt"), another tracks movement (e.g., "waving his hand"), and another remembers what was said (e.g., "video foundation model is fun"). This approach helps the model better understand videos that contain many different types of information, leading to more accurate video analysis across all aspects - visual, motion, and audio.
Evaluated on 60+ multimodal retrieval datasets
Existing benchmarks for video understanding models often rely on detailed, narrative-style descriptions that capture the main events in a video. However, this approach doesn't reflect real-world usage patterns, where users typically make shorter, more ambiguous queries like "find the red car" or "show me the celebration scene." Users also frequently search for peripheral details, background elements, or specific objects that may only appear briefly. Additionally, queries often combine multiple modalities - visual elements with audio cues, or text overlays with specific actions. This disconnect between benchmark evaluation and actual use cases necessitated a more comprehensive evaluation approach for Marengo 2.7.
Understanding the limitations of existing benchmarks in capturing real-world use cases, we developed an extensive evaluation framework encompassing over 60 diverse datasets. This framework rigorously tests the model's capabilities across:
Generic visual understanding
Complex query comprehension
Small object detection
OCR interpretation
Logo recognition
Audio processing (verbal and non-verbal)
State-of-the-Art Performance with unparalleled Image-to-Visual Search Capabilities
Marengo 2.7 demonstrates state-of-the-art performance across all main benchmarks, with particularly remarkable achievements in image-to-visual search capabilities. While the model shows strong performance across all metrics, its performance in image object search and image logo search represent a significant leap forward in the field.
General text-to-visual search: 74.9% average performance across MSRVTT and COCO datasets, surpassing external SOTA models by 4.6%.
Motion(text)-to-visual search: 78.1% average recall in Something Something v2, surpassing external SOTA model by 30.0%.
OCR(text) search: 77.0% average performance across TextCaps and BLIP3-OCR datasets, surpassing external SOTA models by 13.4%.
Small object(text)-to-visual search: 52.7% average performance across obj365-medium, bdd-medium, and mapillary-medium datasets, surpassing external SOTA models by 10.1%.
General image-to-visual search: An outstanding 90.6% average performance across obj365-easy, obj365-medium, and LaSOT datasets, demonstrating a remarkable 35.0% improvement over external SOTA models - our biggest performance leap yet.
Logo(image)-to-visual search: An impressive 56.0% average performance across OpenLogo, ads-logo, and basketball-logo datasets, showcasing significant advancement with a 19.2% improvement over external SOTA models.
General text-to-audio search: 57.7% average performance across AudioCaps, Clotho, and GTZAN datasets, surpassing Marengo-2.6 by 7.7%.
2 - Marengo 2.7 Overview
Building upon the success of Marengo 2.6, our latest Marengo 2.7 video foundation model represents a significant advancement in multimodal video understanding. We also introduce a novel multi-vector approach that enables more precise and comprehensive video content analysis.
2.1 - Unified Framework with a Multi-Vector Architecture
At its core, Marengo-2.7 employs a Transformer-based architecture that processes video content through a single unified framework, capable of understanding:
Visual elements: fine-grained object detection, motion dynamics, temporal relationships, and appearance features
Audio elements: native speech understanding, non-verbal sound recognition, and music interpretation
A core element of Marengo-2.7 is its unique multi-vector representation. Unlike Marengo-2.6 that compress all information into a single embedding, Marengo-2.7 decomposes the raw inputs into multiple specialized vectors. Each vector independently captures distinct aspects of the video content - from visual appearance and motion dynamics to OCR text and speech patterns. This granular representation enables more nuanced and accurate multimodal search capabilities. The approach shows particular strength in detecting small objects while maintaining exceptional performance in general text-based search tasks.
2.2 - Training and Data
Training for Marengo 2.7 focuses on self-supervised learning with contrastive loss on a comprehensive multimodal dataset. Based on our business and customers’ needs, we have carefully curated and augmented an enormous and diverse dataset that's beneficial for training the model.
Additionally, we enhanced our training data through re-captioning with Pegasus, our own large video-language model. This process generated high-quality descriptions that capture world knowledge and complex motion and spatio-temporal relationships. This is based on the insight that text descriptions are extremely important in training a very robust model (Fan et.al., LaCLIP, 2023.10 and Gu et. al., RWKV-CLIP, 2024.06).
The comprehensive training data allows Marengo 2.7 to develop a robust understanding across domains and modalities. With its extensive video content, the model learns sophisticated temporal relationships and cross-modal interactions.
3 - Quantitative Evaluation
The performance of Marengo 2.7 has been extensively evaluated against leading multimodal retrieval models and specialized solutions across multiple domains on 60+ benchmark datasets. Our evaluation framework encompasses text-to-visual, image-to-visual, and text-to-audio search capabilities, providing a comprehensive assessment of the model's multimodal understanding.
3.1 - Baseline Models
We selected these strong baseline models for comparison:
Data Filtering Network-H/14-378 (Fang et al, Apple & University of Washington, 2023.09): This open-source image foundation model is based on the CLIP training objective. It was trained on 5 billion image-text pairs with a 378x378 image resolution.
InternVideo2-1B (Wang et al, OpenGVLab, 2024.08): This open-source video foundation model is based on the video ViT architecture trained with contrastive training objective. It was trained on datasets comprising 100M videos and 300M images.
(Commercial) Google Vertex Multimodal Embedding API, (multimodalembedding@001, 2024.10): This commercial API from Google Cloud provides multimodal embeddings for images, videos, and text. It leverages Google's research in multimodal understanding and was trained on their large-scale proprietary dataset.
Marengo 2.6 (Twelve Labs, 2024.03): Marengo 2.6 is a our own video foundation model trained with contrastive loss on a comprehensive multimodal dataset curated consisting of 60M videos, 500M images, and 500K audios.
3.2 - Evaluation Datasets
The evaluation framework utilizes diverse datasets:
Text-to-Visual Datasets
MSRVTT: 1,000 videos for web domain text-to-video evaluation
COCO: 5,000 images for text-to-image retrieval
Something-Something v2: 1,989 videos for motion understanding
TextCaps: 5,000 images for OCR-focused text-to-image retrieval
BLIP3-OCR: 9,687 images with multi-level OCR annotations to test text-to-OCR retrieval
Custom small object datasets: These are custom datasets we created to evaluate search queries targeting small objects (1-10% coverage) in images, which better reflect real user behavior. They include Object365-medium (10,000 images), Mapillary-medium (278 images), and BDD-medium (636 images).
Text-to-Audio Datasets
AudioCaps and Clotho: Text-to-generic audio evaluation - AudioCaps consist of 957 audios and 4785 text queries, while Clotho consist of 1045 audios and 5225 text queries.
GTZAN: Genre classification with 10 templated queries.
Image-to-Visual Datasets
Object365: Image detection dataset with objects split into "obj365-easy" (>10% image coverage) and "obj365-medium" (1-10% coverage) sets based on bounding box annotations. Object boxes were cropped to create image queries with source images as targets.
LaSOT: Video tracking dataset converted for image-to-video retrieval
OpenLogo: Object detection dataset in logo domain. We convert the dataset into image to image task by selecting 289 logo images as the query and 2039 images as targets.
Custom logo datasets: We created ads-logo (287 videos, 233 logos) and basketball-logo (300 videos, 154 logos) datasets with custom annotations to assess the model's ability to find specific logos in video content in diverse domains.
To ensure transparency and reproducibility, we will open-source our comprehensive evaluation framework for video retrieval. While our current evaluation datasets are primarily machine-generated and effectively demonstrate performance trends, they require further refinement and human validation before public release. We are actively working on polishing these datasets to ensure they meet the high standards expected for public research use.
3.3 - Text-to-Visual Search Performance
General Visual Search
In general visual search, Marengo 2.7 achieves a 74.9% average recall across two benchmark datasets. These results represent a 4.7% improvement over Marengo 2.6 and a 4.6% advantage over external SOTA models.
Motion Search
In motion search, Marengo 2.7 achieves a 78.1% average recall in Something Something v2 These results represent a 22.5% improvement over Marengo 2.6 and a 30.0% advantage over external SOTA models.
OCR Search
In OCR search, Marengo 2.7 achieves a 77.0% mean average precision across two benchmark datasets. This represents a 10.1% improvement over Marengo 2.6 and a 13.4% advantage over external SOTA models.
Small Object Search
In small object search, Marengo 2.7 achieves a 52.7% average recall across three custom benchmark datasets. These results represent a 10.14% improvement over Marengo 2.6 and a 10.08% advantage over external SOTA models.
3.4 - Image-to-Visual Search Performance
General (Small Object) Search
In object search, Marengo 2.7 achieves a 90.6% average recall across three benchmark datasets. This result shows improvements over both Marengo 2.6 (32.6% increase) and external SOTA models (35.0% increase).
Logo Search
In logo search, Marengo 2.7 achieves an average mean average precision of 56.0% across three benchmark datasets. This represents a 31.8% improvement over its predecessor and a 19.2% advantage over external SOTA models. Note that the Logo Expert Model mentioned above is Google Cloud Vision API - Detect Logos.
3.5 - Text-to-Audio Search Performance
General Audio Search
In general audio search, Marengo 2.7 achieves a 57.7% average recall across three benchmark datasets. This represents a 7.7% improvement over Marengo 2.6.
4 - Qualitative Results
To illustrate Marengo 2.7's capabilities across different search modalities, we present several representative examples that showcase its real-world performance.
Text-to-Visual (Marengo 2.7)
The model demonstrates sophisticated understanding of complex events and scenes through two examples:
A detailed sports play involving multiple actions
Query: Multiple New England Patriots pressure and block punt, ball rolls out of bounds, turnover on downs.
Top-3 Results:
Sequential visual elements in an urban setting
Query: A car is passing by BEST BUY, a Jeep dealership, and THE HOME DEPOT.
Top-3 Results:
Image-to-Video (Marengo 2.7)
Marengo 2.7 supports searching on low resolution image (64x64) while achieving remarkable result, such as finding small logos or objects in the background of the video frame. Let’s see its visual search capabilities:
Logo detection
Query (Image): Identifying the Chase bank logo in a complex viewing angle
Top-3 Results:
Object search
Query (Image): Identifying Clorox wipes on the shelf
Top-3 Results:
Text-to-Audio (Marengo 2.7)
The model's audio understanding is showcased through:
Speech comprehension: Processing and matching conversational content
Query 1: “tell me what's happening”
Top-3 Results:
Query 2: “I have devised a couple of ways to kind of give you a better idea of how each golf bag performs in its given field while standing in a golf cart.”
Top-3 Results:
Query 3: “I was planning on buying a keyboard for my mom, who likes to use a physical keyboard and has a tablet at home and at work.”
Top-3 Results:
Instrument recognition: Identifying specific musical elements (”violin sound”)
Top-3 Results:
These examples demonstrate Marengo 2.7's ability to handle diverse query types while maintaining high precision across different modalities.
5 - Limitations and Future Work
While Marengo 2.7 demonstrates significant improvements across multiple modalities, several challenges remain in achieving comprehensive video understanding.
Complex Scene Understanding
While the excels at identifying primary actions and objects, it may miss subtle background activities or parallel events that occur simultaneously in the video.
Visual Exact Match Challenges
The model can sometimes struggle with finding exact visual matches, particularly when searching for specific instances of objects or people that may appear multiple times in slightly different contexts.
Query Interpretation
While Marengo 2.7 handles most queries effectively, it can encounter challenges with:
Highly compositional queries involving multiple temporal relationships
Complex negation patterns beyond simple cases
Queries requiring abstract reasoning or world knowledge
Performance in Logo Search, Conversation Search, and OCR Search
Additionally, Marengo 2.7 shows limitations in text-to-logo search scenarios, particularly when dealing with logos occupy less than 1% of the frame or appear in challenging viewing angles.
In conversation and OCR search, the model struggles with heavily accented speech, overlapping conversations, and text in unusual fonts or orientations. These challenges are particularly evident in real-world scenarios with poor lighting conditions or complex backgrounds.
These limitations represent natural areas for future research and development as we continue to advance the capabilities of multimodal video understanding. Our ongoing work focuses on addressing these challenges while maintaining the model's current strengths in cross-modal understanding and temporal reasoning.
6 - Conclusion
Marengo 2.7 represents a significant leap forward in multimodal video understanding, demonstrating substantial improvements across visual, audio, and text modalities. Through its innovative multi-vector approach and comprehensive evaluation framework, we've shown that it's possible to achieve state-of-the-art performance in complex video understanding tasks while maintaining high precision across different use cases.
To support transparency and reproducibility in the field, we will be releasing a detailed technical report along with our comprehensive evaluation framework. This framework, which includes testing across 60+ datasets, will be open-sourced and regularly maintained to enable researchers and practitioners to validate our results and contribute to advancing multimodal video understanding.
Acknowledgements
This is a joint team effort across multiple functional groups including science, engineering, product, business development, and operation. It is co-authored by the Marengo team under Twelve Labs Research Science division.
Resources
Link to sign up and play with our API and Playground
Link to the API documentation
Link to our Discord community to connect with fellow users and developers
1 - Introduction
Twelve Labs is excited to announce Marengo 2.7, a new state-of-the-art multimodal embedding model that achieves over 15% improvement over its predecessor Marengo 2.6.
Introduction to multi-vector video representation
Unlike text, where a single word embedding can effectively capture semantic meaning, video content is inherently more complex and multifaceted. A video clip simultaneously contains visual elements (objects, scenes, actions), temporal dynamics (motion, transitions), audio components (speech, ambient sounds, music), and often textual information (overlays, subtitles). Traditional single-vector approaches struggle to effectively compress all these diverse aspects into one representation without losing critical information. This complexity necessitates a more sophisticated approach to video understanding.
To address this complexity, Marengo 2.7 uses a unique multi-vector approach. Instead of compressing everything into a single vector, it creates separate vectors for different aspects of the video. One vector might capture what things look like (e.g., "a man in a black shirt"), another tracks movement (e.g., "waving his hand"), and another remembers what was said (e.g., "video foundation model is fun"). This approach helps the model better understand videos that contain many different types of information, leading to more accurate video analysis across all aspects - visual, motion, and audio.
Evaluated on 60+ multimodal retrieval datasets
Existing benchmarks for video understanding models often rely on detailed, narrative-style descriptions that capture the main events in a video. However, this approach doesn't reflect real-world usage patterns, where users typically make shorter, more ambiguous queries like "find the red car" or "show me the celebration scene." Users also frequently search for peripheral details, background elements, or specific objects that may only appear briefly. Additionally, queries often combine multiple modalities - visual elements with audio cues, or text overlays with specific actions. This disconnect between benchmark evaluation and actual use cases necessitated a more comprehensive evaluation approach for Marengo 2.7.
Understanding the limitations of existing benchmarks in capturing real-world use cases, we developed an extensive evaluation framework encompassing over 60 diverse datasets. This framework rigorously tests the model's capabilities across:
Generic visual understanding
Complex query comprehension
Small object detection
OCR interpretation
Logo recognition
Audio processing (verbal and non-verbal)
State-of-the-Art Performance with unparalleled Image-to-Visual Search Capabilities
Marengo 2.7 demonstrates state-of-the-art performance across all main benchmarks, with particularly remarkable achievements in image-to-visual search capabilities. While the model shows strong performance across all metrics, its performance in image object search and image logo search represent a significant leap forward in the field.
General text-to-visual search: 74.9% average performance across MSRVTT and COCO datasets, surpassing external SOTA models by 4.6%.
Motion(text)-to-visual search: 78.1% average recall in Something Something v2, surpassing external SOTA model by 30.0%.
OCR(text) search: 77.0% average performance across TextCaps and BLIP3-OCR datasets, surpassing external SOTA models by 13.4%.
Small object(text)-to-visual search: 52.7% average performance across obj365-medium, bdd-medium, and mapillary-medium datasets, surpassing external SOTA models by 10.1%.
General image-to-visual search: An outstanding 90.6% average performance across obj365-easy, obj365-medium, and LaSOT datasets, demonstrating a remarkable 35.0% improvement over external SOTA models - our biggest performance leap yet.
Logo(image)-to-visual search: An impressive 56.0% average performance across OpenLogo, ads-logo, and basketball-logo datasets, showcasing significant advancement with a 19.2% improvement over external SOTA models.
General text-to-audio search: 57.7% average performance across AudioCaps, Clotho, and GTZAN datasets, surpassing Marengo-2.6 by 7.7%.
2 - Marengo 2.7 Overview
Building upon the success of Marengo 2.6, our latest Marengo 2.7 video foundation model represents a significant advancement in multimodal video understanding. We also introduce a novel multi-vector approach that enables more precise and comprehensive video content analysis.
2.1 - Unified Framework with a Multi-Vector Architecture
At its core, Marengo-2.7 employs a Transformer-based architecture that processes video content through a single unified framework, capable of understanding:
Visual elements: fine-grained object detection, motion dynamics, temporal relationships, and appearance features
Audio elements: native speech understanding, non-verbal sound recognition, and music interpretation
A core element of Marengo-2.7 is its unique multi-vector representation. Unlike Marengo-2.6 that compress all information into a single embedding, Marengo-2.7 decomposes the raw inputs into multiple specialized vectors. Each vector independently captures distinct aspects of the video content - from visual appearance and motion dynamics to OCR text and speech patterns. This granular representation enables more nuanced and accurate multimodal search capabilities. The approach shows particular strength in detecting small objects while maintaining exceptional performance in general text-based search tasks.
2.2 - Training and Data
Training for Marengo 2.7 focuses on self-supervised learning with contrastive loss on a comprehensive multimodal dataset. Based on our business and customers’ needs, we have carefully curated and augmented an enormous and diverse dataset that's beneficial for training the model.
Additionally, we enhanced our training data through re-captioning with Pegasus, our own large video-language model. This process generated high-quality descriptions that capture world knowledge and complex motion and spatio-temporal relationships. This is based on the insight that text descriptions are extremely important in training a very robust model (Fan et.al., LaCLIP, 2023.10 and Gu et. al., RWKV-CLIP, 2024.06).
The comprehensive training data allows Marengo 2.7 to develop a robust understanding across domains and modalities. With its extensive video content, the model learns sophisticated temporal relationships and cross-modal interactions.
3 - Quantitative Evaluation
The performance of Marengo 2.7 has been extensively evaluated against leading multimodal retrieval models and specialized solutions across multiple domains on 60+ benchmark datasets. Our evaluation framework encompasses text-to-visual, image-to-visual, and text-to-audio search capabilities, providing a comprehensive assessment of the model's multimodal understanding.
3.1 - Baseline Models
We selected these strong baseline models for comparison:
Data Filtering Network-H/14-378 (Fang et al, Apple & University of Washington, 2023.09): This open-source image foundation model is based on the CLIP training objective. It was trained on 5 billion image-text pairs with a 378x378 image resolution.
InternVideo2-1B (Wang et al, OpenGVLab, 2024.08): This open-source video foundation model is based on the video ViT architecture trained with contrastive training objective. It was trained on datasets comprising 100M videos and 300M images.
(Commercial) Google Vertex Multimodal Embedding API, (multimodalembedding@001, 2024.10): This commercial API from Google Cloud provides multimodal embeddings for images, videos, and text. It leverages Google's research in multimodal understanding and was trained on their large-scale proprietary dataset.
Marengo 2.6 (Twelve Labs, 2024.03): Marengo 2.6 is a our own video foundation model trained with contrastive loss on a comprehensive multimodal dataset curated consisting of 60M videos, 500M images, and 500K audios.
3.2 - Evaluation Datasets
The evaluation framework utilizes diverse datasets:
Text-to-Visual Datasets
MSRVTT: 1,000 videos for web domain text-to-video evaluation
COCO: 5,000 images for text-to-image retrieval
Something-Something v2: 1,989 videos for motion understanding
TextCaps: 5,000 images for OCR-focused text-to-image retrieval
BLIP3-OCR: 9,687 images with multi-level OCR annotations to test text-to-OCR retrieval
Custom small object datasets: These are custom datasets we created to evaluate search queries targeting small objects (1-10% coverage) in images, which better reflect real user behavior. They include Object365-medium (10,000 images), Mapillary-medium (278 images), and BDD-medium (636 images).
Text-to-Audio Datasets
AudioCaps and Clotho: Text-to-generic audio evaluation - AudioCaps consist of 957 audios and 4785 text queries, while Clotho consist of 1045 audios and 5225 text queries.
GTZAN: Genre classification with 10 templated queries.
Image-to-Visual Datasets
Object365: Image detection dataset with objects split into "obj365-easy" (>10% image coverage) and "obj365-medium" (1-10% coverage) sets based on bounding box annotations. Object boxes were cropped to create image queries with source images as targets.
LaSOT: Video tracking dataset converted for image-to-video retrieval
OpenLogo: Object detection dataset in logo domain. We convert the dataset into image to image task by selecting 289 logo images as the query and 2039 images as targets.
Custom logo datasets: We created ads-logo (287 videos, 233 logos) and basketball-logo (300 videos, 154 logos) datasets with custom annotations to assess the model's ability to find specific logos in video content in diverse domains.
To ensure transparency and reproducibility, we will open-source our comprehensive evaluation framework for video retrieval. While our current evaluation datasets are primarily machine-generated and effectively demonstrate performance trends, they require further refinement and human validation before public release. We are actively working on polishing these datasets to ensure they meet the high standards expected for public research use.
3.3 - Text-to-Visual Search Performance
General Visual Search
In general visual search, Marengo 2.7 achieves a 74.9% average recall across two benchmark datasets. These results represent a 4.7% improvement over Marengo 2.6 and a 4.6% advantage over external SOTA models.
Motion Search
In motion search, Marengo 2.7 achieves a 78.1% average recall in Something Something v2 These results represent a 22.5% improvement over Marengo 2.6 and a 30.0% advantage over external SOTA models.
OCR Search
In OCR search, Marengo 2.7 achieves a 77.0% mean average precision across two benchmark datasets. This represents a 10.1% improvement over Marengo 2.6 and a 13.4% advantage over external SOTA models.
Small Object Search
In small object search, Marengo 2.7 achieves a 52.7% average recall across three custom benchmark datasets. These results represent a 10.14% improvement over Marengo 2.6 and a 10.08% advantage over external SOTA models.
3.4 - Image-to-Visual Search Performance
General (Small Object) Search
In object search, Marengo 2.7 achieves a 90.6% average recall across three benchmark datasets. This result shows improvements over both Marengo 2.6 (32.6% increase) and external SOTA models (35.0% increase).
Logo Search
In logo search, Marengo 2.7 achieves an average mean average precision of 56.0% across three benchmark datasets. This represents a 31.8% improvement over its predecessor and a 19.2% advantage over external SOTA models. Note that the Logo Expert Model mentioned above is Google Cloud Vision API - Detect Logos.
3.5 - Text-to-Audio Search Performance
General Audio Search
In general audio search, Marengo 2.7 achieves a 57.7% average recall across three benchmark datasets. This represents a 7.7% improvement over Marengo 2.6.
4 - Qualitative Results
To illustrate Marengo 2.7's capabilities across different search modalities, we present several representative examples that showcase its real-world performance.
Text-to-Visual (Marengo 2.7)
The model demonstrates sophisticated understanding of complex events and scenes through two examples:
A detailed sports play involving multiple actions
Query: Multiple New England Patriots pressure and block punt, ball rolls out of bounds, turnover on downs.
Top-3 Results:
Sequential visual elements in an urban setting
Query: A car is passing by BEST BUY, a Jeep dealership, and THE HOME DEPOT.
Top-3 Results:
Image-to-Video (Marengo 2.7)
Marengo 2.7 supports searching on low resolution image (64x64) while achieving remarkable result, such as finding small logos or objects in the background of the video frame. Let’s see its visual search capabilities:
Logo detection
Query (Image): Identifying the Chase bank logo in a complex viewing angle
Top-3 Results:
Object search
Query (Image): Identifying Clorox wipes on the shelf
Top-3 Results:
Text-to-Audio (Marengo 2.7)
The model's audio understanding is showcased through:
Speech comprehension: Processing and matching conversational content
Query 1: “tell me what's happening”
Top-3 Results:
Query 2: “I have devised a couple of ways to kind of give you a better idea of how each golf bag performs in its given field while standing in a golf cart.”
Top-3 Results:
Query 3: “I was planning on buying a keyboard for my mom, who likes to use a physical keyboard and has a tablet at home and at work.”
Top-3 Results:
Instrument recognition: Identifying specific musical elements (”violin sound”)
Top-3 Results:
These examples demonstrate Marengo 2.7's ability to handle diverse query types while maintaining high precision across different modalities.
5 - Limitations and Future Work
While Marengo 2.7 demonstrates significant improvements across multiple modalities, several challenges remain in achieving comprehensive video understanding.
Complex Scene Understanding
While the excels at identifying primary actions and objects, it may miss subtle background activities or parallel events that occur simultaneously in the video.
Visual Exact Match Challenges
The model can sometimes struggle with finding exact visual matches, particularly when searching for specific instances of objects or people that may appear multiple times in slightly different contexts.
Query Interpretation
While Marengo 2.7 handles most queries effectively, it can encounter challenges with:
Highly compositional queries involving multiple temporal relationships
Complex negation patterns beyond simple cases
Queries requiring abstract reasoning or world knowledge
Performance in Logo Search, Conversation Search, and OCR Search
Additionally, Marengo 2.7 shows limitations in text-to-logo search scenarios, particularly when dealing with logos occupy less than 1% of the frame or appear in challenging viewing angles.
In conversation and OCR search, the model struggles with heavily accented speech, overlapping conversations, and text in unusual fonts or orientations. These challenges are particularly evident in real-world scenarios with poor lighting conditions or complex backgrounds.
These limitations represent natural areas for future research and development as we continue to advance the capabilities of multimodal video understanding. Our ongoing work focuses on addressing these challenges while maintaining the model's current strengths in cross-modal understanding and temporal reasoning.
6 - Conclusion
Marengo 2.7 represents a significant leap forward in multimodal video understanding, demonstrating substantial improvements across visual, audio, and text modalities. Through its innovative multi-vector approach and comprehensive evaluation framework, we've shown that it's possible to achieve state-of-the-art performance in complex video understanding tasks while maintaining high precision across different use cases.
To support transparency and reproducibility in the field, we will be releasing a detailed technical report along with our comprehensive evaluation framework. This framework, which includes testing across 60+ datasets, will be open-sourced and regularly maintained to enable researchers and practitioners to validate our results and contribute to advancing multimodal video understanding.
Acknowledgements
This is a joint team effort across multiple functional groups including science, engineering, product, business development, and operation. It is co-authored by the Marengo team under Twelve Labs Research Science division.
Resources
Link to sign up and play with our API and Playground
Link to the API documentation
Link to our Discord community to connect with fellow users and developers
Related articles








© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved
© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved
© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved