Embed
NEW
NEW
NEW
Vectorize everything.
Do anything.
Turn rich video data – including image, text, and audio – into vectors and new possibilities. Easily build semantic search, hybrid search, recommender systems, anomaly detection, and more.
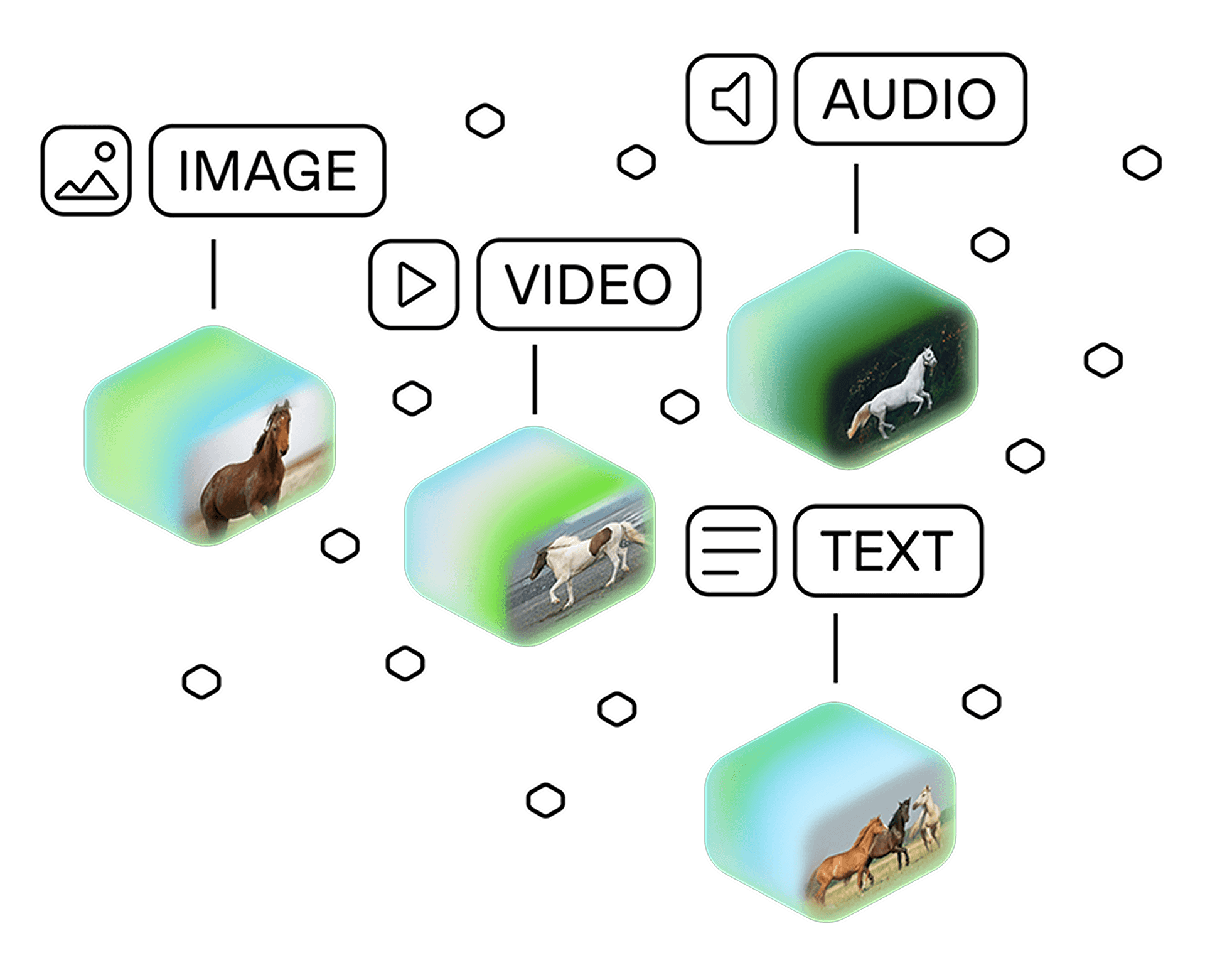
Embed 01
Multimodal doesn’t have to mean multi-model.
No more piecing together siloed solutions for image, text, audio and video. Support all modalities and turn rich video data into vectors in the same space.
Embed 01
Multimodal doesn’t have to mean multi-model.
No more piecing together siloed solutions for image, text, audio and video. Support all modalities and turn rich video data into vectors in the same space.
Embed 02
Simple doesn’t have to mean generic.
Your data is unique – your models should be, too. Fine-tune our models easily for your domain until they deliver unparalleled performance.
Embed 02
Simple doesn’t have to mean generic.
Your data is unique – your models should be, too. Fine-tune our models easily for your domain until they deliver unparalleled performance.

Embed 03
Better output with shorter processing times.
With native video support, Embed API reduces processing time, increasing throughput, and saving you time and money.
Embed 03
Better output with shorter processing times.
With native video support, Embed API reduces processing time, increasing throughput, and saving you time and money.
For everything your video can do.

RAG pairing
Pair our models with your RAG pipeline to retrieve relevant information and improve data output.

High-quality training data
Transform workflows with embeddings to create training data, improve data quality, and reduce manual labeling needs.

Training models
Use embeddings to improve data quality when training large language models.

Anomaly detection
Codentify anomalies – for example, detect and remove corrupt videos that only display a black background – to enhance data quality.
For everything your video can do.
RAG pairing
Pair our models with your RAG pipeline to retrieve relevant information and improve data output.
High-quality training data
Transform workflows with embeddings to create training data, improve data quality, and reduce manual labeling needs.
Customer Search
Let customers easily find any video moment within your platform.
Asset Management
Comb through petabytes of data using natural language queries.
For everything your video can do.
RAG pairing
Pair our models with your RAG pipeline to retrieve relevant information and improve data output.
High-quality training data
Transform workflows with embeddings to create training data, improve data quality, and reduce manual labeling needs.
Customer Search
Let customers easily find any video moment within your platform.
Asset Management
Comb through petabytes of data using natural language queries.
Sample Apps
node
PYTHON
PYTHON
Contextual and Personalized Ads
A tool for analyzing source footage, summarizing content, and recommending ads based on the footage's context and emotional tone.
Try this sample app
Try this sample app
Try this sample app
PYTHON
PYTHON
PYTHON
Recommendations using Multimodal Embeddings
Start exploring videos and discovering similar content powered by TwelveLabs Multimodal Embeddings.
Try this sample app
Try this sample app
Try this sample app
Python
Node
from twelvelabs import TwelveLabs from twelvelabs.models.embed import EmbeddingsTask, SegmentEmbedding client = TwelveLabs("<YOUR_API_KEY>") # Create a video embedding task for your video task = client.embed.task.create( model_name="Marengo-retrieval-2.7", video_url: "<YOUR_VIDEO_URL>" ) print(f"Created task: id={task.id} model_name={task.model_name} status={task.status}") # Wait for embedding task to finish status = task.wait_for_done() print(f"Embedding done: {status}") # Retrieve the video embeddings task = task.retrieve() # Print the embeddings if task.video_embedding is not None and task.video_embedding.segments is not None: for segment in task.video_embedding.segments: print( f" embedding_scope={segment.embedding_scope} start_offset_sec={segment.start_offset_sec} end_offset_sec={segment.end_offset_sec}" ) print(f" embeddings: {", ".join(str(segment.embeddings_float))}")
Python
Node
from twelvelabs import TwelveLabs from twelvelabs.models.embed import EmbeddingsTask, SegmentEmbedding client = TwelveLabs("<YOUR_API_KEY>") # Create a video embedding task for your video task = client.embed.task.create( model_name="Marengo-retrieval-2.7", video_url: "<YOUR_VIDEO_URL>" ) print(f"Created task: id={task.id} model_name={task.model_name} status={task.status}") # Wait for embedding task to finish status = task.wait_for_done() print(f"Embedding done: {status}") # Retrieve the video embeddings task = task.retrieve() # Print the embeddings if task.video_embedding is not None and task.video_embedding.segments is not None: for segment in task.video_embedding.segments: print( f" embedding_scope={segment.embedding_scope} start_offset_sec={segment.start_offset_sec} end_offset_sec={segment.end_offset_sec}" ) print(f" embeddings: {", ".join(str(segment.embeddings_float))}")
Python
Node
from twelvelabs import TwelveLabs from twelvelabs.models.embed import EmbeddingsTask, SegmentEmbedding client = TwelveLabs("<YOUR_API_KEY>") # Create a video embedding task for your video task = client.embed.task.create( model_name="Marengo-retrieval-2.7", video_url: "<YOUR_VIDEO_URL>" ) print(f"Created task: id={task.id} model_name={task.model_name} status={task.status}") # Wait for embedding task to finish status = task.wait_for_done() print(f"Embedding done: {status}") # Retrieve the video embeddings task = task.retrieve() # Print the embeddings if task.video_embedding is not None and task.video_embedding.segments is not None: for segment in task.video_embedding.segments: print( f" embedding_scope={segment.embedding_scope} start_offset_sec={segment.start_offset_sec} end_offset_sec={segment.end_offset_sec}" ) print(f" embeddings: {", ".join(str(segment.embeddings_float))}")
Integrate with your personalized SDK — and your vision.
Deploy your custom-trained model on any cloud. See and surface everything in your video, then go beyond with AI that can realize your most game-changing ideas.

From video to vector to possibility.
Try out TwelveLabs on your own videos to see what video-native AI can do.
From video to vector to possibility.
Try out TwelveLabs on your own videos to see what video-native AI can do.
From video to vector to possibility.
Try out TwelveLabs on your own videos to see what video-native AI can do.


© 2021
-
2025
TwelveLabs, Inc. All Rights Reserved
© 2021
-
2025
TwelveLabs, Inc. All Rights Reserved
© 2021
-
2025
TwelveLabs, Inc. All Rights Reserved
For everything your video can do.
RAG pairing
Pair our models with your RAG pipeline to retrieve relevant information and improve data output.
High-quality training data
Transform workflows with embeddings to create training data, improve data quality, and reduce manual labeling needs.
Customer Search
Let customers easily find any video moment within your platform.
Asset Management
Comb through petabytes of data using natural language queries.
For everything your video can do.
RAG pairing
Pair our models with your RAG pipeline to retrieve relevant information and improve data output.
High-quality training data
Transform workflows with embeddings to create training data, improve data quality, and reduce manual labeling needs.
Customer Search
Let customers easily find any video moment within your platform.
Asset Management
Comb through petabytes of data using natural language queries.