" height="9.18705px" id="AiyYyR90G" transform="translate(3.406 3.406)" width="9.18685px"/></svg>)

" height="1.90314px" id="wtDTm6bEW" transform="translate(26.225 0)" width="2.4723000000000006px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.344 C 1.995 1.653 1.746 1.903 1.438 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="GnmDnNra_" transform="translate(36.408 2.728)" width="1.9953000000000003px"/><path d="M 6.224 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.224 1.903 C 6.531 1.903 6.781 1.653 6.781 1.344 L 6.781 0.559 C 6.781 0.25 6.531 0 6.224 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="hKTQ3dbw4" transform="translate(34.261 5.456)" width="6.781100000000002px"/><path d="M 6.955 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 6.955 1.903 C 7.263 1.903 7.513 1.653 7.513 1.344 L 7.513 0.559 C 7.513 0.25 7.263 0 6.955 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="G1Zzk9CUU" transform="translate(28.298 8.243)" width="7.513100000000001px"/><path d="M 7.123 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 7.123 1.903 C 7.431 1.903 7.681 1.653 7.681 1.344 L 7.681 0.559 C 7.681 0.25 7.431 0 7.123 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="fm7cHxIfJ" transform="translate(0 10.972)" width="7.68067px"/><path d="M 13.447 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 13.447 1.903 C 13.755 1.903 14.004 1.653 14.004 1.344 L 14.004 0.559 C 14.004 0.25 13.755 0 13.447 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="LowSwDrtg" transform="translate(9.552 10.972)" width="14.0044px"/><path d="M 0.558 0 L 8.212 0 C 8.52 0 8.77 0.25 8.77 0.559 L 8.77 1.344 C 8.77 1.653 8.52 1.903 8.212 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="xRiKc2od7" transform="translate(27.041 10.972)" width="8.769900000000003px"/><path d="M 0.557 0 L 5.4 0 C 5.708 0 5.958 0.25 5.958 0.559 L 5.958 1.344 C 5.958 1.653 5.708 1.903 5.4 1.903 L 0.557 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="JWdNVicde" transform="translate(36.796 8.243)" width="5.957599999999999px"/><path d="M 1.438 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 1.438 1.903 C 1.746 1.903 1.995 1.653 1.995 1.344 L 1.995 0.559 C 1.995 0.25 1.746 0 1.438 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="RfFYVCT_T" transform="translate(28.717 5.456)" width="1.9953000000000003px"/><path d="M 0.558 0 L 2.895 0 C 3.203 0 3.453 0.25 3.453 0.559 L 3.453 1.406 C 3.453 1.714 3.203 1.964 2.895 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="dngJ6MU2p" transform="translate(16.183 24.582)" width="3.4525000000000006px"/><path d="M 1.706 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.706 1.964 C 2.014 1.964 2.263 1.714 2.263 1.406 L 2.263 0.559 C 2.263 0.25 2.014 0 1.706 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="N_fstvKmR" transform="translate(22.18 24.582)" width="2.2631999999999977px"/><path d="M 0.558 0 L 5.544 0 C 5.852 0 6.101 0.25 6.101 0.559 L 6.101 1.406 C 6.101 1.714 5.852 1.964 5.544 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="t55XLYcgb" transform="translate(25.486 24.582)" width="6.101399999999998px"/><path d="M 1.976 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 1.976 1.964 C 2.284 1.964 2.533 1.714 2.533 1.406 L 2.533 0.559 C 2.533 0.25 2.284 0 1.976 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="ZrEKTVTAe" transform="translate(28.542 21.854)" width="2.5334000000000003px"/><path d="M 0.557 0 L 1.438 0 C 1.746 0 1.995 0.25 1.995 0.559 L 1.995 1.406 C 1.995 1.714 1.746 1.964 1.438 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Z0fPTp9aR" transform="translate(11.425 24.582)" width="1.9953000000000003px"/><path d="M 0 0.559 C 0 0.251 0.251 0 0.558 0 L 1.438 0 C 1.745 0 1.995 0.251 1.995 0.559 L 1.995 1.405 C 1.995 1.713 1.745 1.964 1.438 1.964 L 0.558 1.964 C 0.251 1.964 0 1.713 0 1.405 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Tj_PDHFDh" transform="translate(20.635 27.308)" width="1.9954px"/><path d="M 0.557 0 L 1.342 0 C 1.65 0 1.899 0.25 1.899 0.559 L 1.899 1.406 C 1.899 1.714 1.65 1.964 1.342 1.964 L 0.557 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.557 0 Z" fill="rgb(29, 28, 27)" height="1.9643000000000015px" id="AYq9dXkKz" transform="translate(18.686 30.036)" width="1.8994px"/><path d="M 0.558 0 L 5.768 0 C 6.076 0 6.326 0.25 6.326 0.559 L 6.326 1.344 C 6.326 1.653 6.076 1.903 5.768 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="rspevfJcx" transform="translate(12.157 8.243)" width="6.325900000000001px"/><path d="M 3.285 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.285 1.903 C 3.593 1.903 3.842 1.653 3.842 1.344 L 3.842 0.559 C 3.842 0.25 3.593 0 3.285 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="XRUAhGnph" transform="translate(23.887 2.728)" width="3.8424000000000014px"/><path d="M 0.558 0 L 5.644 0 C 5.952 0 6.202 0.25 6.202 0.559 L 6.202 1.344 C 6.202 1.653 5.952 1.903 5.644 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9031500000000001px" id="VsaVVIfke" transform="translate(21.528 5.456)" width="6.201600000000003px"/><path d="M 3.06 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.344 C 0 1.653 0.25 1.903 0.558 1.903 L 3.06 1.903 C 3.369 1.903 3.618 1.653 3.618 1.344 L 3.618 0.559 C 3.618 0.25 3.369 0 3.06 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="wiAKEgyId" transform="translate(40.819 10.972)" width="3.6182000000000016px"/><path d="M 0.558 0 L 17.318 0 C 17.626 0 17.875 0.25 17.875 0.559 L 17.875 1.345 C 17.875 1.653 17.626 1.903 17.318 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.345 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="FIE0ufK9m" transform="translate(6.666 13.7)" width="17.87506px"/><path d="M 6.426 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.426 1.903 C 6.734 1.903 6.984 1.653 6.984 1.345 L 6.984 0.559 C 6.984 0.25 6.734 0 6.426 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="ut9UWny3L" transform="translate(22.892 19.156)" width="6.983599999999999px"/><path d="M 0.558 0 L 22.151 0 C 22.459 0 22.709 0.25 22.709 0.559 L 22.709 1.344 C 22.709 1.653 22.459 1.903 22.151 1.903 L 0.558 1.903 C 0.25 1.903 0 1.653 0 1.344 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.9030999999999985px" id="VULnffgbk" transform="translate(9.552 16.428)" width="22.7089px"/><path d="M 7.886 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 7.886 1.903 C 8.194 1.903 8.443 1.653 8.443 1.345 L 8.443 0.559 C 8.443 0.25 8.194 0 7.886 0 Z" fill="rgb(29, 28, 27)" height="1.9032000000000018px" id="adZTYr4MR" transform="translate(6.078 19.156)" width="8.44303px"/><path d="M 0.558 0 L 2.211 0 C 2.519 0 2.769 0.25 2.769 0.559 L 2.769 1.406 C 2.769 1.714 2.519 1.964 2.211 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="bwdUdEmCH" transform="translate(13.784 21.854)" width="2.768600000000001px"/><path d="M 2.424 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.406 C 0 1.714 0.25 1.964 0.558 1.964 L 2.424 1.964 C 2.732 1.964 2.982 1.714 2.982 1.406 L 2.982 0.559 C 2.982 0.25 2.732 0 2.424 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="PUvesMJEj" transform="translate(23.556 21.854)" width="2.982199999999999px"/><path d="M 0.558 0 L 2.241 0 C 2.55 0 2.799 0.25 2.799 0.559 L 2.799 1.406 C 2.799 1.714 2.55 1.964 2.241 1.964 L 0.558 1.964 C 0.25 1.964 0 1.714 0 1.406 L 0 0.559 C 0 0.25 0.25 0 0.558 0 Z" fill="rgb(29, 28, 27)" height="1.964299999999998px" id="Wo2W7J3Zj" transform="translate(8.672 21.854)" width="2.799050000000001px"/><path d="M 6.661 0 L 0.558 0 C 0.25 0 0 0.25 0 0.559 L 0 1.345 C 0 1.653 0.25 1.903 0.558 1.903 L 6.661 1.903 C 6.969 1.903 7.219 1.653 7.219 1.345 L 7.219 0.559 C 7.219 0.25 6.969 0 6.661 0 Z" fill="rgb(29, 28, 27)" height="1.9032px" id="PpPVZXp9j" transform="translate(27.041 13.7)" width="7.218900000000001px"/><path d="M 0.621 1.905 C 0.218 1.905 0 1.687 0 1.283 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 11.225 0 C 11.628 0 11.846 0.218 11.846 0.622 L 11.846 1.283 C 11.846 1.687 11.628 1.905 11.225 1.905 L 6.934 1.905 L 6.934 14.926 C 6.934 15.33 6.716 15.548 6.313 15.548 L 5.537 15.548 C 5.134 15.548 4.916 15.33 4.916 14.926 L 4.916 1.905 Z" fill="rgb(29, 28, 27)" height="15.54825px" id="xr32fxeO6" transform="translate(52.177 8.243)" width="11.845599999999997px"/><path d="M 0.621 0 C 0.218 0 0 0.218 0 0.622 L 0 14.924 C 0 15.328 0.218 15.546 0.621 15.546 L 1.357 15.546 C 1.76 15.546 1.978 15.328 1.978 14.924 L 1.978 0.622 C 1.978 0.218 1.76 0 1.357 0 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="oSsO_UPVN" transform="translate(90.476 8.243)" width="1.9779000000000053px"/><path d="M 0.62 15.546 C 0.217 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.217 0 0.62 0 L 1.396 0 C 1.799 0 2.017 0.218 2.017 0.622 L 2.017 13.632 L 8.981 13.632 C 9.384 13.632 9.602 13.85 9.602 14.254 L 9.602 14.924 C 9.602 15.328 9.384 15.546 8.981 15.546 Z" fill="rgb(29, 28, 27)" height="15.546050000000001px" id="Sgj4z5osO" transform="translate(116.749 8.243)" width="9.602000000000004px"/><path d="M 1.974 14.924 C 1.974 15.328 1.756 15.546 1.353 15.546 L 0.621 15.546 C 0.218 15.546 0 15.328 0 14.924 L 0 0.622 C 0 0.218 0.218 0 0.621 0 L 1.357 0 C 1.76 0 1.978 0.218 1.978 0.622 L 1.978 5.747 C 2.634 4.721 3.806 4.079 5.309 4.079 C 8.18 4.079 10.356 6.358 10.356 9.948 C 10.356 13.538 8.18 15.817 5.309 15.817 C 3.801 15.817 2.627 15.175 1.971 14.145 L 1.971 14.922 Z M 8.36 9.95 C 8.36 7.362 6.881 5.928 5.121 5.928 C 3.361 5.928 1.863 7.362 1.863 9.95 C 1.863 12.539 3.361 13.972 5.121 13.972 C 6.881 13.972 8.36 12.539 8.36 9.95 Z" fill="rgb(29, 28, 27)" height="15.81665px" id="q13jjj7xd" transform="translate(138.401 8.243)" width="10.355999999999995px"/><path d="M 4.457 11.738 C 0.961 11.738 -0.019 9.872 0 8.318 C 0.005 7.929 0.253 7.735 0.645 7.735 L 1.344 7.735 C 1.748 7.735 1.922 7.949 1.961 8.352 C 2.063 9.315 2.693 9.907 4.433 9.907 C 6.174 9.907 7.012 9.269 7.012 8.289 C 7.012 7.425 6.522 7.108 5.305 6.899 L 3.209 6.539 C 1.453 6.238 0.29 5.247 0.29 3.468 C 0.29 1.467 1.774 0 4.518 0 C 7.263 0 8.838 1.491 8.814 3.23 C 8.81 3.614 8.553 3.808 8.165 3.808 L 7.457 3.808 C 7.054 3.808 6.908 3.595 6.851 3.202 C 6.749 2.477 6.159 1.818 4.518 1.818 C 2.878 1.818 2.249 2.508 2.249 3.403 C 2.249 4.175 2.695 4.516 3.81 4.714 L 5.906 5.083 C 7.72 5.404 8.98 6.292 8.98 8.198 C 8.98 9.976 7.908 11.74 4.455 11.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="tJ8syeWTW" transform="translate(150.024 12.325)" width="8.980269730401375px"/><path d="M 9.146 7.997 C 9.146 8.813 9.175 9.983 9.282 10.799 C 9.334 11.223 9.155 11.465 8.728 11.465 L 8.068 11.465 C 7.685 11.465 7.467 11.319 7.428 11.022 L 7.317 10.181 C 6.724 11.157 5.565 11.659 4.145 11.659 C 1.579 11.659 0 10.142 0 8.078 C 0 6.27 1.27 5.157 3.433 5.002 L 6.589 4.78 C 7.162 4.741 7.186 4.688 7.186 4.153 L 7.186 3.682 C 7.186 2.438 6.434 1.807 4.79 1.807 C 3.145 1.807 2.472 2.425 2.405 3.289 C 2.376 3.697 2.235 3.916 1.823 3.916 L 1.067 3.916 C 0.675 3.916 0.427 3.717 0.422 3.328 C 0.407 1.51 1.74 0 4.792 0 C 7.798 0 9.162 1.427 9.155 3.736 Z M 7.188 7.298 L 7.188 6.244 C 6.955 6.327 6.678 6.386 6.363 6.415 L 3.598 6.676 C 2.59 6.775 1.997 7.163 1.997 8.099 L 1.999 8.099 C 1.999 9.188 2.886 9.97 4.4 9.97 C 6.169 9.97 7.188 8.9 7.188 7.298 Z" fill="rgb(29, 28, 27)" height="11.658999999999999px" id="QPESIZvku" transform="translate(126.854 12.325)" width="9.290755130109668px"/><path d="M 5.224 0 C 8.313 0 10.295 2.255 10.295 5.456 L 10.295 5.694 C 10.295 6.098 10.077 6.316 9.674 6.316 L 1.998 6.316 C 2.168 8.547 3.447 9.898 5.407 9.898 C 6.768 9.898 7.598 9.363 7.934 8.431 C 8.06 8.078 8.243 7.892 8.618 7.892 L 9.33 7.892 C 9.746 7.892 9.994 8.125 9.923 8.538 C 9.598 10.433 7.834 11.74 5.409 11.74 L 5.407 11.738 C 2.168 11.738 0 9.424 0 5.797 C 0 2.169 2.135 0 5.224 0 Z M 5.222 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 L 8.282 4.64 C 8.054 2.842 6.949 1.74 5.222 1.74 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="PKmyQkwJE" transform="translate(104.541 12.325)" width="10.295000000000002px"/><path d="M 4.459 11.194 C 4.099 11.194 3.877 11.039 3.746 10.703 L 0.091 1.021 C -0.024 0.72 -0.031 0.511 0.076 0.297 C 0.178 0.094 0.381 0 0.732 0 L 1.274 0 C 1.633 0 1.86 0.155 1.986 0.495 L 4.958 8.503 L 5.123 9.018 L 5.289 8.503 L 8.262 0.495 C 8.388 0.155 8.615 0 8.974 0 L 9.517 0 C 9.865 0 10.07 0.092 10.172 0.297 C 10.279 0.511 10.275 0.72 10.157 1.021 L 6.502 10.703 C 6.371 11.039 6.149 11.194 5.79 11.194 Z" fill="rgb(29, 28, 27)" height="11.1941px" id="uUQr5Yl4B" transform="translate(93.807 12.595)" width="10.248961642504256px"/><path d="M 5.407 11.738 C 2.167 11.738 0 9.424 0 5.797 C 0 2.169 2.133 0 5.221 0 C 8.31 0 10.292 2.255 10.292 5.456 L 10.292 5.694 C 10.292 6.098 10.075 6.316 9.672 6.316 L 1.995 6.316 C 2.165 8.547 3.446 9.898 5.404 9.898 C 6.768 9.898 7.596 9.363 7.931 8.431 C 8.058 8.078 8.241 7.892 8.615 7.892 L 9.328 7.892 C 9.744 7.892 9.992 8.125 9.918 8.538 C 9.593 10.433 7.829 11.74 5.404 11.74 Z M 8.282 4.64 C 8.053 2.842 6.949 1.74 5.221 1.74 C 3.494 1.74 2.405 2.818 2.074 4.64 Z" fill="rgb(29, 28, 27)" height="11.739799999999999px" id="zo1nSBuSF" transform="translate(78.397 12.325)" width="10.29249999999999px"/><path d="M 3.057 10.677 C 3.163 11.026 3.392 11.192 3.756 11.192 L 3.749 11.194 L 4.987 11.194 C 5.35 11.194 5.579 11.028 5.69 10.679 L 8.173 2.654 L 8.237 2.401 L 8.3 2.654 L 10.787 10.679 C 10.894 11.028 11.123 11.194 11.487 11.194 L 12.733 11.194 C 13.096 11.194 13.325 11.028 13.432 10.679 L 16.418 1.006 C 16.516 0.7 16.512 0.498 16.41 0.288 C 16.307 0.089 16.109 0.002 15.76 0.002 L 15.218 0.002 C 14.848 0.002 14.626 0.168 14.519 0.522 L 12.094 8.547 L 12.046 8.761 L 11.999 8.542 L 9.506 0.517 C 9.4 0.168 9.171 0.002 8.807 0.002 L 7.683 0.002 C 7.319 0.002 7.091 0.168 6.984 0.517 L 4.492 8.542 L 4.449 8.745 L 4.405 8.551 L 1.98 0.519 C 1.874 0.166 1.649 0 1.281 0 L 0.728 0 C 0.38 0 0.181 0.087 0.079 0.286 C -0.021 0.493 -0.028 0.698 0.07 1.004 Z" fill="rgb(29, 28, 27)" height="11.194099999999999px" id="uboloLX99" transform="translate(61.282 12.598)" width="16.489163442184434px"/></svg>)
Tutorials
Building a Video Highlight Generator with Twelve Labs

Hrishikesh Yadav
The YouTube Chapter Highlight Generator is a tool developed to automatically generate chapter timestamps for YouTube videos. By analyzing the video's content, it identifies key segments and creates timestamps that can be used to create chapters for better video navigation and user experience.
The YouTube Chapter Highlight Generator is a tool developed to automatically generate chapter timestamps for YouTube videos. By analyzing the video's content, it identifies key segments and creates timestamps that can be used to create chapters for better video navigation and user experience.

In this article
No headings found on page
Join our newsletter
Join our newsletter
Receive the latest advancements, tutorials, and industry insights in video understanding
Receive the latest advancements, tutorials, and industry insights in video understanding
Search, analyze, and explore your videos with AI.
Oct 25, 2024
13 Min
Copy link to article
Introduction
🎬 Tired of manually creating chapter timestamps for your YouTube videos? Imagine automatically generating engaging video highlights and saving hours of tedious work.
In this tutorial, we'll explore the YouTube Chapter Highlight Generator with Twelve Labs, a powerful tool that revolutionizes how content creators approach video highlights. This application tackles one of the most time-consuming aspects of video production: creating accurate and meaningful chapter timestamps with highlights.
Whether you're an established YouTuber or just starting your content creation journey, this tool will streamline your workflow. It automatically analyzes video content, generates precise timestamps with highlights, and even creates segmented video clips. The best part? Creators can use it for both short-form content and longer podcast-style videos. Let's dive into how this application works and how you can build it using the TwelveLabs Python SDK to suit your specific needs.
You can explore the demo of the application here: Video Highlight Chapter Generation
If you want to access the code and experiment with the app directly, you can use this Replit Template.
Prerequisites
Generate an API key by signing up at the Twelve Labs Playground.
Find the repository for the notebooks and this application on Video Highlight Chapter Generator Github
There are several things you should already be familiar with - Python, HTML, Markdown.
Working of the Application
This section outlines the application flow for developing chapter highlights for YouTube videos, which saves time and simplifies the process of adding highlights to YouTube content.
For podcast videos, the system manages and combines timestamps from different video chunks. Users can also retrieve existing videos from the Index by selecting a previously indexed video, fetching its URL, and generating highlight timestamps using the video ID.
Here's a stepwise breakdown of the process:
User Interface
The application features two main tabs for user interaction.
The first tab allows users to upload new videos for highlight generation.
The second tab enables users to fetch and view previously indexed videos.
Video Upload Options
Users can upload two types of video content.
Basic videos are those less than 30 minutes in duration, while podcast-style videos can be up to an hour long.
Processing Workflow
The system processes basic videos directly.
Podcast-style videos are first split into manageable chunks for efficient handling.
Highlight Generation
Once indexing is complete, the system generates a unique video ID.
This video ID is then used as a parameter with the generate.summarize function.
The Pegasus 1.1 Generative Engine creates highlight-based timestamps for the video.
Output
The final result is a set of timestamps marking key moments in the video.
These timestamps serve as chapter markers or highlights for easy navigation.
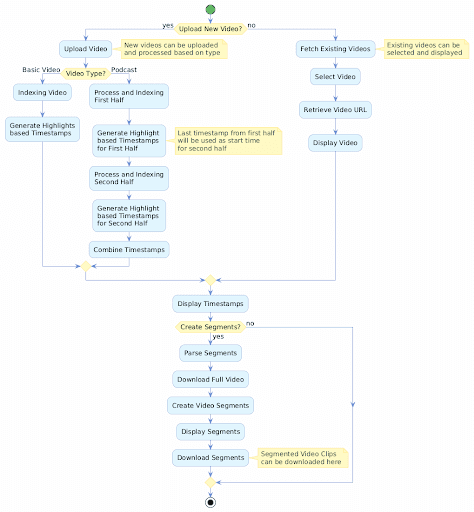
Video clip segmentation is accomplished using moviepy.editor, which accesses the video URL and highlights timestamps. To facilitate content creation, the video segments are generated in MP4 format.
Here's an overview of the application's components and their interactions:
User Interface - Manages user interactions and displays processed video segments.
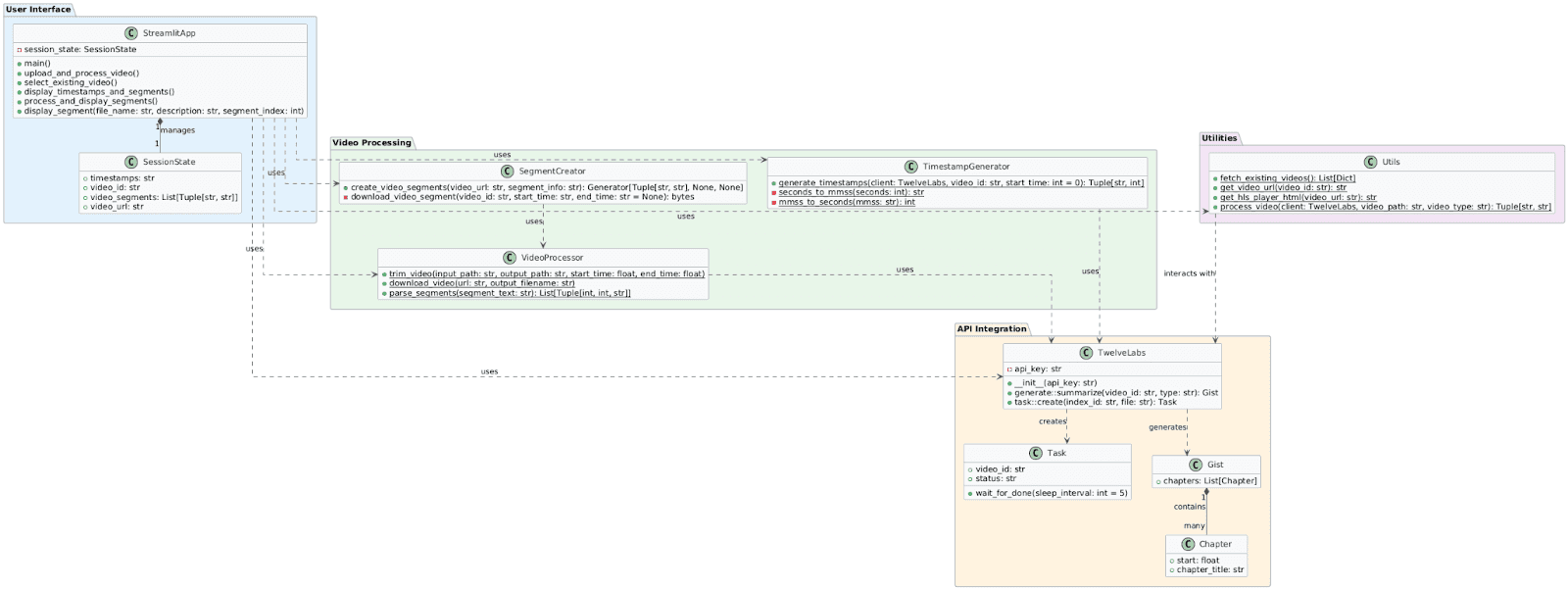
Video Processing - Provides core functionality for video segmentation and processing using moviepy, including:
Segment Creator - Generates video segments.
Video Processor - Trims videos and parses segments.
Utilities - Offers helper functions for tasks such as fetching videos and generating timestamps.
API Integration - Interfaces with Twelve Labs services for indexing, including:
Task creation and management.
Generation of Gist objects containing highlight chapter information.
Now that we have a comprehensive understanding of the application's workflow for YouTube video creators, our next step is to prepare for the building process.
Preparation Steps
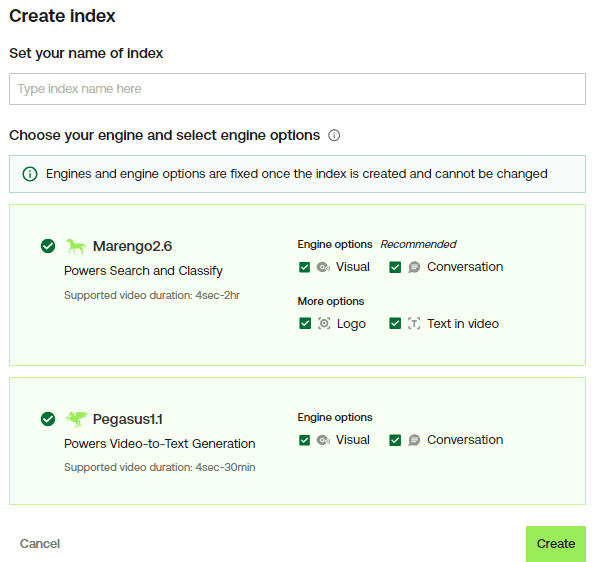
Sign up and create an Index on the Twelve Labs Playground.
Obtain your API Key from the Twelve Labs Playground.
Enable the following video understanding engines for generation:some text
Marengo 2.6 (Embedding Engine) for video search and classification
Pegasus 1.1 (Generative Engine) for video-to-text generation
These engines provide a robust foundation for video understanding.
Retrieve your
INDEX_IDby opening the Index created in step 1. The ID is in the URL: https://playground.twelvelabs.io/indexes/{index_id}.Set up the
.envfile with your API Key andINDEX_ID, along with the main file.
Twelvelabs_API=your_api_key_here API_URL=your_api_url_here
If you prefer the code-based approach, follow these steps:
Obtain your API Key from the Twelve Labs Playground and prepare the environment variable.
Import the Twelve Labs SDK and the environmental variables. Initiate the SDK client using the Twelve Labs API Key from the environment variable.
from twelvelabs import TwelveLabs from dotenv import load_dotenv load_dotenv() API_KEY = os.getenv("API_KEY") client = TwelveLabs(api_key=API_KEY)
Specifying the desired engine for the generation task:
engines = [ { "name": "marengo2.6", "options": ["visual", "conversation", "text_in_video", "logo"] }, { "name": "pegasus1.1", "options": ["visual", "conversation"] } ]
Create a new index by calling
client.indexwith the Index name and engine configuration parameters. Use a unique and identifiable name for the Index.
index = client.index.create( name="<YOUR_INDEX_NAME>", engines=engines ) print(f"A new index has been created: Index id={index.id} name={index.name} engines={index.engines}")
The index.id field represents the unique identifier of your new index. This identifier is crucial for indexing videos in their correct location.
With these steps completed, you're now ready to dive in and develop the application!
Walkthrough for Video Highlight Generator
In this tutorial, we will build a Streamit application with a minimal frontend. Below is the directory structure:
. ├── app.py ├── requirements.txt ├── utils.py ├── .env └── .gitignore
1 - Creating the Streamlit Application
Now that you've completed all the above steps, it's time to build the Streamlit application. This app provides a simple way for you to upload a video, generate highlight chapters, and create segmented video clips. The application consists of two main files:
main.py: Contains the application flow with a minimal page layout
utils.py: Houses all the essential utility functions for the application
You can find the required dependencies to set up a virtual environment in the requirements.txt file.
To get started, create a virtual Python environment and configure it for the application:
pip install -r requirements.txt
2 - Setting up the utility function for the operation
In this section, we'll explore how to generate highlight chapters and handle longer videos for indexing. We'll also cover creating video segments from the highlighted chapters by applying the results to the video indexed in section 2.2.
2.1 - Generating the Highlight Chapter and Handling the Video Processing
First, we'll import the necessary libraries: moviepy.editor, m3u8, io, urllib.parse, yt_dlp, and the Twelve Lab SDK. We'll also set up the API Key and Index ID environment variables. We'll discuss the importance of these libraries and their functions in detail.
import os import requests from moviepy.editor import VideoFileClip from twelvelabs import TwelveLabs from dotenv import load_dotenv import io import m3u8 from urllib.parse import urljoin import yt_dlp # Load environment variables load_dotenv() API_KEY = os.getenv("API_KEY") INDEX_ID = os.getenv("INDEX_ID") def seconds_to_mmss(seconds): minutes, seconds = divmod(int(seconds), 60) return f"{minutes:02d}:{seconds:02d}" def mmss_to_seconds(mmss): minutes, seconds = map(int, mmss.split(':')) return minutes * 60 + seconds def generate_timestamps(client, video_id, start_time=0): try: gist = client.generate.summarize(video_id=video_id, type="chapter") chapter_text = "\n".join([f"{seconds_to_mmss(chapter.start + start_time)}-{chapter.chapter_title}" for chapter in gist.chapters]) return chapter_text, gist.chapters[-1].start + start_time except Exception as e: raise Exception(f"An error occurred while generating timestamps: {str(e)}") # Utitily function to trim the video based on the time stamps def trim_video(input_path, output_path, start_time, end_time): with VideoFileClip(input_path) as video: new_video = video.subclip(start_time, end_time) new_video.write_videofile(output_path, codec="libx264", audio_codec="aac") # Based on the speicific Index_ID, fetching all the video_id def fetch_existing_videos(): url = f"https://api.twelvelabs.io/v1.2/indexes/{INDEX_ID}/videos?page=1&page_limit=10&sort_by=created_at&sort_option=desc" headers = {"accept": "application/json", "x-api-key": API_KEY, "Content-Type": "application/json"} response = requests.get(url, headers=headers) if response.status_code == 200: return response.json()['data'] else: raise Exception(f"Failed to fetch videos: {response.text}") # Utility function to retrieve the URL of the video with video_id def get_video_url(video_id): url = f"https://api.twelvelabs.io/v1.2/indexes/{INDEX_ID}/videos/{video_id}" headers = {"accept": "application/json", "x-api-key": API_KEY} response = requests.get(url, headers=headers) if response.status_code == 200: data = response.json() return data['hls']['video_url'] if 'hls' in data and 'video_url' in data['hls'] else None else: raise Exception(f"Failed to get video URL: {response.text}") # Utility function to handle and process the video clips larger than 30 mins def process_video(client, video_path, video_type): with VideoFileClip(video_path) as clip: duration = clip.duration if duration > 3600: raise Exception("Video duration exceeds 1 hour. Please upload a shorter video.") if video_type == "Basic Video (less than 30 mins)": task = client.task.create(index_id=INDEX_ID, file=video_path) task.wait_for_done(sleep_interval=5) if task.status == "ready": timestamps, _ = generate_timestamps(client, task.video_id) return timestamps, task.video_id else: raise Exception(f"Indexing failed with status {task.status}") elif video_type == "Podcast (30 mins to 1 hour)": trimmed_path = os.path.join(os.path.dirname(video_path), "trimmed_1.mp4") trim_video(video_path, trimmed_path, 0, 1800) task1 = client.task.create(index_id=INDEX_ID, file=trimmed_path) task1.wait_for_done(sleep_interval=5) os.remove(trimmed_path) if task1.status != "ready": raise Exception(f"Indexing failed with status {task1.status}") timestamps, end_time = generate_timestamps(client, task1.video_id) if duration > 1800: trimmed_path = os.path.join(os.path.dirname(video_path), "trimmed_2.mp4") trim_video(video_path, trimmed_path, 1800, int(duration)) task2 = client.task.create(index_id=INDEX_ID, file=trimmed_path) task2.wait_for_done(sleep_interval=5) os.remove(trimmed_path) if task2.status != "ready": raise Exception(f"Indexing failed with status {task2.status}") timestamps_2, _ = generate_timestamps(client, task2.video_id, start_time=end_time) timestamps += "\n" + timestamps_2 return timestamps, task1.video_id # Utility function to render the video on the UI def get_hls_player_html(video_url): return f""" <script src="https://cdn.jsdelivr.net/npm/hls.js@latest"></script> <style> #video-container {{ position: relative; width: 100%; padding-bottom: 56.25%; overflow: hidden; border-radius: 10px; box-shadow: 0 4px 6px rgba(0, 0, 0, 0.1); }} #video {{ position: absolute; top: 0; left: 0; width: 100%; height: 100%; object-fit: contain; }} </style> <div id="video-container"> <video id="video" controls></video> </div> <script> var video = document.getElementById('video'); var videoSrc = "{video_url}"; if (Hls.isSupported()) {{ var hls = new Hls(); hls.loadSource(videoSrc); hls.attachMedia(video); hls.on(Hls.Events.MANIFEST_PARSED, function() {{ video.pause(); }}); }} else if (video.canPlayType('application/vnd.apple.mpegurl')) {{ video.src = videoSrc; video.addEventListener('loadedmetadata', function() {{ video.pause(); }}); }} </script> """
A. Input: Video Content Handling
This application heavily relies on the process_video function. It supports two types of video content: short videos under 30 minutes and longer podcast-style videos up to an hour. For longer videos, further processing is carried out by splitting the content into manageable chunks using the trim_video utility function, ensuring accurate analysis even for lengthy recordings.
B. Processing: Video Indexing, Analysis, and Chapter Generation
For short videos under 30 minutes, video indexing begins with Marengo 2.6 (Embedding Engine), which generates the video ID. It then interacts with the generate function in TwelveLabs SDK, Pegasus 1.1 (Generative Engine), to analyze the video content and generate timestamp-based chapters for the indexed video.
For longer videos, 30-minute chunks are created, indexed one by one, and then analyzed to generate timestamp-based chapters. The end timestamp of the first chunk becomes the start of the next chunk.
The get_video_url function retrieves the video URL of the indexed video to render it in the application. The get_hls_player_html(video_url) function is used to render the video.
C. Return Values: Highlights with Timestamps
The generation process produces timestamps in seconds. However, YouTube descriptions require highlights in minutes and seconds (mm:ss) format. Therefore, seconds_to_mmss is used for conversion, while mmss_to_seconds facilitates the conversion of minutes to seconds, which is then used to trim video clips based on chapters.
All user-uploaded videos are indexed by the Index ID created earlier. Users can access indexed videos using fetch_existing_videos(). This provides the video ID, which is sent directly to the generative engine by calling generate_timestamp.
2.2 - Retrieve Video from Index and Segment Based on Results
This section focuses on trimming video segments based on highlight timestamps. Utility functions work together to download, parse, and create segments based on timestamps.
# Utility function to download the indexed video with the url from video_id def download_video(url, output_filename): ydl_opts = { 'format': 'best', 'outtmpl': output_filename, } with yt_dlp.YoutubeDL(ydl_opts) as ydl: ydl.download([url]) # Utitily Function to Parse the Segment def parse_segments(segment_text): lines = segment_text.strip().split('\n') segments = [] for i, line in enumerate(lines): start, description = line.split('-', 1) start_time = mmss_to_seconds(start.strip()) if i < len(lines) - 1: end = lines[i+1].split('-')[0] end_time = mmss_to_seconds(end.strip()) else: end_time = None segments.append((start_time, end_time, description.strip())) return segments # Utiltiy function to create the video segment def create_video_segments(video_url, segment_info): full_video = "full_video.mp4" segments = parse_segments(segment_info) try: # Download the full video clip download_video(video_url, full_video) for i, (start_time, end_time, description) in enumerate(segments): output_file = f"{i+1:02d}_{description.replace(' ', '_').lower()}.mp4" trim_video(full_video, output_file, start_time, end_time) yield output_file, description os.remove(full_video) except yt_dlp.utils.DownloadError as e: raise Exception(f"An error occurred while downloading: {str(e)}") except Exception as e: raise Exception(f"An unexpected error occurred: {str(e)}") # Function to downlaod the video segments after the trimming is done def download_video_segment(video_id, start_time, end_time=None): video_url = get_video_url(video_id) if not video_url: raise Exception("Failed to get video URL") playlist = m3u8.load(video_url) start_seconds = mmss_to_seconds(start_time) end_seconds = mmss_to_seconds(end_time) if end_time else None total_duration = 0 segments_to_download = [] for segment in playlist.segments: if total_duration >= start_seconds and (end_seconds is None or total_duration < end_seconds): segments_to_download.append(segment) total_duration += segment.duration if end_seconds is not None and total_duration >= end_seconds: break buffer = io.BytesIO() for segment in segments_to_download: segment_url = urljoin(video_url, segment.uri) response = requests.get(segment_url) if response.status_code == 200: buffer.write(response.content) else: raise Exception(f"Failed to download segment: {segment_url}") buffer.seek(0) return buffer.getvalue()
The download_video function uses the yt-dlp library to download entire videos. To create multiple segments from a single video, the full video file is downloaded.
The parse_segments function converts the generated timestamp information into a programmatically usable format. It breaks down chapter information into start times, end times, and descriptions, preparing for video segmentation.
create_video_segments ties everything together. After downloading the entire video, it parses segment information to create individual video clips for each chapter. This function returns each segment along with its description.
Video segments can be downloaded using the download_video_segment function. For creating chapter previews or extracting specific parts of longer videos, it uses the HLS (HTTP Live Streaming) protocol to download only the required video segments.
This process offers content creators the ability to not only generate timestamps but also create tangible video segments for use in their production workflows and editing process 🎬✂️️.
3 - Instruction Flow of the Streamlit Application
This section focuses on the main application function, designed for a minimal UI and streamlined instructions flow by utilizing key utility functions.
The application begins by configuring the Streamlit page and applying custom CSS for an attractive, themed interface. It then initializes session state variables to maintain data consistency across reruns. For the complete code, see app.py. Essential utility functions are discussed below.
# Uplaoding feature and the processing of the video def upload_and_process_video(): video_type = st.selectbox("Select video type:", ["Basic Video (less than 30 mins)", "Podcast (30 mins to 1 hour)"]) uploaded_file = st.file_uploader("Choose a video file", type=["mp4", "mov", "avi"]) if uploaded_file and st.button("Process Video", key="process_video_button"): with tempfile.NamedTemporaryFile(delete=False, suffix=".mp4") as tmp_file: tmp_file.write(uploaded_file.read()) video_path = tmp_file.name try: with st.spinner("Processing video..."): client = TwelveLabs(api_key=API_KEY) timestamps, video_id = process_video(client, video_path, video_type) st.success("Video processed successfully!") st.session_state.timestamps = timestamps st.session_state.video_id = video_id st.session_state.video_url = get_video_url(video_id) if st.session_state.video_url: st.video(st.session_state.video_url) else: st.error("Failed to retrieve video URL.") except Exception as e: st.error(str(e)) finally: os.unlink(video_path) # Selecting the existing video from the Index and generating timestamps highlight def select_existing_video(): try: existing_videos = fetch_existing_videos() video_options = {f"{video['metadata']['filename']} ({video['_id']})": video['_id'] for video in existing_videos} if video_options: selected_video = st.selectbox("Select a video:", list(video_options.keys())) video_id = video_options[selected_video] st.session_state.video_id = video_id st.session_state.video_url = get_video_url(video_id) if st.session_state.video_url: st.markdown(f"### Selected Video: {selected_video}") st.video(st.session_state.video_url) else: st.error("Failed to retrieve video URL.") if st.button("Generate Timestamps", key="generate_timestamps_button"): with st.spinner("Generating timestamps..."): client = TwelveLabs(api_key=API_KEY) timestamps, _ = generate_timestamps(client, video_id) st.session_state.timestamps = timestamps else: st.warning("No existing videos found in the index.") except Exception as e: st.error(str(e))
The main interface features two tabs: one for uploading new videos and another for selecting existing ones. The app handles errors gracefully and provides user feedback throughout. During lengthy video segmentation processes, progress bars and status messages keep users informed. A feature to clear all segments helps manage storage and allows users to start fresh.
upload_and_process_video(): Handles video file uploads and processing. It manages both regular videos (under 30 minutes) and longer videos, converting longer ones into chunks before indexing. Finally, it employs the generative engine.select_existing_video(): Allows users to choose from previously uploaded videos stored in the TwelveLabs index.
The application uses st.session_state to store and retrieve crucial information such as video URLs, IDs, and generated timestamps. This approach enables data persistence across app re-runs, ensuring a seamless user experience for multi-step operations. By maintaining this state, the app can display processed videos, use them for further operations, and work with generated timestamps without requiring users to re-upload or reprocess data.
# Function to Display the Segment and also Download def display_segment(file_name, description, segment_index): if os.path.exists(file_name): st.write(f"### {description}") st.video(file_name) with open(file_name, "rb") as file: file_contents = file.read() unique_key = f"download_{segment_index}_{uuid.uuid4()}" st.download_button( label=f"Download: {description}", data=file_contents, file_name=file_name, mime="video/mp4", key=unique_key ) st.markdown("---") else: st.warning(f"File {file_name} not found. It may have been deleted or moved.") # Function to process the segment def process_and_display_segments(): if not st.session_state.video_url: st.error("Video URL not found. Please reprocess the video.") return segment_generator = create_video_segments(st.session_state.video_url, st.session_state.timestamps) progress_bar = st.progress(0) status_text = st.empty() st.session_state.video_segments = [] # Reset video segments total_segments = len(st.session_state.timestamps.split('\n')) for i, (file_name, description) in enumerate(segment_generator, 1): st.session_state.video_segments.append((file_name, description)) display_segment(file_name, description, i-1) # Pass the index here progress = i / total_segments progress_bar.progress(progress) status_text.text(f"Processing segment {i}/{total_segments}...") progress_bar.progress(1.0) status_text.text("All segments processed!") # Function to display the timestamps and the segments def display_timestamps_and_segments(): if st.session_state.timestamps: st.subheader("YouTube Chapter Timestamps") st.write("Copy the Timestamp description and add it to the Youtube Video Description") st.code(st.session_state.timestamps, language="") if st.button("Create Video Segments", key="create_segments_button"): try: process_and_display_segments() except Exception as e: st.error(f"Error creating video segments: {str(e)}") st.exception(e) # This will display the full traceback if st.session_state.video_segments: st.subheader("Video Segments") for index, (file_name, description) in enumerate(st.session_state.video_segments): display_segment(file_name, description, index) if st.button("Clear all segments", key="clear_segments_button"): for file_name, _ in st.session_state.video_segments: if os.path.exists(file_name): os.remove(file_name) st.session_state.video_segments = [] st.success("All segment files have been cleared.") st.experimental_rerun()
process_and_display_segments(): Manages the creation and display of video segments based on generated timestamps.display_timestamps_and_segments(): Presents generated timestamps in a copyable format and provides options to create and display video segments.display_segment(): Renders individual video segments, complete with a download button for each.
The display_segment function takes a file name, description, and segment index as inputs. It checks for the video file's existence, displays the segment's description, plays the video using Streamlit's st.video function, and provides a uniquely keyed download button. If the file is not found, it shows a warning message.
The process_and_display_segments function creates and displays all video segments. It first checks for a video URL in the session state, showing an error message if absent. Otherwise, it uses create_video_segments to generate segments based on provided timestamps, displaying a progress bar and status text during processing. Each segment is added to the session state and displayed using the display_segment function.
The display_timestamps_and_segments function integrates all components. It displays YouTube chapter timestamps if available and provides a button to create video segments. When clicked, this button triggers the process_and_display_segments function. For existing segments, it displays them and offers an option to clear all segments, removing files and resetting the application state.
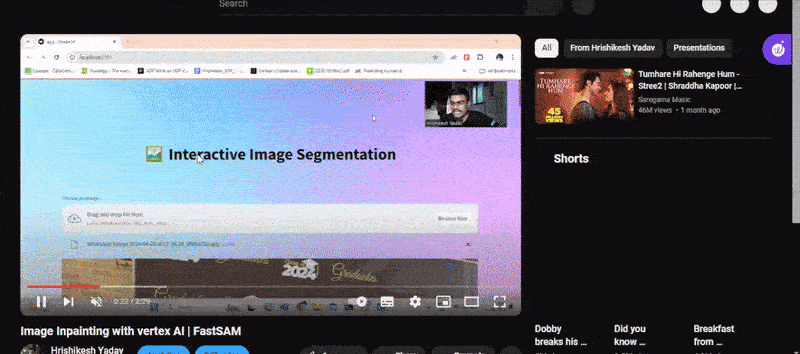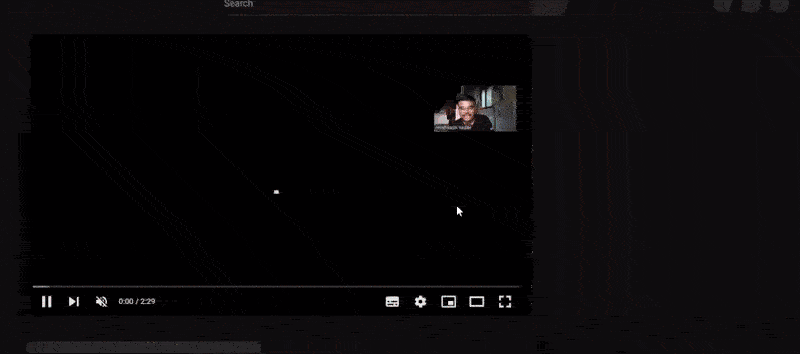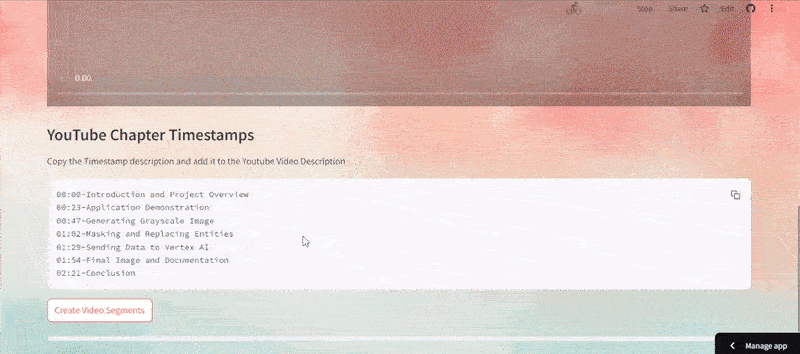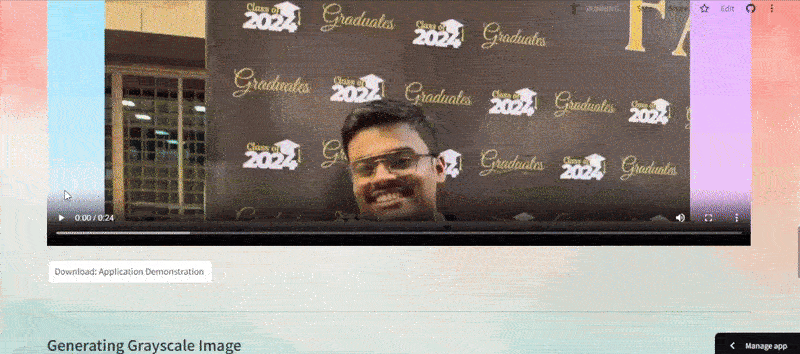
Below is the Demo Application Example:
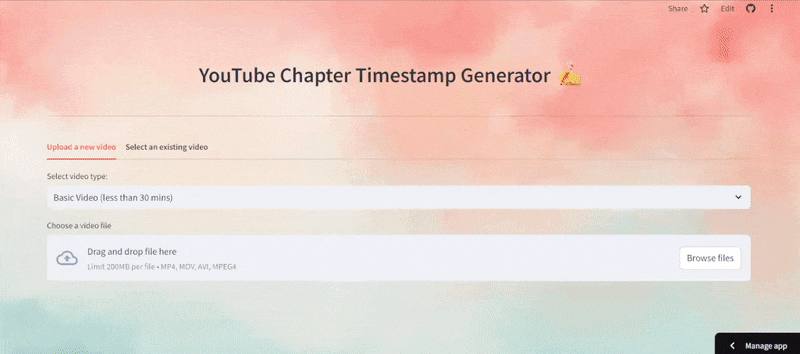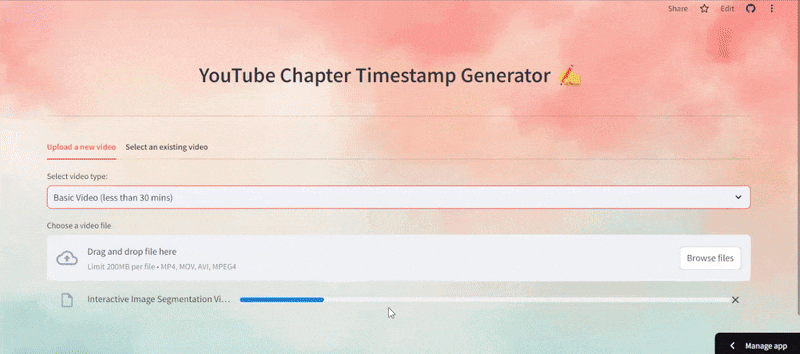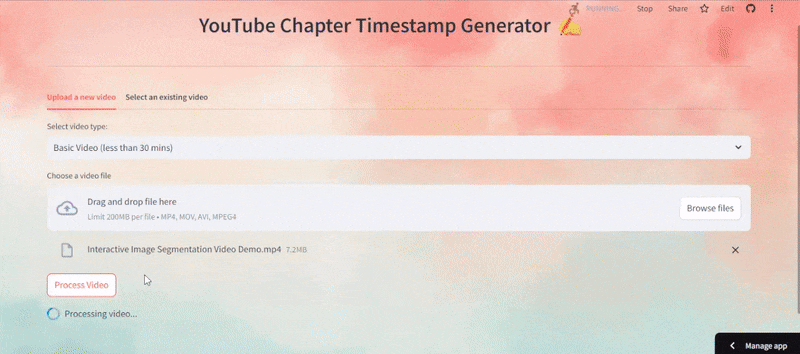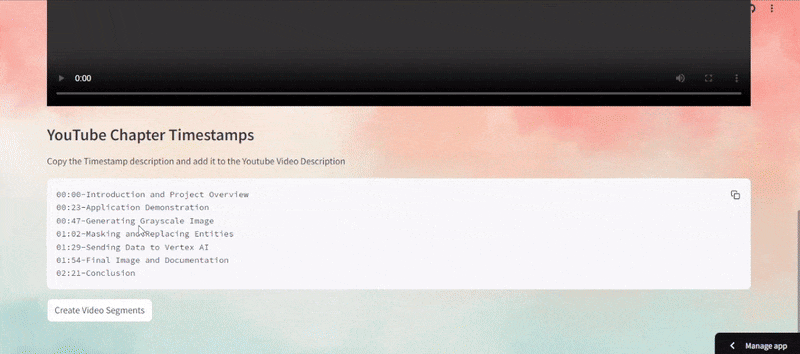
As can be seen in the above demo, the video is uploaded and indexed to generate the highlight with timestamp, which can be easily configured to fit into a YouTube description. You can observe how the highlight is implemented in the next step of the demo, as well as how segments are generated from the highlight.
To explore Twelve Labs in diverse contexts, try applying the chapter use cases to various sectors such as editing, education, or any other area that piques your interest.
More Ideas to Experiment with the Tutorial
Understanding how an application works and its development process empowers you to implement innovative ideas and create products that meet users' needs. Here are some potential use cases for video content creators, similar to the one discussed in the tutorial:
📽️ YouTube Content Creators: Generate chapter highlight markers to enhance video navigation.
🎓 Educational Videos: Enable students to easily select specific sections of interest in long tutorial videos.
🎥 Content Segmentation: Effortlessly create video clips ready for upload.
Conclusion
This blog post provides a detailed explanation of the video highlight chapter generation process developed with Twelve Labs to cater to content creators' needs. Thank you for following along with the tutorial. We look forward to your ideas on improving the user experience and solving various challenges.
Additional Resources
Learn more about the engines used for the generation task, Marengo 2.6 (Embedding Engine) and Pegasus 1.1 (Generator Engine). To further explore Twelve Labs and enhance your understanding of video content analysis, check out these valuable resources:
Discord Community: Join our vibrant community of developers and enthusiasts to discuss ideas, ask questions, and share your projects. Join the Twelve Labs Discord
Sample Applications: Explore a variety of sample applications to inspire your next project or learn new implementation techniques.
Explore Tutorials: Dive deeper into Twelve Labs capabilities with our comprehensive tutorials.
We encourage you to leverage these resources to expand your knowledge and create innovative applications using Twelve Labs video understanding technology.
Introduction
🎬 Tired of manually creating chapter timestamps for your YouTube videos? Imagine automatically generating engaging video highlights and saving hours of tedious work.
In this tutorial, we'll explore the YouTube Chapter Highlight Generator with Twelve Labs, a powerful tool that revolutionizes how content creators approach video highlights. This application tackles one of the most time-consuming aspects of video production: creating accurate and meaningful chapter timestamps with highlights.
Whether you're an established YouTuber or just starting your content creation journey, this tool will streamline your workflow. It automatically analyzes video content, generates precise timestamps with highlights, and even creates segmented video clips. The best part? Creators can use it for both short-form content and longer podcast-style videos. Let's dive into how this application works and how you can build it using the TwelveLabs Python SDK to suit your specific needs.
You can explore the demo of the application here: Video Highlight Chapter Generation
If you want to access the code and experiment with the app directly, you can use this Replit Template.
Prerequisites
Generate an API key by signing up at the Twelve Labs Playground.
Find the repository for the notebooks and this application on Video Highlight Chapter Generator Github
There are several things you should already be familiar with - Python, HTML, Markdown.
Working of the Application
This section outlines the application flow for developing chapter highlights for YouTube videos, which saves time and simplifies the process of adding highlights to YouTube content.
For podcast videos, the system manages and combines timestamps from different video chunks. Users can also retrieve existing videos from the Index by selecting a previously indexed video, fetching its URL, and generating highlight timestamps using the video ID.
Here's a stepwise breakdown of the process:
User Interface
The application features two main tabs for user interaction.
The first tab allows users to upload new videos for highlight generation.
The second tab enables users to fetch and view previously indexed videos.
Video Upload Options
Users can upload two types of video content.
Basic videos are those less than 30 minutes in duration, while podcast-style videos can be up to an hour long.
Processing Workflow
The system processes basic videos directly.
Podcast-style videos are first split into manageable chunks for efficient handling.
Highlight Generation
Once indexing is complete, the system generates a unique video ID.
This video ID is then used as a parameter with the generate.summarize function.
The Pegasus 1.1 Generative Engine creates highlight-based timestamps for the video.
Output
The final result is a set of timestamps marking key moments in the video.
These timestamps serve as chapter markers or highlights for easy navigation.
Video clip segmentation is accomplished using moviepy.editor, which accesses the video URL and highlights timestamps. To facilitate content creation, the video segments are generated in MP4 format.
Here's an overview of the application's components and their interactions:
User Interface - Manages user interactions and displays processed video segments.
Video Processing - Provides core functionality for video segmentation and processing using moviepy, including:
Segment Creator - Generates video segments.
Video Processor - Trims videos and parses segments.
Utilities - Offers helper functions for tasks such as fetching videos and generating timestamps.
API Integration - Interfaces with Twelve Labs services for indexing, including:
Task creation and management.
Generation of Gist objects containing highlight chapter information.
Now that we have a comprehensive understanding of the application's workflow for YouTube video creators, our next step is to prepare for the building process.
Preparation Steps
Sign up and create an Index on the Twelve Labs Playground.
Obtain your API Key from the Twelve Labs Playground.
Enable the following video understanding engines for generation:some text
Marengo 2.6 (Embedding Engine) for video search and classification
Pegasus 1.1 (Generative Engine) for video-to-text generation
These engines provide a robust foundation for video understanding.
Retrieve your
INDEX_IDby opening the Index created in step 1. The ID is in the URL: https://playground.twelvelabs.io/indexes/{index_id}.Set up the
.envfile with your API Key andINDEX_ID, along with the main file.
Twelvelabs_API=your_api_key_here API_URL=your_api_url_here
If you prefer the code-based approach, follow these steps:
Obtain your API Key from the Twelve Labs Playground and prepare the environment variable.
Import the Twelve Labs SDK and the environmental variables. Initiate the SDK client using the Twelve Labs API Key from the environment variable.
from twelvelabs import TwelveLabs from dotenv import load_dotenv load_dotenv() API_KEY = os.getenv("API_KEY") client = TwelveLabs(api_key=API_KEY)
Specifying the desired engine for the generation task:
engines = [ { "name": "marengo2.6", "options": ["visual", "conversation", "text_in_video", "logo"] }, { "name": "pegasus1.1", "options": ["visual", "conversation"] } ]
Create a new index by calling
client.indexwith the Index name and engine configuration parameters. Use a unique and identifiable name for the Index.
index = client.index.create( name="<YOUR_INDEX_NAME>", engines=engines ) print(f"A new index has been created: Index id={index.id} name={index.name} engines={index.engines}")
The index.id field represents the unique identifier of your new index. This identifier is crucial for indexing videos in their correct location.
With these steps completed, you're now ready to dive in and develop the application!
Walkthrough for Video Highlight Generator
In this tutorial, we will build a Streamit application with a minimal frontend. Below is the directory structure:
. ├── app.py ├── requirements.txt ├── utils.py ├── .env └── .gitignore
1 - Creating the Streamlit Application
Now that you've completed all the above steps, it's time to build the Streamlit application. This app provides a simple way for you to upload a video, generate highlight chapters, and create segmented video clips. The application consists of two main files:
main.py: Contains the application flow with a minimal page layout
utils.py: Houses all the essential utility functions for the application
You can find the required dependencies to set up a virtual environment in the requirements.txt file.
To get started, create a virtual Python environment and configure it for the application:
pip install -r requirements.txt
2 - Setting up the utility function for the operation
In this section, we'll explore how to generate highlight chapters and handle longer videos for indexing. We'll also cover creating video segments from the highlighted chapters by applying the results to the video indexed in section 2.2.
2.1 - Generating the Highlight Chapter and Handling the Video Processing
First, we'll import the necessary libraries: moviepy.editor, m3u8, io, urllib.parse, yt_dlp, and the Twelve Lab SDK. We'll also set up the API Key and Index ID environment variables. We'll discuss the importance of these libraries and their functions in detail.
import os import requests from moviepy.editor import VideoFileClip from twelvelabs import TwelveLabs from dotenv import load_dotenv import io import m3u8 from urllib.parse import urljoin import yt_dlp # Load environment variables load_dotenv() API_KEY = os.getenv("API_KEY") INDEX_ID = os.getenv("INDEX_ID") def seconds_to_mmss(seconds): minutes, seconds = divmod(int(seconds), 60) return f"{minutes:02d}:{seconds:02d}" def mmss_to_seconds(mmss): minutes, seconds = map(int, mmss.split(':')) return minutes * 60 + seconds def generate_timestamps(client, video_id, start_time=0): try: gist = client.generate.summarize(video_id=video_id, type="chapter") chapter_text = "\n".join([f"{seconds_to_mmss(chapter.start + start_time)}-{chapter.chapter_title}" for chapter in gist.chapters]) return chapter_text, gist.chapters[-1].start + start_time except Exception as e: raise Exception(f"An error occurred while generating timestamps: {str(e)}") # Utitily function to trim the video based on the time stamps def trim_video(input_path, output_path, start_time, end_time): with VideoFileClip(input_path) as video: new_video = video.subclip(start_time, end_time) new_video.write_videofile(output_path, codec="libx264", audio_codec="aac") # Based on the speicific Index_ID, fetching all the video_id def fetch_existing_videos(): url = f"https://api.twelvelabs.io/v1.2/indexes/{INDEX_ID}/videos?page=1&page_limit=10&sort_by=created_at&sort_option=desc" headers = {"accept": "application/json", "x-api-key": API_KEY, "Content-Type": "application/json"} response = requests.get(url, headers=headers) if response.status_code == 200: return response.json()['data'] else: raise Exception(f"Failed to fetch videos: {response.text}") # Utility function to retrieve the URL of the video with video_id def get_video_url(video_id): url = f"https://api.twelvelabs.io/v1.2/indexes/{INDEX_ID}/videos/{video_id}" headers = {"accept": "application/json", "x-api-key": API_KEY} response = requests.get(url, headers=headers) if response.status_code == 200: data = response.json() return data['hls']['video_url'] if 'hls' in data and 'video_url' in data['hls'] else None else: raise Exception(f"Failed to get video URL: {response.text}") # Utility function to handle and process the video clips larger than 30 mins def process_video(client, video_path, video_type): with VideoFileClip(video_path) as clip: duration = clip.duration if duration > 3600: raise Exception("Video duration exceeds 1 hour. Please upload a shorter video.") if video_type == "Basic Video (less than 30 mins)": task = client.task.create(index_id=INDEX_ID, file=video_path) task.wait_for_done(sleep_interval=5) if task.status == "ready": timestamps, _ = generate_timestamps(client, task.video_id) return timestamps, task.video_id else: raise Exception(f"Indexing failed with status {task.status}") elif video_type == "Podcast (30 mins to 1 hour)": trimmed_path = os.path.join(os.path.dirname(video_path), "trimmed_1.mp4") trim_video(video_path, trimmed_path, 0, 1800) task1 = client.task.create(index_id=INDEX_ID, file=trimmed_path) task1.wait_for_done(sleep_interval=5) os.remove(trimmed_path) if task1.status != "ready": raise Exception(f"Indexing failed with status {task1.status}") timestamps, end_time = generate_timestamps(client, task1.video_id) if duration > 1800: trimmed_path = os.path.join(os.path.dirname(video_path), "trimmed_2.mp4") trim_video(video_path, trimmed_path, 1800, int(duration)) task2 = client.task.create(index_id=INDEX_ID, file=trimmed_path) task2.wait_for_done(sleep_interval=5) os.remove(trimmed_path) if task2.status != "ready": raise Exception(f"Indexing failed with status {task2.status}") timestamps_2, _ = generate_timestamps(client, task2.video_id, start_time=end_time) timestamps += "\n" + timestamps_2 return timestamps, task1.video_id # Utility function to render the video on the UI def get_hls_player_html(video_url): return f""" <script src="https://cdn.jsdelivr.net/npm/hls.js@latest"></script> <style> #video-container {{ position: relative; width: 100%; padding-bottom: 56.25%; overflow: hidden; border-radius: 10px; box-shadow: 0 4px 6px rgba(0, 0, 0, 0.1); }} #video {{ position: absolute; top: 0; left: 0; width: 100%; height: 100%; object-fit: contain; }} </style> <div id="video-container"> <video id="video" controls></video> </div> <script> var video = document.getElementById('video'); var videoSrc = "{video_url}"; if (Hls.isSupported()) {{ var hls = new Hls(); hls.loadSource(videoSrc); hls.attachMedia(video); hls.on(Hls.Events.MANIFEST_PARSED, function() {{ video.pause(); }}); }} else if (video.canPlayType('application/vnd.apple.mpegurl')) {{ video.src = videoSrc; video.addEventListener('loadedmetadata', function() {{ video.pause(); }}); }} </script> """
A. Input: Video Content Handling
This application heavily relies on the process_video function. It supports two types of video content: short videos under 30 minutes and longer podcast-style videos up to an hour. For longer videos, further processing is carried out by splitting the content into manageable chunks using the trim_video utility function, ensuring accurate analysis even for lengthy recordings.
B. Processing: Video Indexing, Analysis, and Chapter Generation
For short videos under 30 minutes, video indexing begins with Marengo 2.6 (Embedding Engine), which generates the video ID. It then interacts with the generate function in TwelveLabs SDK, Pegasus 1.1 (Generative Engine), to analyze the video content and generate timestamp-based chapters for the indexed video.
For longer videos, 30-minute chunks are created, indexed one by one, and then analyzed to generate timestamp-based chapters. The end timestamp of the first chunk becomes the start of the next chunk.
The get_video_url function retrieves the video URL of the indexed video to render it in the application. The get_hls_player_html(video_url) function is used to render the video.
C. Return Values: Highlights with Timestamps
The generation process produces timestamps in seconds. However, YouTube descriptions require highlights in minutes and seconds (mm:ss) format. Therefore, seconds_to_mmss is used for conversion, while mmss_to_seconds facilitates the conversion of minutes to seconds, which is then used to trim video clips based on chapters.
All user-uploaded videos are indexed by the Index ID created earlier. Users can access indexed videos using fetch_existing_videos(). This provides the video ID, which is sent directly to the generative engine by calling generate_timestamp.
2.2 - Retrieve Video from Index and Segment Based on Results
This section focuses on trimming video segments based on highlight timestamps. Utility functions work together to download, parse, and create segments based on timestamps.
# Utility function to download the indexed video with the url from video_id def download_video(url, output_filename): ydl_opts = { 'format': 'best', 'outtmpl': output_filename, } with yt_dlp.YoutubeDL(ydl_opts) as ydl: ydl.download([url]) # Utitily Function to Parse the Segment def parse_segments(segment_text): lines = segment_text.strip().split('\n') segments = [] for i, line in enumerate(lines): start, description = line.split('-', 1) start_time = mmss_to_seconds(start.strip()) if i < len(lines) - 1: end = lines[i+1].split('-')[0] end_time = mmss_to_seconds(end.strip()) else: end_time = None segments.append((start_time, end_time, description.strip())) return segments # Utiltiy function to create the video segment def create_video_segments(video_url, segment_info): full_video = "full_video.mp4" segments = parse_segments(segment_info) try: # Download the full video clip download_video(video_url, full_video) for i, (start_time, end_time, description) in enumerate(segments): output_file = f"{i+1:02d}_{description.replace(' ', '_').lower()}.mp4" trim_video(full_video, output_file, start_time, end_time) yield output_file, description os.remove(full_video) except yt_dlp.utils.DownloadError as e: raise Exception(f"An error occurred while downloading: {str(e)}") except Exception as e: raise Exception(f"An unexpected error occurred: {str(e)}") # Function to downlaod the video segments after the trimming is done def download_video_segment(video_id, start_time, end_time=None): video_url = get_video_url(video_id) if not video_url: raise Exception("Failed to get video URL") playlist = m3u8.load(video_url) start_seconds = mmss_to_seconds(start_time) end_seconds = mmss_to_seconds(end_time) if end_time else None total_duration = 0 segments_to_download = [] for segment in playlist.segments: if total_duration >= start_seconds and (end_seconds is None or total_duration < end_seconds): segments_to_download.append(segment) total_duration += segment.duration if end_seconds is not None and total_duration >= end_seconds: break buffer = io.BytesIO() for segment in segments_to_download: segment_url = urljoin(video_url, segment.uri) response = requests.get(segment_url) if response.status_code == 200: buffer.write(response.content) else: raise Exception(f"Failed to download segment: {segment_url}") buffer.seek(0) return buffer.getvalue()
The download_video function uses the yt-dlp library to download entire videos. To create multiple segments from a single video, the full video file is downloaded.
The parse_segments function converts the generated timestamp information into a programmatically usable format. It breaks down chapter information into start times, end times, and descriptions, preparing for video segmentation.
create_video_segments ties everything together. After downloading the entire video, it parses segment information to create individual video clips for each chapter. This function returns each segment along with its description.
Video segments can be downloaded using the download_video_segment function. For creating chapter previews or extracting specific parts of longer videos, it uses the HLS (HTTP Live Streaming) protocol to download only the required video segments.
This process offers content creators the ability to not only generate timestamps but also create tangible video segments for use in their production workflows and editing process 🎬✂️️.
3 - Instruction Flow of the Streamlit Application
This section focuses on the main application function, designed for a minimal UI and streamlined instructions flow by utilizing key utility functions.
The application begins by configuring the Streamlit page and applying custom CSS for an attractive, themed interface. It then initializes session state variables to maintain data consistency across reruns. For the complete code, see app.py. Essential utility functions are discussed below.
# Uplaoding feature and the processing of the video def upload_and_process_video(): video_type = st.selectbox("Select video type:", ["Basic Video (less than 30 mins)", "Podcast (30 mins to 1 hour)"]) uploaded_file = st.file_uploader("Choose a video file", type=["mp4", "mov", "avi"]) if uploaded_file and st.button("Process Video", key="process_video_button"): with tempfile.NamedTemporaryFile(delete=False, suffix=".mp4") as tmp_file: tmp_file.write(uploaded_file.read()) video_path = tmp_file.name try: with st.spinner("Processing video..."): client = TwelveLabs(api_key=API_KEY) timestamps, video_id = process_video(client, video_path, video_type) st.success("Video processed successfully!") st.session_state.timestamps = timestamps st.session_state.video_id = video_id st.session_state.video_url = get_video_url(video_id) if st.session_state.video_url: st.video(st.session_state.video_url) else: st.error("Failed to retrieve video URL.") except Exception as e: st.error(str(e)) finally: os.unlink(video_path) # Selecting the existing video from the Index and generating timestamps highlight def select_existing_video(): try: existing_videos = fetch_existing_videos() video_options = {f"{video['metadata']['filename']} ({video['_id']})": video['_id'] for video in existing_videos} if video_options: selected_video = st.selectbox("Select a video:", list(video_options.keys())) video_id = video_options[selected_video] st.session_state.video_id = video_id st.session_state.video_url = get_video_url(video_id) if st.session_state.video_url: st.markdown(f"### Selected Video: {selected_video}") st.video(st.session_state.video_url) else: st.error("Failed to retrieve video URL.") if st.button("Generate Timestamps", key="generate_timestamps_button"): with st.spinner("Generating timestamps..."): client = TwelveLabs(api_key=API_KEY) timestamps, _ = generate_timestamps(client, video_id) st.session_state.timestamps = timestamps else: st.warning("No existing videos found in the index.") except Exception as e: st.error(str(e))
The main interface features two tabs: one for uploading new videos and another for selecting existing ones. The app handles errors gracefully and provides user feedback throughout. During lengthy video segmentation processes, progress bars and status messages keep users informed. A feature to clear all segments helps manage storage and allows users to start fresh.
upload_and_process_video(): Handles video file uploads and processing. It manages both regular videos (under 30 minutes) and longer videos, converting longer ones into chunks before indexing. Finally, it employs the generative engine.select_existing_video(): Allows users to choose from previously uploaded videos stored in the TwelveLabs index.
The application uses st.session_state to store and retrieve crucial information such as video URLs, IDs, and generated timestamps. This approach enables data persistence across app re-runs, ensuring a seamless user experience for multi-step operations. By maintaining this state, the app can display processed videos, use them for further operations, and work with generated timestamps without requiring users to re-upload or reprocess data.
# Function to Display the Segment and also Download def display_segment(file_name, description, segment_index): if os.path.exists(file_name): st.write(f"### {description}") st.video(file_name) with open(file_name, "rb") as file: file_contents = file.read() unique_key = f"download_{segment_index}_{uuid.uuid4()}" st.download_button( label=f"Download: {description}", data=file_contents, file_name=file_name, mime="video/mp4", key=unique_key ) st.markdown("---") else: st.warning(f"File {file_name} not found. It may have been deleted or moved.") # Function to process the segment def process_and_display_segments(): if not st.session_state.video_url: st.error("Video URL not found. Please reprocess the video.") return segment_generator = create_video_segments(st.session_state.video_url, st.session_state.timestamps) progress_bar = st.progress(0) status_text = st.empty() st.session_state.video_segments = [] # Reset video segments total_segments = len(st.session_state.timestamps.split('\n')) for i, (file_name, description) in enumerate(segment_generator, 1): st.session_state.video_segments.append((file_name, description)) display_segment(file_name, description, i-1) # Pass the index here progress = i / total_segments progress_bar.progress(progress) status_text.text(f"Processing segment {i}/{total_segments}...") progress_bar.progress(1.0) status_text.text("All segments processed!") # Function to display the timestamps and the segments def display_timestamps_and_segments(): if st.session_state.timestamps: st.subheader("YouTube Chapter Timestamps") st.write("Copy the Timestamp description and add it to the Youtube Video Description") st.code(st.session_state.timestamps, language="") if st.button("Create Video Segments", key="create_segments_button"): try: process_and_display_segments() except Exception as e: st.error(f"Error creating video segments: {str(e)}") st.exception(e) # This will display the full traceback if st.session_state.video_segments: st.subheader("Video Segments") for index, (file_name, description) in enumerate(st.session_state.video_segments): display_segment(file_name, description, index) if st.button("Clear all segments", key="clear_segments_button"): for file_name, _ in st.session_state.video_segments: if os.path.exists(file_name): os.remove(file_name) st.session_state.video_segments = [] st.success("All segment files have been cleared.") st.experimental_rerun()
process_and_display_segments(): Manages the creation and display of video segments based on generated timestamps.display_timestamps_and_segments(): Presents generated timestamps in a copyable format and provides options to create and display video segments.display_segment(): Renders individual video segments, complete with a download button for each.
The display_segment function takes a file name, description, and segment index as inputs. It checks for the video file's existence, displays the segment's description, plays the video using Streamlit's st.video function, and provides a uniquely keyed download button. If the file is not found, it shows a warning message.
The process_and_display_segments function creates and displays all video segments. It first checks for a video URL in the session state, showing an error message if absent. Otherwise, it uses create_video_segments to generate segments based on provided timestamps, displaying a progress bar and status text during processing. Each segment is added to the session state and displayed using the display_segment function.
The display_timestamps_and_segments function integrates all components. It displays YouTube chapter timestamps if available and provides a button to create video segments. When clicked, this button triggers the process_and_display_segments function. For existing segments, it displays them and offers an option to clear all segments, removing files and resetting the application state.
Below is the Demo Application Example:
As can be seen in the above demo, the video is uploaded and indexed to generate the highlight with timestamp, which can be easily configured to fit into a YouTube description. You can observe how the highlight is implemented in the next step of the demo, as well as how segments are generated from the highlight.
To explore Twelve Labs in diverse contexts, try applying the chapter use cases to various sectors such as editing, education, or any other area that piques your interest.
More Ideas to Experiment with the Tutorial
Understanding how an application works and its development process empowers you to implement innovative ideas and create products that meet users' needs. Here are some potential use cases for video content creators, similar to the one discussed in the tutorial:
📽️ YouTube Content Creators: Generate chapter highlight markers to enhance video navigation.
🎓 Educational Videos: Enable students to easily select specific sections of interest in long tutorial videos.
🎥 Content Segmentation: Effortlessly create video clips ready for upload.
Conclusion
This blog post provides a detailed explanation of the video highlight chapter generation process developed with Twelve Labs to cater to content creators' needs. Thank you for following along with the tutorial. We look forward to your ideas on improving the user experience and solving various challenges.
Additional Resources
Learn more about the engines used for the generation task, Marengo 2.6 (Embedding Engine) and Pegasus 1.1 (Generator Engine). To further explore Twelve Labs and enhance your understanding of video content analysis, check out these valuable resources:
Discord Community: Join our vibrant community of developers and enthusiasts to discuss ideas, ask questions, and share your projects. Join the Twelve Labs Discord
Sample Applications: Explore a variety of sample applications to inspire your next project or learn new implementation techniques.
Explore Tutorials: Dive deeper into Twelve Labs capabilities with our comprehensive tutorials.
We encourage you to leverage these resources to expand your knowledge and create innovative applications using Twelve Labs video understanding technology.
Introduction
🎬 Tired of manually creating chapter timestamps for your YouTube videos? Imagine automatically generating engaging video highlights and saving hours of tedious work.
In this tutorial, we'll explore the YouTube Chapter Highlight Generator with Twelve Labs, a powerful tool that revolutionizes how content creators approach video highlights. This application tackles one of the most time-consuming aspects of video production: creating accurate and meaningful chapter timestamps with highlights.
Whether you're an established YouTuber or just starting your content creation journey, this tool will streamline your workflow. It automatically analyzes video content, generates precise timestamps with highlights, and even creates segmented video clips. The best part? Creators can use it for both short-form content and longer podcast-style videos. Let's dive into how this application works and how you can build it using the TwelveLabs Python SDK to suit your specific needs.
You can explore the demo of the application here: Video Highlight Chapter Generation
If you want to access the code and experiment with the app directly, you can use this Replit Template.
Prerequisites
Generate an API key by signing up at the Twelve Labs Playground.
Find the repository for the notebooks and this application on Video Highlight Chapter Generator Github
There are several things you should already be familiar with - Python, HTML, Markdown.
Working of the Application
This section outlines the application flow for developing chapter highlights for YouTube videos, which saves time and simplifies the process of adding highlights to YouTube content.
For podcast videos, the system manages and combines timestamps from different video chunks. Users can also retrieve existing videos from the Index by selecting a previously indexed video, fetching its URL, and generating highlight timestamps using the video ID.
Here's a stepwise breakdown of the process:
User Interface
The application features two main tabs for user interaction.
The first tab allows users to upload new videos for highlight generation.
The second tab enables users to fetch and view previously indexed videos.
Video Upload Options
Users can upload two types of video content.
Basic videos are those less than 30 minutes in duration, while podcast-style videos can be up to an hour long.
Processing Workflow
The system processes basic videos directly.
Podcast-style videos are first split into manageable chunks for efficient handling.
Highlight Generation
Once indexing is complete, the system generates a unique video ID.
This video ID is then used as a parameter with the generate.summarize function.
The Pegasus 1.1 Generative Engine creates highlight-based timestamps for the video.
Output
The final result is a set of timestamps marking key moments in the video.
These timestamps serve as chapter markers or highlights for easy navigation.
Video clip segmentation is accomplished using moviepy.editor, which accesses the video URL and highlights timestamps. To facilitate content creation, the video segments are generated in MP4 format.
Here's an overview of the application's components and their interactions:
User Interface - Manages user interactions and displays processed video segments.
Video Processing - Provides core functionality for video segmentation and processing using moviepy, including:
Segment Creator - Generates video segments.
Video Processor - Trims videos and parses segments.
Utilities - Offers helper functions for tasks such as fetching videos and generating timestamps.
API Integration - Interfaces with Twelve Labs services for indexing, including:
Task creation and management.
Generation of Gist objects containing highlight chapter information.
Now that we have a comprehensive understanding of the application's workflow for YouTube video creators, our next step is to prepare for the building process.
Preparation Steps
Sign up and create an Index on the Twelve Labs Playground.
Obtain your API Key from the Twelve Labs Playground.
Enable the following video understanding engines for generation:some text
Marengo 2.6 (Embedding Engine) for video search and classification
Pegasus 1.1 (Generative Engine) for video-to-text generation
These engines provide a robust foundation for video understanding.
Retrieve your
INDEX_IDby opening the Index created in step 1. The ID is in the URL: https://playground.twelvelabs.io/indexes/{index_id}.Set up the
.envfile with your API Key andINDEX_ID, along with the main file.
Twelvelabs_API=your_api_key_here API_URL=your_api_url_here
If you prefer the code-based approach, follow these steps:
Obtain your API Key from the Twelve Labs Playground and prepare the environment variable.
Import the Twelve Labs SDK and the environmental variables. Initiate the SDK client using the Twelve Labs API Key from the environment variable.
from twelvelabs import TwelveLabs from dotenv import load_dotenv load_dotenv() API_KEY = os.getenv("API_KEY") client = TwelveLabs(api_key=API_KEY)
Specifying the desired engine for the generation task:
engines = [ { "name": "marengo2.6", "options": ["visual", "conversation", "text_in_video", "logo"] }, { "name": "pegasus1.1", "options": ["visual", "conversation"] } ]
Create a new index by calling
client.indexwith the Index name and engine configuration parameters. Use a unique and identifiable name for the Index.
index = client.index.create( name="<YOUR_INDEX_NAME>", engines=engines ) print(f"A new index has been created: Index id={index.id} name={index.name} engines={index.engines}")
The index.id field represents the unique identifier of your new index. This identifier is crucial for indexing videos in their correct location.
With these steps completed, you're now ready to dive in and develop the application!
Walkthrough for Video Highlight Generator
In this tutorial, we will build a Streamit application with a minimal frontend. Below is the directory structure:
. ├── app.py ├── requirements.txt ├── utils.py ├── .env └── .gitignore
1 - Creating the Streamlit Application
Now that you've completed all the above steps, it's time to build the Streamlit application. This app provides a simple way for you to upload a video, generate highlight chapters, and create segmented video clips. The application consists of two main files:
main.py: Contains the application flow with a minimal page layout
utils.py: Houses all the essential utility functions for the application
You can find the required dependencies to set up a virtual environment in the requirements.txt file.
To get started, create a virtual Python environment and configure it for the application:
pip install -r requirements.txt
2 - Setting up the utility function for the operation
In this section, we'll explore how to generate highlight chapters and handle longer videos for indexing. We'll also cover creating video segments from the highlighted chapters by applying the results to the video indexed in section 2.2.
2.1 - Generating the Highlight Chapter and Handling the Video Processing
First, we'll import the necessary libraries: moviepy.editor, m3u8, io, urllib.parse, yt_dlp, and the Twelve Lab SDK. We'll also set up the API Key and Index ID environment variables. We'll discuss the importance of these libraries and their functions in detail.
import os import requests from moviepy.editor import VideoFileClip from twelvelabs import TwelveLabs from dotenv import load_dotenv import io import m3u8 from urllib.parse import urljoin import yt_dlp # Load environment variables load_dotenv() API_KEY = os.getenv("API_KEY") INDEX_ID = os.getenv("INDEX_ID") def seconds_to_mmss(seconds): minutes, seconds = divmod(int(seconds), 60) return f"{minutes:02d}:{seconds:02d}" def mmss_to_seconds(mmss): minutes, seconds = map(int, mmss.split(':')) return minutes * 60 + seconds def generate_timestamps(client, video_id, start_time=0): try: gist = client.generate.summarize(video_id=video_id, type="chapter") chapter_text = "\n".join([f"{seconds_to_mmss(chapter.start + start_time)}-{chapter.chapter_title}" for chapter in gist.chapters]) return chapter_text, gist.chapters[-1].start + start_time except Exception as e: raise Exception(f"An error occurred while generating timestamps: {str(e)}") # Utitily function to trim the video based on the time stamps def trim_video(input_path, output_path, start_time, end_time): with VideoFileClip(input_path) as video: new_video = video.subclip(start_time, end_time) new_video.write_videofile(output_path, codec="libx264", audio_codec="aac") # Based on the speicific Index_ID, fetching all the video_id def fetch_existing_videos(): url = f"https://api.twelvelabs.io/v1.2/indexes/{INDEX_ID}/videos?page=1&page_limit=10&sort_by=created_at&sort_option=desc" headers = {"accept": "application/json", "x-api-key": API_KEY, "Content-Type": "application/json"} response = requests.get(url, headers=headers) if response.status_code == 200: return response.json()['data'] else: raise Exception(f"Failed to fetch videos: {response.text}") # Utility function to retrieve the URL of the video with video_id def get_video_url(video_id): url = f"https://api.twelvelabs.io/v1.2/indexes/{INDEX_ID}/videos/{video_id}" headers = {"accept": "application/json", "x-api-key": API_KEY} response = requests.get(url, headers=headers) if response.status_code == 200: data = response.json() return data['hls']['video_url'] if 'hls' in data and 'video_url' in data['hls'] else None else: raise Exception(f"Failed to get video URL: {response.text}") # Utility function to handle and process the video clips larger than 30 mins def process_video(client, video_path, video_type): with VideoFileClip(video_path) as clip: duration = clip.duration if duration > 3600: raise Exception("Video duration exceeds 1 hour. Please upload a shorter video.") if video_type == "Basic Video (less than 30 mins)": task = client.task.create(index_id=INDEX_ID, file=video_path) task.wait_for_done(sleep_interval=5) if task.status == "ready": timestamps, _ = generate_timestamps(client, task.video_id) return timestamps, task.video_id else: raise Exception(f"Indexing failed with status {task.status}") elif video_type == "Podcast (30 mins to 1 hour)": trimmed_path = os.path.join(os.path.dirname(video_path), "trimmed_1.mp4") trim_video(video_path, trimmed_path, 0, 1800) task1 = client.task.create(index_id=INDEX_ID, file=trimmed_path) task1.wait_for_done(sleep_interval=5) os.remove(trimmed_path) if task1.status != "ready": raise Exception(f"Indexing failed with status {task1.status}") timestamps, end_time = generate_timestamps(client, task1.video_id) if duration > 1800: trimmed_path = os.path.join(os.path.dirname(video_path), "trimmed_2.mp4") trim_video(video_path, trimmed_path, 1800, int(duration)) task2 = client.task.create(index_id=INDEX_ID, file=trimmed_path) task2.wait_for_done(sleep_interval=5) os.remove(trimmed_path) if task2.status != "ready": raise Exception(f"Indexing failed with status {task2.status}") timestamps_2, _ = generate_timestamps(client, task2.video_id, start_time=end_time) timestamps += "\n" + timestamps_2 return timestamps, task1.video_id # Utility function to render the video on the UI def get_hls_player_html(video_url): return f""" <script src="https://cdn.jsdelivr.net/npm/hls.js@latest"></script> <style> #video-container {{ position: relative; width: 100%; padding-bottom: 56.25%; overflow: hidden; border-radius: 10px; box-shadow: 0 4px 6px rgba(0, 0, 0, 0.1); }} #video {{ position: absolute; top: 0; left: 0; width: 100%; height: 100%; object-fit: contain; }} </style> <div id="video-container"> <video id="video" controls></video> </div> <script> var video = document.getElementById('video'); var videoSrc = "{video_url}"; if (Hls.isSupported()) {{ var hls = new Hls(); hls.loadSource(videoSrc); hls.attachMedia(video); hls.on(Hls.Events.MANIFEST_PARSED, function() {{ video.pause(); }}); }} else if (video.canPlayType('application/vnd.apple.mpegurl')) {{ video.src = videoSrc; video.addEventListener('loadedmetadata', function() {{ video.pause(); }}); }} </script> """
A. Input: Video Content Handling
This application heavily relies on the process_video function. It supports two types of video content: short videos under 30 minutes and longer podcast-style videos up to an hour. For longer videos, further processing is carried out by splitting the content into manageable chunks using the trim_video utility function, ensuring accurate analysis even for lengthy recordings.
B. Processing: Video Indexing, Analysis, and Chapter Generation
For short videos under 30 minutes, video indexing begins with Marengo 2.6 (Embedding Engine), which generates the video ID. It then interacts with the generate function in TwelveLabs SDK, Pegasus 1.1 (Generative Engine), to analyze the video content and generate timestamp-based chapters for the indexed video.
For longer videos, 30-minute chunks are created, indexed one by one, and then analyzed to generate timestamp-based chapters. The end timestamp of the first chunk becomes the start of the next chunk.
The get_video_url function retrieves the video URL of the indexed video to render it in the application. The get_hls_player_html(video_url) function is used to render the video.
C. Return Values: Highlights with Timestamps
The generation process produces timestamps in seconds. However, YouTube descriptions require highlights in minutes and seconds (mm:ss) format. Therefore, seconds_to_mmss is used for conversion, while mmss_to_seconds facilitates the conversion of minutes to seconds, which is then used to trim video clips based on chapters.
All user-uploaded videos are indexed by the Index ID created earlier. Users can access indexed videos using fetch_existing_videos(). This provides the video ID, which is sent directly to the generative engine by calling generate_timestamp.
2.2 - Retrieve Video from Index and Segment Based on Results
This section focuses on trimming video segments based on highlight timestamps. Utility functions work together to download, parse, and create segments based on timestamps.
# Utility function to download the indexed video with the url from video_id def download_video(url, output_filename): ydl_opts = { 'format': 'best', 'outtmpl': output_filename, } with yt_dlp.YoutubeDL(ydl_opts) as ydl: ydl.download([url]) # Utitily Function to Parse the Segment def parse_segments(segment_text): lines = segment_text.strip().split('\n') segments = [] for i, line in enumerate(lines): start, description = line.split('-', 1) start_time = mmss_to_seconds(start.strip()) if i < len(lines) - 1: end = lines[i+1].split('-')[0] end_time = mmss_to_seconds(end.strip()) else: end_time = None segments.append((start_time, end_time, description.strip())) return segments # Utiltiy function to create the video segment def create_video_segments(video_url, segment_info): full_video = "full_video.mp4" segments = parse_segments(segment_info) try: # Download the full video clip download_video(video_url, full_video) for i, (start_time, end_time, description) in enumerate(segments): output_file = f"{i+1:02d}_{description.replace(' ', '_').lower()}.mp4" trim_video(full_video, output_file, start_time, end_time) yield output_file, description os.remove(full_video) except yt_dlp.utils.DownloadError as e: raise Exception(f"An error occurred while downloading: {str(e)}") except Exception as e: raise Exception(f"An unexpected error occurred: {str(e)}") # Function to downlaod the video segments after the trimming is done def download_video_segment(video_id, start_time, end_time=None): video_url = get_video_url(video_id) if not video_url: raise Exception("Failed to get video URL") playlist = m3u8.load(video_url) start_seconds = mmss_to_seconds(start_time) end_seconds = mmss_to_seconds(end_time) if end_time else None total_duration = 0 segments_to_download = [] for segment in playlist.segments: if total_duration >= start_seconds and (end_seconds is None or total_duration < end_seconds): segments_to_download.append(segment) total_duration += segment.duration if end_seconds is not None and total_duration >= end_seconds: break buffer = io.BytesIO() for segment in segments_to_download: segment_url = urljoin(video_url, segment.uri) response = requests.get(segment_url) if response.status_code == 200: buffer.write(response.content) else: raise Exception(f"Failed to download segment: {segment_url}") buffer.seek(0) return buffer.getvalue()
The download_video function uses the yt-dlp library to download entire videos. To create multiple segments from a single video, the full video file is downloaded.
The parse_segments function converts the generated timestamp information into a programmatically usable format. It breaks down chapter information into start times, end times, and descriptions, preparing for video segmentation.
create_video_segments ties everything together. After downloading the entire video, it parses segment information to create individual video clips for each chapter. This function returns each segment along with its description.
Video segments can be downloaded using the download_video_segment function. For creating chapter previews or extracting specific parts of longer videos, it uses the HLS (HTTP Live Streaming) protocol to download only the required video segments.
This process offers content creators the ability to not only generate timestamps but also create tangible video segments for use in their production workflows and editing process 🎬✂️️.
3 - Instruction Flow of the Streamlit Application
This section focuses on the main application function, designed for a minimal UI and streamlined instructions flow by utilizing key utility functions.
The application begins by configuring the Streamlit page and applying custom CSS for an attractive, themed interface. It then initializes session state variables to maintain data consistency across reruns. For the complete code, see app.py. Essential utility functions are discussed below.
# Uplaoding feature and the processing of the video def upload_and_process_video(): video_type = st.selectbox("Select video type:", ["Basic Video (less than 30 mins)", "Podcast (30 mins to 1 hour)"]) uploaded_file = st.file_uploader("Choose a video file", type=["mp4", "mov", "avi"]) if uploaded_file and st.button("Process Video", key="process_video_button"): with tempfile.NamedTemporaryFile(delete=False, suffix=".mp4") as tmp_file: tmp_file.write(uploaded_file.read()) video_path = tmp_file.name try: with st.spinner("Processing video..."): client = TwelveLabs(api_key=API_KEY) timestamps, video_id = process_video(client, video_path, video_type) st.success("Video processed successfully!") st.session_state.timestamps = timestamps st.session_state.video_id = video_id st.session_state.video_url = get_video_url(video_id) if st.session_state.video_url: st.video(st.session_state.video_url) else: st.error("Failed to retrieve video URL.") except Exception as e: st.error(str(e)) finally: os.unlink(video_path) # Selecting the existing video from the Index and generating timestamps highlight def select_existing_video(): try: existing_videos = fetch_existing_videos() video_options = {f"{video['metadata']['filename']} ({video['_id']})": video['_id'] for video in existing_videos} if video_options: selected_video = st.selectbox("Select a video:", list(video_options.keys())) video_id = video_options[selected_video] st.session_state.video_id = video_id st.session_state.video_url = get_video_url(video_id) if st.session_state.video_url: st.markdown(f"### Selected Video: {selected_video}") st.video(st.session_state.video_url) else: st.error("Failed to retrieve video URL.") if st.button("Generate Timestamps", key="generate_timestamps_button"): with st.spinner("Generating timestamps..."): client = TwelveLabs(api_key=API_KEY) timestamps, _ = generate_timestamps(client, video_id) st.session_state.timestamps = timestamps else: st.warning("No existing videos found in the index.") except Exception as e: st.error(str(e))
The main interface features two tabs: one for uploading new videos and another for selecting existing ones. The app handles errors gracefully and provides user feedback throughout. During lengthy video segmentation processes, progress bars and status messages keep users informed. A feature to clear all segments helps manage storage and allows users to start fresh.
upload_and_process_video(): Handles video file uploads and processing. It manages both regular videos (under 30 minutes) and longer videos, converting longer ones into chunks before indexing. Finally, it employs the generative engine.select_existing_video(): Allows users to choose from previously uploaded videos stored in the TwelveLabs index.
The application uses st.session_state to store and retrieve crucial information such as video URLs, IDs, and generated timestamps. This approach enables data persistence across app re-runs, ensuring a seamless user experience for multi-step operations. By maintaining this state, the app can display processed videos, use them for further operations, and work with generated timestamps without requiring users to re-upload or reprocess data.
# Function to Display the Segment and also Download def display_segment(file_name, description, segment_index): if os.path.exists(file_name): st.write(f"### {description}") st.video(file_name) with open(file_name, "rb") as file: file_contents = file.read() unique_key = f"download_{segment_index}_{uuid.uuid4()}" st.download_button( label=f"Download: {description}", data=file_contents, file_name=file_name, mime="video/mp4", key=unique_key ) st.markdown("---") else: st.warning(f"File {file_name} not found. It may have been deleted or moved.") # Function to process the segment def process_and_display_segments(): if not st.session_state.video_url: st.error("Video URL not found. Please reprocess the video.") return segment_generator = create_video_segments(st.session_state.video_url, st.session_state.timestamps) progress_bar = st.progress(0) status_text = st.empty() st.session_state.video_segments = [] # Reset video segments total_segments = len(st.session_state.timestamps.split('\n')) for i, (file_name, description) in enumerate(segment_generator, 1): st.session_state.video_segments.append((file_name, description)) display_segment(file_name, description, i-1) # Pass the index here progress = i / total_segments progress_bar.progress(progress) status_text.text(f"Processing segment {i}/{total_segments}...") progress_bar.progress(1.0) status_text.text("All segments processed!") # Function to display the timestamps and the segments def display_timestamps_and_segments(): if st.session_state.timestamps: st.subheader("YouTube Chapter Timestamps") st.write("Copy the Timestamp description and add it to the Youtube Video Description") st.code(st.session_state.timestamps, language="") if st.button("Create Video Segments", key="create_segments_button"): try: process_and_display_segments() except Exception as e: st.error(f"Error creating video segments: {str(e)}") st.exception(e) # This will display the full traceback if st.session_state.video_segments: st.subheader("Video Segments") for index, (file_name, description) in enumerate(st.session_state.video_segments): display_segment(file_name, description, index) if st.button("Clear all segments", key="clear_segments_button"): for file_name, _ in st.session_state.video_segments: if os.path.exists(file_name): os.remove(file_name) st.session_state.video_segments = [] st.success("All segment files have been cleared.") st.experimental_rerun()
process_and_display_segments(): Manages the creation and display of video segments based on generated timestamps.display_timestamps_and_segments(): Presents generated timestamps in a copyable format and provides options to create and display video segments.display_segment(): Renders individual video segments, complete with a download button for each.
The display_segment function takes a file name, description, and segment index as inputs. It checks for the video file's existence, displays the segment's description, plays the video using Streamlit's st.video function, and provides a uniquely keyed download button. If the file is not found, it shows a warning message.
The process_and_display_segments function creates and displays all video segments. It first checks for a video URL in the session state, showing an error message if absent. Otherwise, it uses create_video_segments to generate segments based on provided timestamps, displaying a progress bar and status text during processing. Each segment is added to the session state and displayed using the display_segment function.
The display_timestamps_and_segments function integrates all components. It displays YouTube chapter timestamps if available and provides a button to create video segments. When clicked, this button triggers the process_and_display_segments function. For existing segments, it displays them and offers an option to clear all segments, removing files and resetting the application state.
Below is the Demo Application Example:
As can be seen in the above demo, the video is uploaded and indexed to generate the highlight with timestamp, which can be easily configured to fit into a YouTube description. You can observe how the highlight is implemented in the next step of the demo, as well as how segments are generated from the highlight.
To explore Twelve Labs in diverse contexts, try applying the chapter use cases to various sectors such as editing, education, or any other area that piques your interest.
More Ideas to Experiment with the Tutorial
Understanding how an application works and its development process empowers you to implement innovative ideas and create products that meet users' needs. Here are some potential use cases for video content creators, similar to the one discussed in the tutorial:
📽️ YouTube Content Creators: Generate chapter highlight markers to enhance video navigation.
🎓 Educational Videos: Enable students to easily select specific sections of interest in long tutorial videos.
🎥 Content Segmentation: Effortlessly create video clips ready for upload.
Conclusion
This blog post provides a detailed explanation of the video highlight chapter generation process developed with Twelve Labs to cater to content creators' needs. Thank you for following along with the tutorial. We look forward to your ideas on improving the user experience and solving various challenges.
Additional Resources
Learn more about the engines used for the generation task, Marengo 2.6 (Embedding Engine) and Pegasus 1.1 (Generator Engine). To further explore Twelve Labs and enhance your understanding of video content analysis, check out these valuable resources:
Discord Community: Join our vibrant community of developers and enthusiasts to discuss ideas, ask questions, and share your projects. Join the Twelve Labs Discord
Sample Applications: Explore a variety of sample applications to inspire your next project or learn new implementation techniques.
Explore Tutorials: Dive deeper into Twelve Labs capabilities with our comprehensive tutorials.
We encourage you to leverage these resources to expand your knowledge and create innovative applications using Twelve Labs video understanding technology.
Related articles



Platform
Enterprise
© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved

Platform
Enterprise
© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved




Platform
Enterprise
© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved