
WHAT OUR PARTNERS ARE SAYING
Building a Multimodal Retrieval-Augmented Generation Application with Twelve Labs and Milvus

Hrishikesh Yadav
Discover your perfect style with Fashion AI Assistant! This application combines the power of visual search, conversational AI, and video understanding to innovate how you explore and find fashion. Whether you're chatting about your style preferences or sharing a photo of an outfit you want, the application helps you discover exactly what you're looking for ✨
Discover your perfect style with Fashion AI Assistant! This application combines the power of visual search, conversational AI, and video understanding to innovate how you explore and find fashion. Whether you're chatting about your style preferences or sharing a photo of an outfit you want, the application helps you discover exactly what you're looking for ✨

In this article
No headings found on page
Join our newsletter
Join our newsletter
Receive the latest advancements, tutorials, and industry insights in video understanding
Receive the latest advancements, tutorials, and industry insights in video understanding
Search, analyze, and explore your videos with AI.
Jan 22, 2025
13 Min
Copy link to article
Introduction
Ever wondered what it would be like to have a personal fashion advisor available 24/7 who understands not just your words but also your visual preferences? Imagine showing a photo of an outfit you like and getting instant AI suggestions for similar styles, or describing your dream look and receiving matching outfit recommendations 👚
Our Fashion AI assistant application is built for next-generation product discovery. This tutorial explores our advanced fashion recommendation system that combines multimodal retrieval with conversational AI. The system uses TwelveLabs Embed - Marengo-retrieval-2.7 model to generate embeddings from both text and video content, enabling seamless search across different data types.
The application uses Milvus as its vector database for efficient similarity search and integrates OpenAI's gpt-3.5 for natural language processing. It handles fashion queries through both text and image inputs, finding relevant product descriptions and precise video timestamps to show users exactly where their desired items appear.
This powerful combination creates a system that understands both textual and visual queries while delivering contextualized responses enriched with multimodal content.
Let's explore how this application works and how you can build similar solutions using the TwelveLabs Python SDK and Milvus Python SDK.
You can explore the demo of the application here: Fashion AI Chat App.
If you want to access the code and experiment with the app directly, you can use this Replit Template.
Prerequisites
Generate an API key by signing up at the Twelve Labs Playground.
Setting up the Milvus Server Installation by following Installation Guide.
Find the repository for this application on Fashion AI Chat Application.
There are several things you should already be familiar with - Python, Streamlit, CSS
Working of the Application
Here's an overview of how the application works and how its components interact:
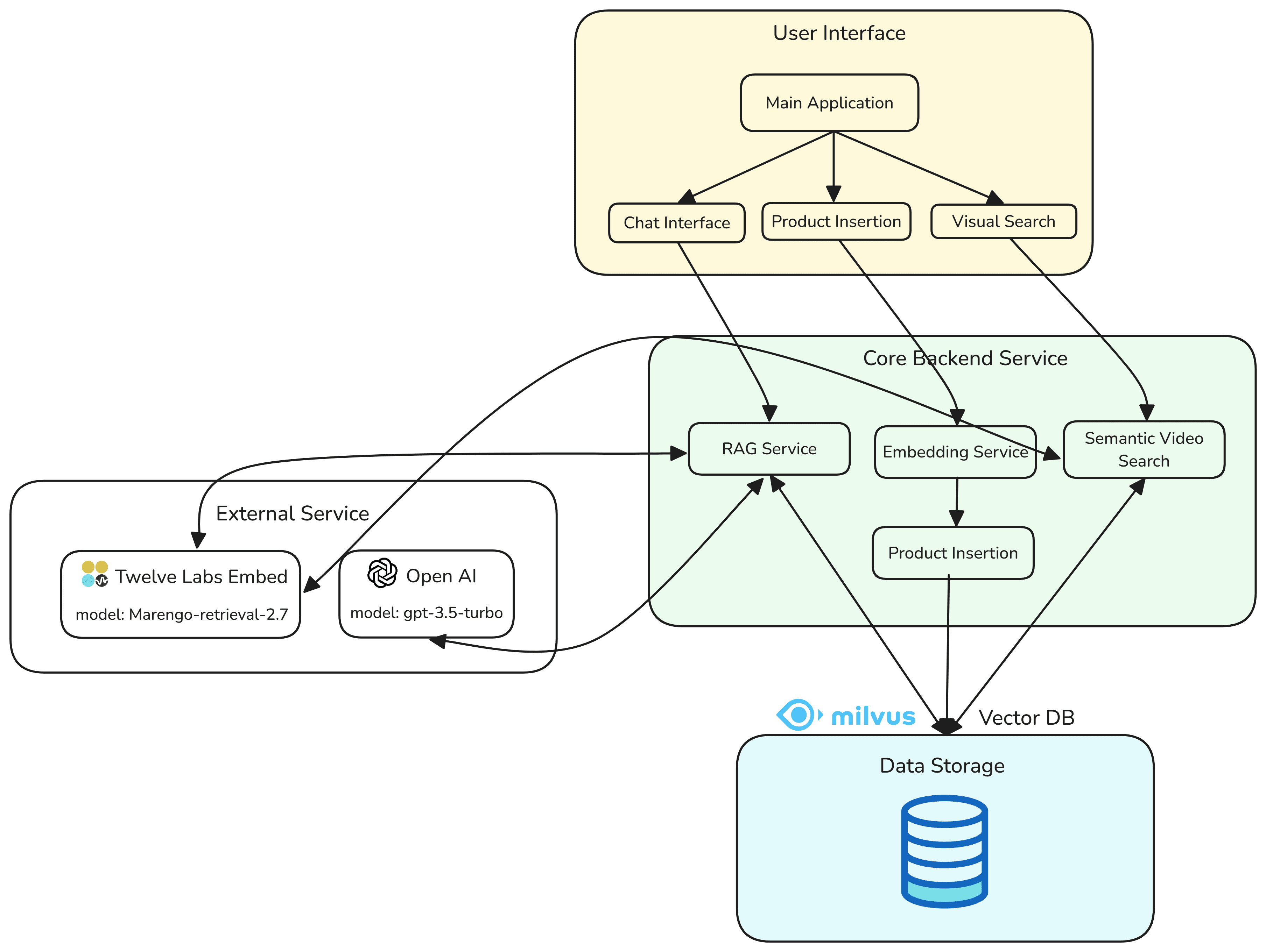
The application has three main features:
Embedding Generation and Insertion into the Milvus Vector Database
Query Image to Video Segment Retrieval
Chat Retrieval Augmented Generation (RAG) for Multimodal Retrieval (Text and Video Segments)
This tutorial application shows how to store product catalog data in a vector database using Twelve Labs Embed - Marengo-retrieval-2.7. The embeddings for both text and video content are stored in the same Milvus vector database collection. For clarity and reusability, the Twelve Labs embedding function is defined in each utility function.
To make the application work as expected, you must insert the embedding data into the collection, or you can refer to the sample data provided here used in this application.
Preparation Steps
Obtain your API key from the Twelve Labs Playground and set up your environment variable.
Clone the project from Github or use the Replit Template. We recommend using the Replit template since it comes with a predefined virtual environment. Remember to add the secret file and consult the secret key replit docs during setup.
Create a
.envfile containing your Twelve Labs, Milvus Connection, and OpenAI API keys for the LLM model.
For the Milvus vector database, credentials are configured using Zilliz Cloud, though other connection methods are available in the Installation Guide.
TWELVELABS_API_KEY="your_twelvelabs_key" COLLECTION_NAME="your_collection_name" URL="your_milvus_url" TOKEN="your_milvus_token" OPENAI_API_KEY="your_openai_key"
TWELVELABS_API_KEY="your_twelvelabs_key" COLLECTION_NAME="your_collection_name" URL="your_milvus_url" TOKEN="your_milvus_token" OPENAI_API_KEY="your_openai_key"
Once you've completed these steps, you're ready to start developing!
Walkthrough for Fashion Chat Application
In this tutorial, we'll create a Streamlit application with a minimal frontend. Let's look at the directory structure:
├── pages/ │ ├── add_product_page.py │ └── visual_search.py ├── .gitignore ├── app.py └── utils.py └── requirements.txt
├── pages/ │ ├── add_product_page.py │ └── visual_search.py ├── .gitignore ├── app.py └── utils.py └── requirements.txt
Creating the Streamlit Application
Now that you've finished the setup, let's build the Streamlit application.
Find all required dependencies for creating your virtual environment here: requirements.txt
Create a virtual Python environment, then set up the environment for the application using the following command:
pip install -r requirements.txt
pip install -r requirements.txt
Defining the Utility function
This section describes the utility.py, which contains the core logic and implementation. Let's examine each subsection:
1 - Setting up the Connection
The first step loads environment variables and establishes connections with OpenAI for LLM access, Milvus for collection management, and Twelve Labs initialization.
# Load environment variables COLLECTION_NAME = os.getenv('COLLECTION_NAME') URL = os.getenv('URL') TOKEN = os.getenv('TOKEN') TWELVELABS_API_KEY = os.getenv('TWELVELABS_API_KEY') # Initialize connections openai_client = OpenAI() connections.connect(uri=URL, token=TOKEN) collection = Collection(COLLECTION_NAME) collection.load() twelvelabs_client = TwelveLabs(api_key=TWELVELABS_API_KEY)
# Load environment variables COLLECTION_NAME = os.getenv('COLLECTION_NAME') URL = os.getenv('URL') TOKEN = os.getenv('TOKEN') TWELVELABS_API_KEY = os.getenv('TWELVELABS_API_KEY') # Initialize connections openai_client = OpenAI() connections.connect(uri=URL, token=TOKEN) collection = Collection(COLLECTION_NAME) collection.load() twelvelabs_client = TwelveLabs(api_key=TWELVELABS_API_KEY)
2 - Generation of Embedding with Twelve Labs Embed API
This section covers embedding generation using the Twelve Labs SDK with Marengo-retrieval-2.7 for multimodal retrieval. The solution integrates text and video processing to create efficient search embeddings.
# Generate text and segmented video embeddings for a product def generate_embedding(product_info): try: st.write("Starting embedding generation process...") st.write(f"Processing product: {product_info['title']}") # Initialize the Twelve Labs client twelvelabs_client = TwelveLabs(api_key=TWELVELABS_API_KEY) st.write("TwelveLabs client initialized successfully") st.write("Attempting to generate text embedding...") # Formatting the Text Data of Product Catalogue text = f"product type: {product_info['title']}. " \ f"product description: {product_info['desc']}. " \ f"product category: fashion apparel." st.write(f"Generating embedding for text: {text}") # Generating the Text Embeddings text_embedding = twelvelabs_client.embed.create( model_name="Marengo-retrieval-2.7", text=text ).text_embedding.segments[0].embeddings_float st.write("Text embedding generated successfully") # Create and wait for video embedding task st.write("Creating video embedding task...") video_task = twelvelabs_client.embed.task.create( model_name="Marengo-retrieval-2.7", video_url=product_info['video_url'], video_clip_length=6 ) def on_task_update(task): st.write(f"Video processing status: {task.status}") st.write("Waiting for video processing to complete...") video_task.wait_for_done(sleep_interval=2, callback=on_task_update) # Retrieve segmented video embeddings video_task = video_task.retrieve() if not video_task.video_embedding or not video_task.video_embedding.segments: raise Exception("Failed to retrieve video embeddings") video_segments = video_task.video_embedding.segments st.write(f"Retrieved {len(video_segments)} video segments") video_embeddings = [] for segment in video_segments: video_embeddings.append({ 'embedding': segment.embeddings_float, 'metadata': { 'scope': 'clip', 'start_time': segment.start_offset_sec, 'end_time': segment.end_offset_sec, 'video_url': product_info['video_url'] } }) return { 'text_embedding': text_embedding, 'video_embeddings': video_embeddings }, None except Exception as e: st.error("Error in embedding generation") st.error(f"Error message: {str(e)}") return None, str(e)
# Generate text and segmented video embeddings for a product def generate_embedding(product_info): try: st.write("Starting embedding generation process...") st.write(f"Processing product: {product_info['title']}") # Initialize the Twelve Labs client twelvelabs_client = TwelveLabs(api_key=TWELVELABS_API_KEY) st.write("TwelveLabs client initialized successfully") st.write("Attempting to generate text embedding...") # Formatting the Text Data of Product Catalogue text = f"product type: {product_info['title']}. " \ f"product description: {product_info['desc']}. " \ f"product category: fashion apparel." st.write(f"Generating embedding for text: {text}") # Generating the Text Embeddings text_embedding = twelvelabs_client.embed.create( model_name="Marengo-retrieval-2.7", text=text ).text_embedding.segments[0].embeddings_float st.write("Text embedding generated successfully") # Create and wait for video embedding task st.write("Creating video embedding task...") video_task = twelvelabs_client.embed.task.create( model_name="Marengo-retrieval-2.7", video_url=product_info['video_url'], video_clip_length=6 ) def on_task_update(task): st.write(f"Video processing status: {task.status}") st.write("Waiting for video processing to complete...") video_task.wait_for_done(sleep_interval=2, callback=on_task_update) # Retrieve segmented video embeddings video_task = video_task.retrieve() if not video_task.video_embedding or not video_task.video_embedding.segments: raise Exception("Failed to retrieve video embeddings") video_segments = video_task.video_embedding.segments st.write(f"Retrieved {len(video_segments)} video segments") video_embeddings = [] for segment in video_segments: video_embeddings.append({ 'embedding': segment.embeddings_float, 'metadata': { 'scope': 'clip', 'start_time': segment.start_offset_sec, 'end_time': segment.end_offset_sec, 'video_url': product_info['video_url'] } }) return { 'text_embedding': text_embedding, 'video_embeddings': video_embeddings }, None except Exception as e: st.error("Error in embedding generation") st.error(f"Error message: {str(e)}") return None, str(e)
The process begins by structuring and formatting text to ensure consistent, meaningful embeddings. Video embedding follows, with status monitoring and progress tracking. Each video segment is set to 6 seconds (video_clip_length=6).
Metadata tracking is essential for maintaining traceability and enabling precise video segment and text searching. The results are then stored in the Milvus vector database collection.
3 - Embedding Insertion into the Milvus Vector Database
Vector databases efficiently store and retrieve high-dimensional embedding data. This section demonstrates how to insert both text and video embeddings into the Milvus vector database with proper metadata management and error handling.
# Insert text and all video segment embeddings into Milvus Collection def insert_embeddings(embeddings_data, product_info): try: metadata = { "product_id": product_info['product_id'], "title": product_info['title'], "description": product_info['desc'], "video_url": product_info['video_url'], "link": product_info['link'] } # Insert text embedding text_entry = { "id": int(uuid.uuid4().int & (1<<63)-1), "vector": embeddings_data['text_embedding'], "metadata": metadata, "embedding_type": "text" } collection.insert([text_entry]) st.write("Text embedding inserted successfully") # Insert each video segment embedding for video_segment in embeddings_data['video_embeddings']: video_entry = { "id": int(uuid.uuid4().int & (1<<63)-1), "vector": video_segment['embedding'], "metadata": {**metadata, **video_segment['metadata']}, "embedding_type": "video" } collection.insert([video_entry]) st.write(f"Inserted {len(embeddings_data['video_embeddings'])} video segment embeddings") return True except Exception as e: st.error(f"Error inserting embeddings: {str(e)}") return False
# Insert text and all video segment embeddings into Milvus Collection def insert_embeddings(embeddings_data, product_info): try: metadata = { "product_id": product_info['product_id'], "title": product_info['title'], "description": product_info['desc'], "video_url": product_info['video_url'], "link": product_info['link'] } # Insert text embedding text_entry = { "id": int(uuid.uuid4().int & (1<<63)-1), "vector": embeddings_data['text_embedding'], "metadata": metadata, "embedding_type": "text" } collection.insert([text_entry]) st.write("Text embedding inserted successfully") # Insert each video segment embedding for video_segment in embeddings_data['video_embeddings']: video_entry = { "id": int(uuid.uuid4().int & (1<<63)-1), "vector": video_segment['embedding'], "metadata": {**metadata, **video_segment['metadata']}, "embedding_type": "video" } collection.insert([video_entry]) st.write(f"Inserted {len(embeddings_data['video_embeddings'])} video segment embeddings") return True except Exception as e: st.error(f"Error inserting embeddings: {str(e)}") return False
After defining the id, vector, and metadata, the embedding_type is specified to accommodate different formats in the same collection space. The data is then inserted using the collection.insert method.
4 - Semantic Search Implementation for Image to Video Retrieval
Semantic search with image queries enables finding similar video content. This implementation combines Twelve Labs embedding capabilities with Milvus vector search. Here's how the utility function searched_similar_videos works:
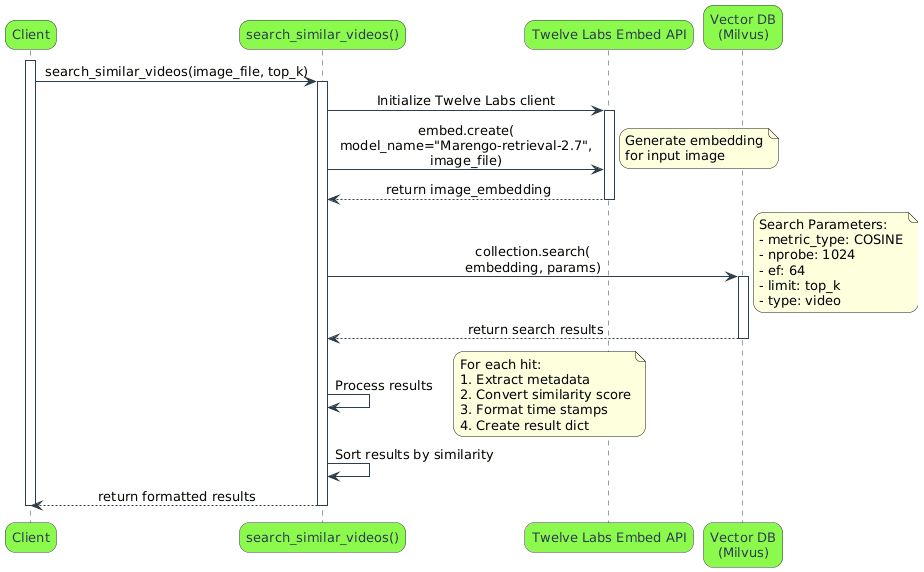
First, the system loads and reads the product image to find video segments containing similar products. Twelve Labs embed then converts the image into an embedding for semantic search against stored video embeddings in the Milvus collection.
# Load and Read Query Image image_path = "path/to/your/image.jpg" with open(image_path, 'rb') as f: image_file = f.read() # Intializing of client and Generation of Image Emebedding twelvelabs_client = TwelveLabs(api_key=TWELVELABS_API_KEY) image_embedding = twelvelabs_client.embed.create( model_name="Marengo-retrieval-2.7", image_file=image_file ).image_embedding.segments[0].embeddings_float
# Load and Read Query Image image_path = "path/to/your/image.jpg" with open(image_path, 'rb') as f: image_file = f.read() # Intializing of client and Generation of Image Emebedding twelvelabs_client = TwelveLabs(api_key=TWELVELABS_API_KEY) image_embedding = twelvelabs_client.embed.create( model_name="Marengo-retrieval-2.7", image_file=image_file ).image_embedding.segments[0].embeddings_float
The search uses cosine similarity and cluster parameters to balance speed and accuracy. When collection.search runs with embedding_type == 'video' and other parameters, it retrieves the specified number of product video segments.
search_params = { "metric_type": "COSINE", "params": { "nprobe": 1024, "ef": 64 } } # Search relevant video segments results = collection.search( data=[image_embedding], anns_field="vector", param=search_params, limit=2, expr="embedding_type == 'video'", output_fields=["metadata"] )
search_params = { "metric_type": "COSINE", "params": { "nprobe": 1024, "ef": 64 } } # Search relevant video segments results = collection.search( data=[image_embedding], anns_field="vector", param=search_params, limit=2, expr="embedding_type == 'video'", output_fields=["metadata"] )
The system processes the results, converts similarity scores to percentages for clarity, and organizes the metadata into a structured dictionary.
search_results = [] for hits in results: for hit in hits: metadata = hit.metadata # Convert score from [-1,1] to [0,100] range similarity = round((hit.score + 1) * 50, 2) similarity = max(0, min(100, similarity)) search_results.append({ 'Title': metadata.get('title', ''), 'Description': metadata.get('description', ''), 'Link': metadata.get('link', ''), 'Start Time': f"{metadata.get('start_time', 0):.1f}s", 'End Time': f"{metadata.get('end_time', 0):.1f}s", 'Video URL': metadata.get('video_url', ''), 'Similarity': f"{similarity}%", 'Raw Score': hit.score }) # Sort by similarity score in descending order search_results.sort(key=lambda x: float(x['Similarity'].rstrip('%')), reverse=True)
search_results = [] for hits in results: for hit in hits: metadata = hit.metadata # Convert score from [-1,1] to [0,100] range similarity = round((hit.score + 1) * 50, 2) similarity = max(0, min(100, similarity)) search_results.append({ 'Title': metadata.get('title', ''), 'Description': metadata.get('description', ''), 'Link': metadata.get('link', ''), 'Start Time': f"{metadata.get('start_time', 0):.1f}s", 'End Time': f"{metadata.get('end_time', 0):.1f}s", 'Video URL': metadata.get('video_url', ''), 'Similarity': f"{similarity}%", 'Raw Score': hit.score }) # Sort by similarity score in descending order search_results.sort(key=lambda x: float(x['Similarity'].rstrip('%')), reverse=True)
The sorted results can then be displayed. The UI implementation is available in vision_search.
5 - Developing Retrieval Augmented Generation System
This section focuses on question-answering in the fashion assistant context, combining multimodal retrieval with LLM (gpt-3.5) for contextual responses. It emphasizes multimodal retrieval from text and video data with metadata for effective personalization. The get_rag_response function implements the RAG functionality.
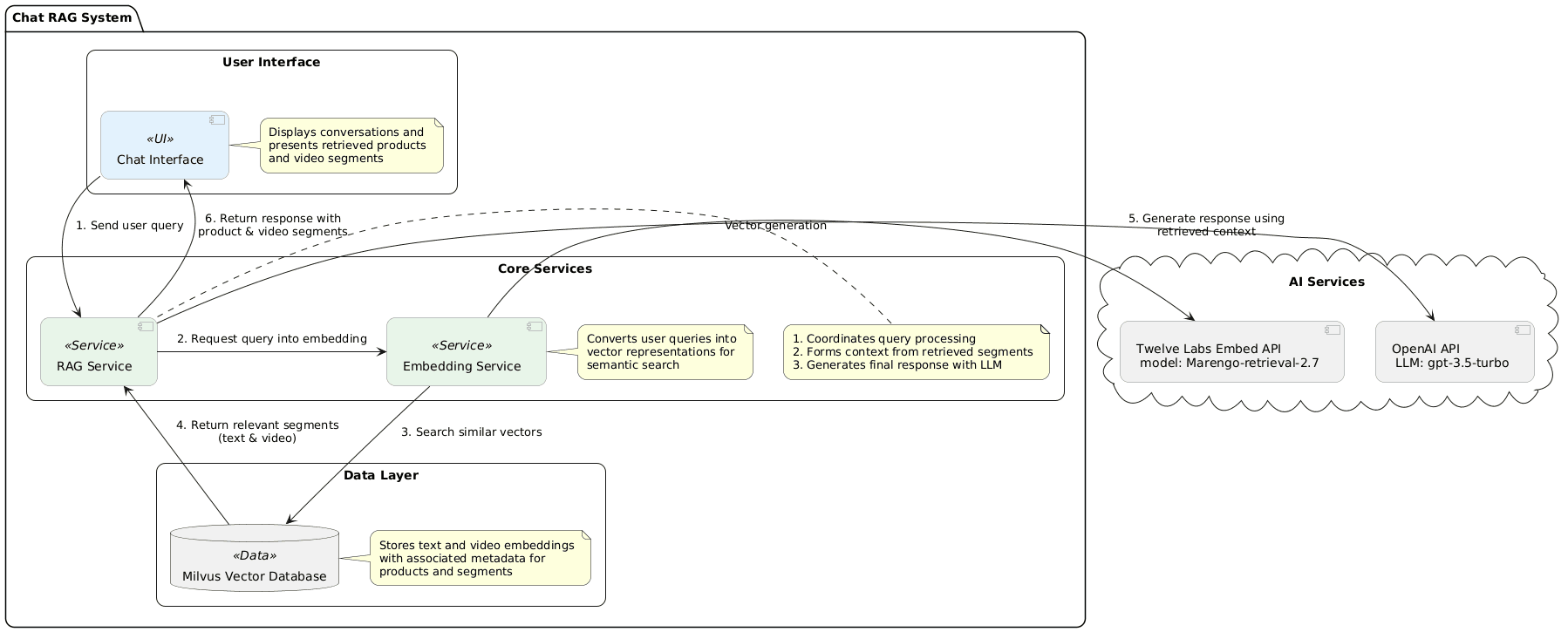
The process begins by converting the user's question and context into a text embedding using the Marengo-retrieval-2.7 engine with Twelve Labs embed, enabling semantic search across the database.
# Sample question question_with_context = f"fashion product: Suggest me black dresses for a party" # Generate embedding for the question question_embedding = twelvelabs_client.embed.create( model_name="Marengo-retrieval-2.7", text=question_with_context ).text_embedding.segments[0].embeddings_float
# Sample question question_with_context = f"fashion product: Suggest me black dresses for a party" # Generate embedding for the question question_embedding = twelvelabs_client.embed.create( model_name="Marengo-retrieval-2.7", text=question_with_context ).text_embedding.segments[0].embeddings_float
After setting semantic search parameters, the system performs separate collection searches for text and video segments. Video segment retrieval finds the most relevant segments matching the text query, providing users with comprehensive exploration options.
The expr method refines search factors, while different limits apply to text and video searches. A typical search retrieves two text products with metadata and three relevant video segments.
# Configure search parameters search_params = { "metric_type": "COSINE", "params": { "nprobe": 1024, "ef": 64 } } # Search for relevant text embeddings text_results = collection.search( data=[question_embedding], anns_field="vector", param=search_params, limit=2, # Get top 2 text matches expr="embedding_type == 'text'", output_fields=["metadata"] ) # Search for relevant video segments video_results = collection.search( data=[question_embedding], anns_field="vector", param=search_params, limit=3, # Get top 3 video segments expr="embedding_type == 'video'", output_fields=["metadata"] )
# Configure search parameters search_params = { "metric_type": "COSINE", "params": { "nprobe": 1024, "ef": 64 } } # Search for relevant text embeddings text_results = collection.search( data=[question_embedding], anns_field="vector", param=search_params, limit=2, # Get top 2 text matches expr="embedding_type == 'text'", output_fields=["metadata"] ) # Search for relevant video segments video_results = collection.search( data=[question_embedding], anns_field="vector", param=search_params, limit=3, # Get top 3 video segments expr="embedding_type == 'video'", output_fields=["metadata"] )
During result processing, the system extracts metadata from each segment, converts similarity scores to percentages, and organizes product details in a structured dictionary.
# Process text results text_docs = [] for hits in text_results: for hit in hits: metadata = hit.metadata similarity = round((hit.score + 1) * 50, 2) similarity = max(0, min(100, similarity)) text_docs.append({ "title": metadata.get('title', 'Untitled'), "description": metadata.get('description', 'No description available'), "product_id": metadata.get('product_id', ''), "video_url": metadata.get('video_url', ''), "link": metadata.get('link', ''), "similarity": similarity, "raw_score": hit.score, "type": "text" }) # Process video results video_docs = [] for hits in video_results: for hit in hits: metadata = hit.metadata similarity = round((hit.score + 1) * 50, 2) similarity = max(0, min(100, similarity)) video_docs.append({ "title": metadata.get('title', 'Untitled'), "description": metadata.get('description', 'No description available'), "product_id": metadata.get('product_id', ''), "video_url": metadata.get('video_url', ''), "link": metadata.get('link', ''), "similarity": similarity, "raw_score": hit.score, "start_time": metadata.get('start_time', 0), "end_time": metadata.get('end_time', 0), "type": "video" })
# Process text results text_docs = [] for hits in text_results: for hit in hits: metadata = hit.metadata similarity = round((hit.score + 1) * 50, 2) similarity = max(0, min(100, similarity)) text_docs.append({ "title": metadata.get('title', 'Untitled'), "description": metadata.get('description', 'No description available'), "product_id": metadata.get('product_id', ''), "video_url": metadata.get('video_url', ''), "link": metadata.get('link', ''), "similarity": similarity, "raw_score": hit.score, "type": "text" }) # Process video results video_docs = [] for hits in video_results: for hit in hits: metadata = hit.metadata similarity = round((hit.score + 1) * 50, 2) similarity = max(0, min(100, similarity)) video_docs.append({ "title": metadata.get('title', 'Untitled'), "description": metadata.get('description', 'No description available'), "product_id": metadata.get('product_id', ''), "video_url": metadata.get('video_url', ''), "link": metadata.get('link', ''), "similarity": similarity, "raw_score": hit.score, "start_time": metadata.get('start_time', 0), "end_time": metadata.get('end_time', 0), "type": "video" })
After gathering relevant information, the system focuses on retrieval-augmented generation. The retrieved context is structured for efficient LLM processing.
The system defines both System and User Prompts. The System Prompt establishes the fashion assistant context, while the User Prompt combines the user's query with retrieved database context. The system includes error handling for cases where context retrieval fails.
# Handle case when no results found if not text_docs and not video_docs: response_data = { "response": "I couldn't find any matching products. Try describing what you're looking for differently.", "metadata": None } else: # Create context from text results for LLM text_context = "\n\n".join([ f"Product: {doc['title']}\nDescription: {doc['description']}\nLink: {doc['link']}" for doc in text_docs ]) # Prepare messages for OpenAI messages = [ { "role": "system", "content": """You are a professional fashion advisor and AI shopping assistant. Organize your response in the following format: First, provide a brief, direct answer to the user's query Then, describe any relevant products found that match their request, including: - Product name and key features - Why this product matches their needs - Style suggestions for how to wear or use the item Finally, provide any additional style advice or recommendations Keep your response engaging and natural while maintaining this clear structure. Focus on being helpful and specific rather than promotional.""" }, { "role": "user", "content": f"""Query: {question} Available Products: {text_context} Please provide fashion advice and product recommendations based on these options.""" } ] # Get response from OpenAI chat_response = openai_client.chat.completions.create( model="gpt-3.5-turbo", messages=messages, temperature=0.5, max_tokens=500 ) # Format final response response_data = { "response": chat_response.choices[0].message.content, "metadata": { "sources": text_docs + video_docs, "total_sources": len(text_docs) + len(video_docs), "text_sources": len(text_docs), "video_sources": len(video_docs) } }
# Handle case when no results found if not text_docs and not video_docs: response_data = { "response": "I couldn't find any matching products. Try describing what you're looking for differently.", "metadata": None } else: # Create context from text results for LLM text_context = "\n\n".join([ f"Product: {doc['title']}\nDescription: {doc['description']}\nLink: {doc['link']}" for doc in text_docs ]) # Prepare messages for OpenAI messages = [ { "role": "system", "content": """You are a professional fashion advisor and AI shopping assistant. Organize your response in the following format: First, provide a brief, direct answer to the user's query Then, describe any relevant products found that match their request, including: - Product name and key features - Why this product matches their needs - Style suggestions for how to wear or use the item Finally, provide any additional style advice or recommendations Keep your response engaging and natural while maintaining this clear structure. Focus on being helpful and specific rather than promotional.""" }, { "role": "user", "content": f"""Query: {question} Available Products: {text_context} Please provide fashion advice and product recommendations based on these options.""" } ] # Get response from OpenAI chat_response = openai_client.chat.completions.create( model="gpt-3.5-turbo", messages=messages, temperature=0.5, max_tokens=500 ) # Format final response response_data = { "response": chat_response.choices[0].message.content, "metadata": { "sources": text_docs + video_docs, "total_sources": len(text_docs) + len(video_docs), "text_sources": len(text_docs), "video_sources": len(video_docs) } }
The text_context contains the retrieved information. Using gpt-3.5-turbo, the system generates responses with explanations, suggestions, and user guidance as specified in the system prompt. The response is formatted in an accessible dictionary structure. For UI implementation details, see the app.
Demo Application
This demo has three main parts, each with a specific purpose: simplifying database insertion, enabling efficient multimodal retrieval, and improving search functionality for users.
Generation and insertion of text and video embeddings into the database
Retrieval of multimodal data through LLM chat interactions
Product image-based search for finding relevant video segments
The product data catalog includes fields such as product ID, text, description, link, and video URL. Text data is converted into embeddings, while other data is stored as metadata. For video segments, the system processes the video URL. All embeddings are then stored in a single collection.
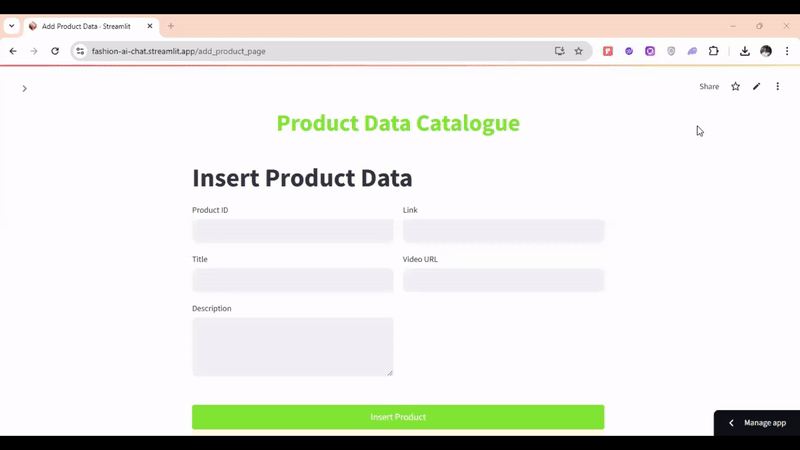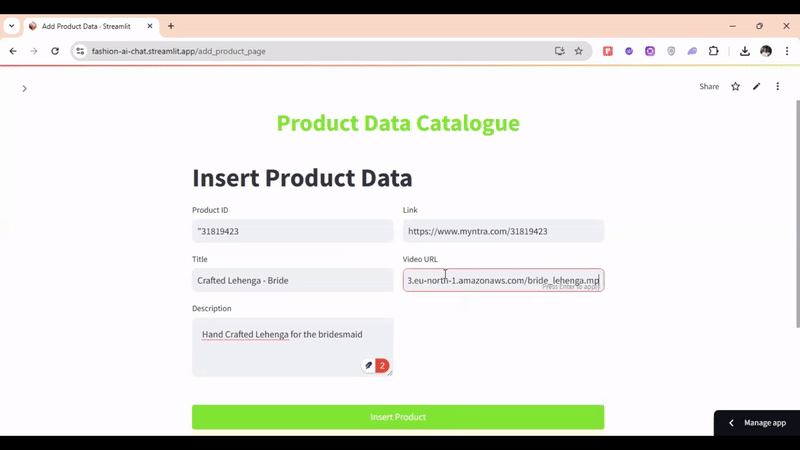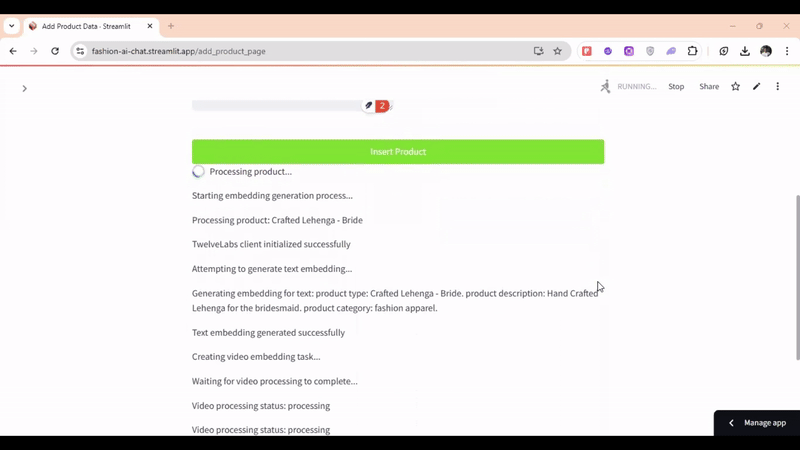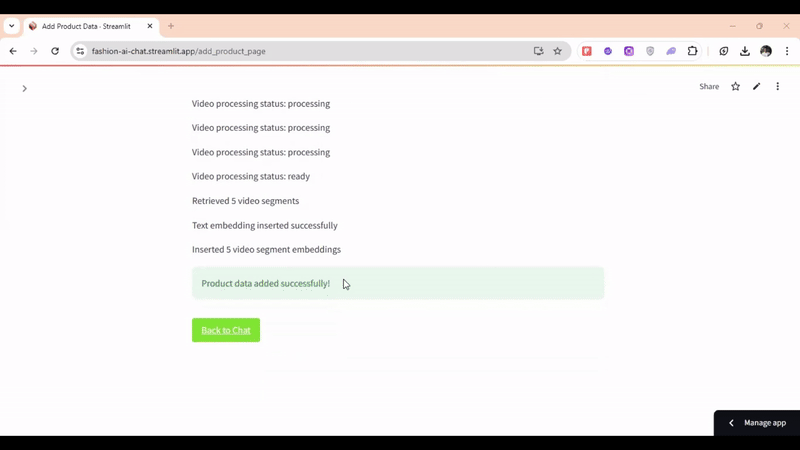
For multimodal retrieval, here's an example query: "I'm looking for a men's black T-shirt"—
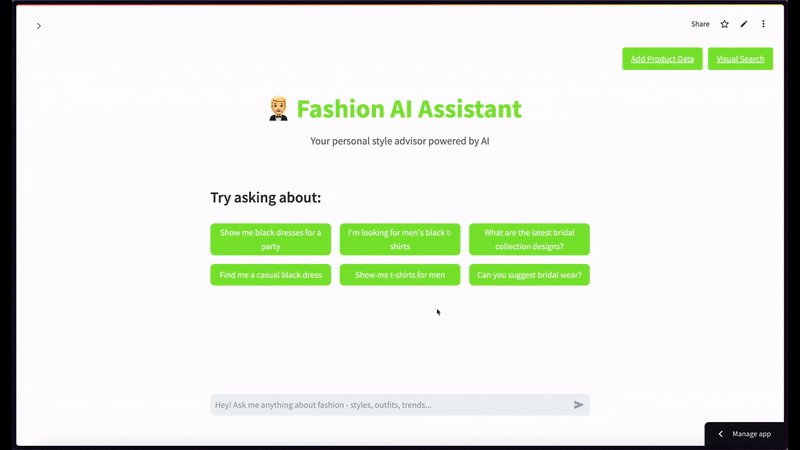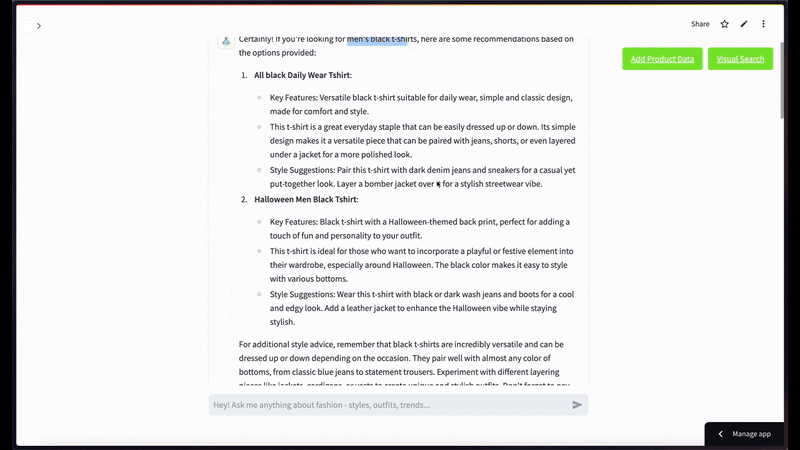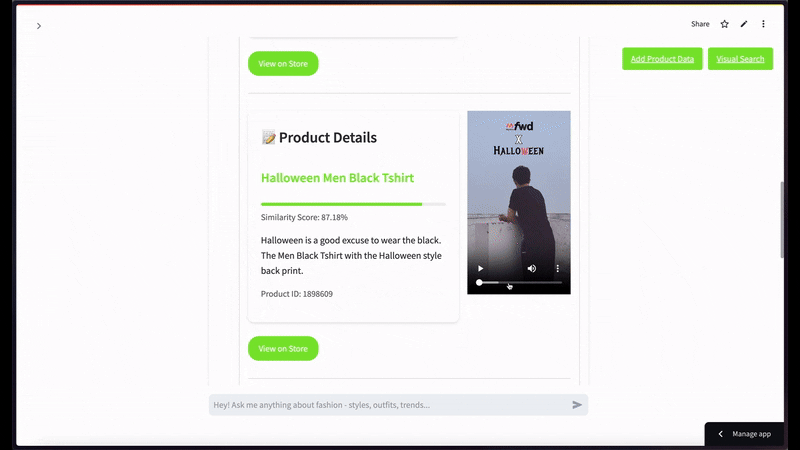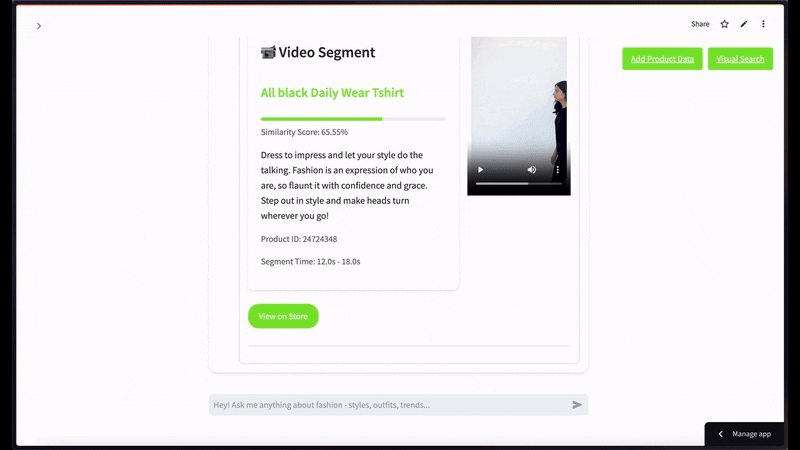
For semantic video search, when using a black t-shirt image as a query with a limit of top 2 results—
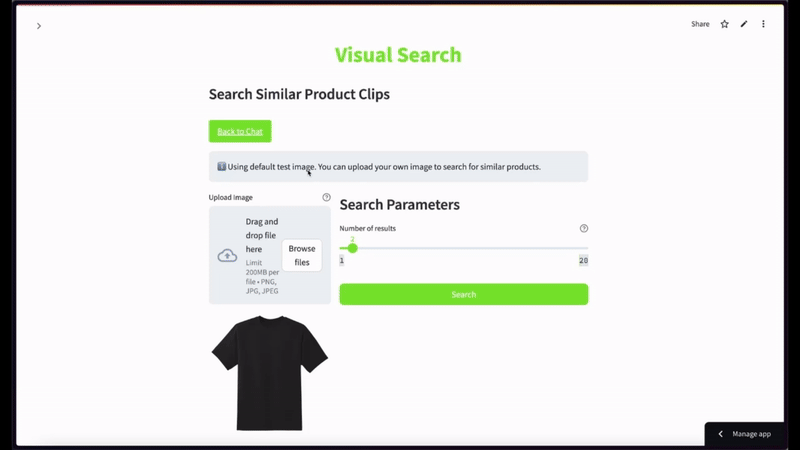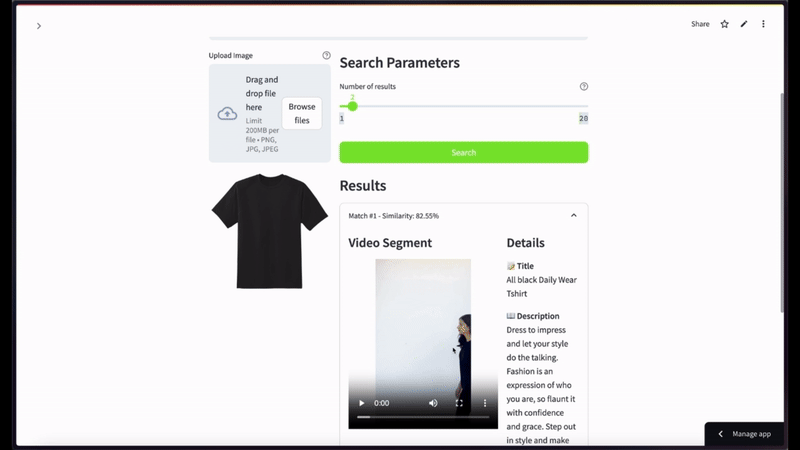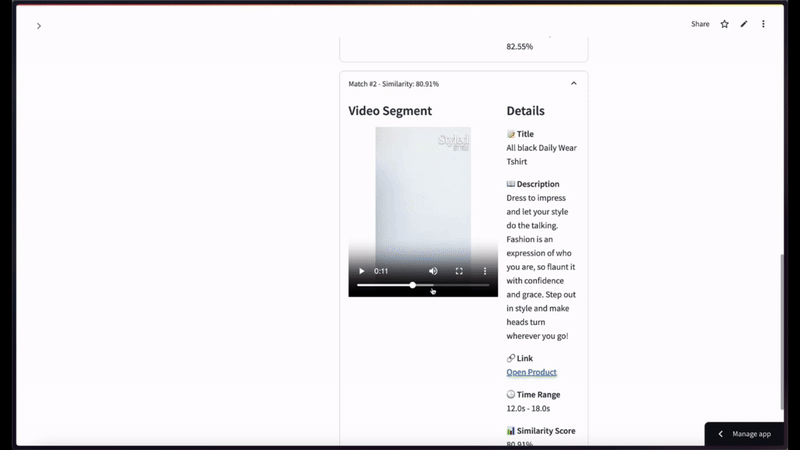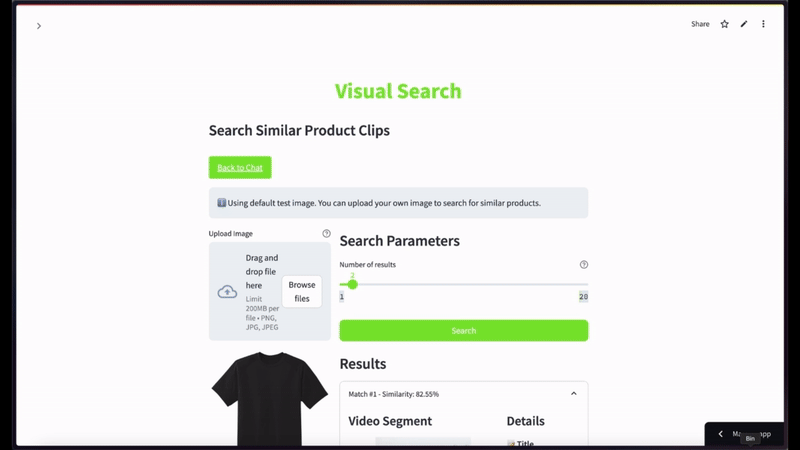
More Ideas to Experiment with the Tutorial
Understanding an application's workings and development process helps you create innovative products that serve users' needs. Here are some potential use cases for video content creators:
🛍️ E-commerce: Enhance product search and recommendations using text and image queries
🎵 Music Discovery: Find similar songs, artists, or genres based on audio clips and user preferences
🎥 Intelligent Video Search Engine: Find videos based on their visual and audio content, helping content creators, journalists, and researchers
🗺️ Personalized Travel Planner: Create travel itineraries based on user preferences, reviews, and destination data
📚Educational Resource Management: Organize and find learning materials—including documents, presentations, and videos—based on content needs
Conclusion
This tutorial demonstrates how multimodal retrieval works through embeddings, powered by Twelve Labs and Milvus vector database. This implementation shows developers how to build scalable applications that handle both visual and textual data. Thanks for following along—we welcome your ideas for improving user experience and solving various challenges.
Additional Resources
Learn more about the embedding generation engine—Marengo-retrieval-2.7. To explore Twelve Labs further and deepen your understanding of video content analysis, check out these resources:
Discord Community: Join our vibrant community of developers and enthusiasts to discuss ideas, ask questions, and share your projects. Join the Twelve Labs Discord
Sample Applications: Explore a variety of sample applications to inspire your next project or learn new implementation techniques
Explore Tutorials: Dive deeper into Twelve Labs capabilities with our comprehensive tutorials
We encourage you to leverage these resources to expand your knowledge and create innovative applications using Twelve Labs video understanding technology.
Introduction
Ever wondered what it would be like to have a personal fashion advisor available 24/7 who understands not just your words but also your visual preferences? Imagine showing a photo of an outfit you like and getting instant AI suggestions for similar styles, or describing your dream look and receiving matching outfit recommendations 👚
Our Fashion AI assistant application is built for next-generation product discovery. This tutorial explores our advanced fashion recommendation system that combines multimodal retrieval with conversational AI. The system uses TwelveLabs Embed - Marengo-retrieval-2.7 model to generate embeddings from both text and video content, enabling seamless search across different data types.
The application uses Milvus as its vector database for efficient similarity search and integrates OpenAI's gpt-3.5 for natural language processing. It handles fashion queries through both text and image inputs, finding relevant product descriptions and precise video timestamps to show users exactly where their desired items appear.
This powerful combination creates a system that understands both textual and visual queries while delivering contextualized responses enriched with multimodal content.
Let's explore how this application works and how you can build similar solutions using the TwelveLabs Python SDK and Milvus Python SDK.
You can explore the demo of the application here: Fashion AI Chat App.
If you want to access the code and experiment with the app directly, you can use this Replit Template.
Prerequisites
Generate an API key by signing up at the Twelve Labs Playground.
Setting up the Milvus Server Installation by following Installation Guide.
Find the repository for this application on Fashion AI Chat Application.
There are several things you should already be familiar with - Python, Streamlit, CSS
Working of the Application
Here's an overview of how the application works and how its components interact:
The application has three main features:
Embedding Generation and Insertion into the Milvus Vector Database
Query Image to Video Segment Retrieval
Chat Retrieval Augmented Generation (RAG) for Multimodal Retrieval (Text and Video Segments)
This tutorial application shows how to store product catalog data in a vector database using Twelve Labs Embed - Marengo-retrieval-2.7. The embeddings for both text and video content are stored in the same Milvus vector database collection. For clarity and reusability, the Twelve Labs embedding function is defined in each utility function.
To make the application work as expected, you must insert the embedding data into the collection, or you can refer to the sample data provided here used in this application.
Preparation Steps
Obtain your API key from the Twelve Labs Playground and set up your environment variable.
Clone the project from Github or use the Replit Template. We recommend using the Replit template since it comes with a predefined virtual environment. Remember to add the secret file and consult the secret key replit docs during setup.
Create a
.envfile containing your Twelve Labs, Milvus Connection, and OpenAI API keys for the LLM model.
For the Milvus vector database, credentials are configured using Zilliz Cloud, though other connection methods are available in the Installation Guide.
TWELVELABS_API_KEY="your_twelvelabs_key" COLLECTION_NAME="your_collection_name" URL="your_milvus_url" TOKEN="your_milvus_token" OPENAI_API_KEY="your_openai_key"
Once you've completed these steps, you're ready to start developing!
Walkthrough for Fashion Chat Application
In this tutorial, we'll create a Streamlit application with a minimal frontend. Let's look at the directory structure:
├── pages/ │ ├── add_product_page.py │ └── visual_search.py ├── .gitignore ├── app.py └── utils.py └── requirements.txt
Creating the Streamlit Application
Now that you've finished the setup, let's build the Streamlit application.
Find all required dependencies for creating your virtual environment here: requirements.txt
Create a virtual Python environment, then set up the environment for the application using the following command:
pip install -r requirements.txt
Defining the Utility function
This section describes the utility.py, which contains the core logic and implementation. Let's examine each subsection:
1 - Setting up the Connection
The first step loads environment variables and establishes connections with OpenAI for LLM access, Milvus for collection management, and Twelve Labs initialization.
# Load environment variables COLLECTION_NAME = os.getenv('COLLECTION_NAME') URL = os.getenv('URL') TOKEN = os.getenv('TOKEN') TWELVELABS_API_KEY = os.getenv('TWELVELABS_API_KEY') # Initialize connections openai_client = OpenAI() connections.connect(uri=URL, token=TOKEN) collection = Collection(COLLECTION_NAME) collection.load() twelvelabs_client = TwelveLabs(api_key=TWELVELABS_API_KEY)
2 - Generation of Embedding with Twelve Labs Embed API
This section covers embedding generation using the Twelve Labs SDK with Marengo-retrieval-2.7 for multimodal retrieval. The solution integrates text and video processing to create efficient search embeddings.
# Generate text and segmented video embeddings for a product def generate_embedding(product_info): try: st.write("Starting embedding generation process...") st.write(f"Processing product: {product_info['title']}") # Initialize the Twelve Labs client twelvelabs_client = TwelveLabs(api_key=TWELVELABS_API_KEY) st.write("TwelveLabs client initialized successfully") st.write("Attempting to generate text embedding...") # Formatting the Text Data of Product Catalogue text = f"product type: {product_info['title']}. " \ f"product description: {product_info['desc']}. " \ f"product category: fashion apparel." st.write(f"Generating embedding for text: {text}") # Generating the Text Embeddings text_embedding = twelvelabs_client.embed.create( model_name="Marengo-retrieval-2.7", text=text ).text_embedding.segments[0].embeddings_float st.write("Text embedding generated successfully") # Create and wait for video embedding task st.write("Creating video embedding task...") video_task = twelvelabs_client.embed.task.create( model_name="Marengo-retrieval-2.7", video_url=product_info['video_url'], video_clip_length=6 ) def on_task_update(task): st.write(f"Video processing status: {task.status}") st.write("Waiting for video processing to complete...") video_task.wait_for_done(sleep_interval=2, callback=on_task_update) # Retrieve segmented video embeddings video_task = video_task.retrieve() if not video_task.video_embedding or not video_task.video_embedding.segments: raise Exception("Failed to retrieve video embeddings") video_segments = video_task.video_embedding.segments st.write(f"Retrieved {len(video_segments)} video segments") video_embeddings = [] for segment in video_segments: video_embeddings.append({ 'embedding': segment.embeddings_float, 'metadata': { 'scope': 'clip', 'start_time': segment.start_offset_sec, 'end_time': segment.end_offset_sec, 'video_url': product_info['video_url'] } }) return { 'text_embedding': text_embedding, 'video_embeddings': video_embeddings }, None except Exception as e: st.error("Error in embedding generation") st.error(f"Error message: {str(e)}") return None, str(e)
The process begins by structuring and formatting text to ensure consistent, meaningful embeddings. Video embedding follows, with status monitoring and progress tracking. Each video segment is set to 6 seconds (video_clip_length=6).
Metadata tracking is essential for maintaining traceability and enabling precise video segment and text searching. The results are then stored in the Milvus vector database collection.
3 - Embedding Insertion into the Milvus Vector Database
Vector databases efficiently store and retrieve high-dimensional embedding data. This section demonstrates how to insert both text and video embeddings into the Milvus vector database with proper metadata management and error handling.
# Insert text and all video segment embeddings into Milvus Collection def insert_embeddings(embeddings_data, product_info): try: metadata = { "product_id": product_info['product_id'], "title": product_info['title'], "description": product_info['desc'], "video_url": product_info['video_url'], "link": product_info['link'] } # Insert text embedding text_entry = { "id": int(uuid.uuid4().int & (1<<63)-1), "vector": embeddings_data['text_embedding'], "metadata": metadata, "embedding_type": "text" } collection.insert([text_entry]) st.write("Text embedding inserted successfully") # Insert each video segment embedding for video_segment in embeddings_data['video_embeddings']: video_entry = { "id": int(uuid.uuid4().int & (1<<63)-1), "vector": video_segment['embedding'], "metadata": {**metadata, **video_segment['metadata']}, "embedding_type": "video" } collection.insert([video_entry]) st.write(f"Inserted {len(embeddings_data['video_embeddings'])} video segment embeddings") return True except Exception as e: st.error(f"Error inserting embeddings: {str(e)}") return False
After defining the id, vector, and metadata, the embedding_type is specified to accommodate different formats in the same collection space. The data is then inserted using the collection.insert method.
4 - Semantic Search Implementation for Image to Video Retrieval
Semantic search with image queries enables finding similar video content. This implementation combines Twelve Labs embedding capabilities with Milvus vector search. Here's how the utility function searched_similar_videos works:
First, the system loads and reads the product image to find video segments containing similar products. Twelve Labs embed then converts the image into an embedding for semantic search against stored video embeddings in the Milvus collection.
# Load and Read Query Image image_path = "path/to/your/image.jpg" with open(image_path, 'rb') as f: image_file = f.read() # Intializing of client and Generation of Image Emebedding twelvelabs_client = TwelveLabs(api_key=TWELVELABS_API_KEY) image_embedding = twelvelabs_client.embed.create( model_name="Marengo-retrieval-2.7", image_file=image_file ).image_embedding.segments[0].embeddings_float
The search uses cosine similarity and cluster parameters to balance speed and accuracy. When collection.search runs with embedding_type == 'video' and other parameters, it retrieves the specified number of product video segments.
search_params = { "metric_type": "COSINE", "params": { "nprobe": 1024, "ef": 64 } } # Search relevant video segments results = collection.search( data=[image_embedding], anns_field="vector", param=search_params, limit=2, expr="embedding_type == 'video'", output_fields=["metadata"] )
The system processes the results, converts similarity scores to percentages for clarity, and organizes the metadata into a structured dictionary.
search_results = [] for hits in results: for hit in hits: metadata = hit.metadata # Convert score from [-1,1] to [0,100] range similarity = round((hit.score + 1) * 50, 2) similarity = max(0, min(100, similarity)) search_results.append({ 'Title': metadata.get('title', ''), 'Description': metadata.get('description', ''), 'Link': metadata.get('link', ''), 'Start Time': f"{metadata.get('start_time', 0):.1f}s", 'End Time': f"{metadata.get('end_time', 0):.1f}s", 'Video URL': metadata.get('video_url', ''), 'Similarity': f"{similarity}%", 'Raw Score': hit.score }) # Sort by similarity score in descending order search_results.sort(key=lambda x: float(x['Similarity'].rstrip('%')), reverse=True)
The sorted results can then be displayed. The UI implementation is available in vision_search.
5 - Developing Retrieval Augmented Generation System
This section focuses on question-answering in the fashion assistant context, combining multimodal retrieval with LLM (gpt-3.5) for contextual responses. It emphasizes multimodal retrieval from text and video data with metadata for effective personalization. The get_rag_response function implements the RAG functionality.
The process begins by converting the user's question and context into a text embedding using the Marengo-retrieval-2.7 engine with Twelve Labs embed, enabling semantic search across the database.
# Sample question question_with_context = f"fashion product: Suggest me black dresses for a party" # Generate embedding for the question question_embedding = twelvelabs_client.embed.create( model_name="Marengo-retrieval-2.7", text=question_with_context ).text_embedding.segments[0].embeddings_float
After setting semantic search parameters, the system performs separate collection searches for text and video segments. Video segment retrieval finds the most relevant segments matching the text query, providing users with comprehensive exploration options.
The expr method refines search factors, while different limits apply to text and video searches. A typical search retrieves two text products with metadata and three relevant video segments.
# Configure search parameters search_params = { "metric_type": "COSINE", "params": { "nprobe": 1024, "ef": 64 } } # Search for relevant text embeddings text_results = collection.search( data=[question_embedding], anns_field="vector", param=search_params, limit=2, # Get top 2 text matches expr="embedding_type == 'text'", output_fields=["metadata"] ) # Search for relevant video segments video_results = collection.search( data=[question_embedding], anns_field="vector", param=search_params, limit=3, # Get top 3 video segments expr="embedding_type == 'video'", output_fields=["metadata"] )
During result processing, the system extracts metadata from each segment, converts similarity scores to percentages, and organizes product details in a structured dictionary.
# Process text results text_docs = [] for hits in text_results: for hit in hits: metadata = hit.metadata similarity = round((hit.score + 1) * 50, 2) similarity = max(0, min(100, similarity)) text_docs.append({ "title": metadata.get('title', 'Untitled'), "description": metadata.get('description', 'No description available'), "product_id": metadata.get('product_id', ''), "video_url": metadata.get('video_url', ''), "link": metadata.get('link', ''), "similarity": similarity, "raw_score": hit.score, "type": "text" }) # Process video results video_docs = [] for hits in video_results: for hit in hits: metadata = hit.metadata similarity = round((hit.score + 1) * 50, 2) similarity = max(0, min(100, similarity)) video_docs.append({ "title": metadata.get('title', 'Untitled'), "description": metadata.get('description', 'No description available'), "product_id": metadata.get('product_id', ''), "video_url": metadata.get('video_url', ''), "link": metadata.get('link', ''), "similarity": similarity, "raw_score": hit.score, "start_time": metadata.get('start_time', 0), "end_time": metadata.get('end_time', 0), "type": "video" })
After gathering relevant information, the system focuses on retrieval-augmented generation. The retrieved context is structured for efficient LLM processing.
The system defines both System and User Prompts. The System Prompt establishes the fashion assistant context, while the User Prompt combines the user's query with retrieved database context. The system includes error handling for cases where context retrieval fails.
# Handle case when no results found if not text_docs and not video_docs: response_data = { "response": "I couldn't find any matching products. Try describing what you're looking for differently.", "metadata": None } else: # Create context from text results for LLM text_context = "\n\n".join([ f"Product: {doc['title']}\nDescription: {doc['description']}\nLink: {doc['link']}" for doc in text_docs ]) # Prepare messages for OpenAI messages = [ { "role": "system", "content": """You are a professional fashion advisor and AI shopping assistant. Organize your response in the following format: First, provide a brief, direct answer to the user's query Then, describe any relevant products found that match their request, including: - Product name and key features - Why this product matches their needs - Style suggestions for how to wear or use the item Finally, provide any additional style advice or recommendations Keep your response engaging and natural while maintaining this clear structure. Focus on being helpful and specific rather than promotional.""" }, { "role": "user", "content": f"""Query: {question} Available Products: {text_context} Please provide fashion advice and product recommendations based on these options.""" } ] # Get response from OpenAI chat_response = openai_client.chat.completions.create( model="gpt-3.5-turbo", messages=messages, temperature=0.5, max_tokens=500 ) # Format final response response_data = { "response": chat_response.choices[0].message.content, "metadata": { "sources": text_docs + video_docs, "total_sources": len(text_docs) + len(video_docs), "text_sources": len(text_docs), "video_sources": len(video_docs) } }
The text_context contains the retrieved information. Using gpt-3.5-turbo, the system generates responses with explanations, suggestions, and user guidance as specified in the system prompt. The response is formatted in an accessible dictionary structure. For UI implementation details, see the app.
Demo Application
This demo has three main parts, each with a specific purpose: simplifying database insertion, enabling efficient multimodal retrieval, and improving search functionality for users.
Generation and insertion of text and video embeddings into the database
Retrieval of multimodal data through LLM chat interactions
Product image-based search for finding relevant video segments
The product data catalog includes fields such as product ID, text, description, link, and video URL. Text data is converted into embeddings, while other data is stored as metadata. For video segments, the system processes the video URL. All embeddings are then stored in a single collection.
For multimodal retrieval, here's an example query: "I'm looking for a men's black T-shirt"—
For semantic video search, when using a black t-shirt image as a query with a limit of top 2 results—
More Ideas to Experiment with the Tutorial
Understanding an application's workings and development process helps you create innovative products that serve users' needs. Here are some potential use cases for video content creators:
🛍️ E-commerce: Enhance product search and recommendations using text and image queries
🎵 Music Discovery: Find similar songs, artists, or genres based on audio clips and user preferences
🎥 Intelligent Video Search Engine: Find videos based on their visual and audio content, helping content creators, journalists, and researchers
🗺️ Personalized Travel Planner: Create travel itineraries based on user preferences, reviews, and destination data
📚Educational Resource Management: Organize and find learning materials—including documents, presentations, and videos—based on content needs
Conclusion
This tutorial demonstrates how multimodal retrieval works through embeddings, powered by Twelve Labs and Milvus vector database. This implementation shows developers how to build scalable applications that handle both visual and textual data. Thanks for following along—we welcome your ideas for improving user experience and solving various challenges.
Additional Resources
Learn more about the embedding generation engine—Marengo-retrieval-2.7. To explore Twelve Labs further and deepen your understanding of video content analysis, check out these resources:
Discord Community: Join our vibrant community of developers and enthusiasts to discuss ideas, ask questions, and share your projects. Join the Twelve Labs Discord
Sample Applications: Explore a variety of sample applications to inspire your next project or learn new implementation techniques
Explore Tutorials: Dive deeper into Twelve Labs capabilities with our comprehensive tutorials
We encourage you to leverage these resources to expand your knowledge and create innovative applications using Twelve Labs video understanding technology.
Introduction
Ever wondered what it would be like to have a personal fashion advisor available 24/7 who understands not just your words but also your visual preferences? Imagine showing a photo of an outfit you like and getting instant AI suggestions for similar styles, or describing your dream look and receiving matching outfit recommendations 👚
Our Fashion AI assistant application is built for next-generation product discovery. This tutorial explores our advanced fashion recommendation system that combines multimodal retrieval with conversational AI. The system uses TwelveLabs Embed - Marengo-retrieval-2.7 model to generate embeddings from both text and video content, enabling seamless search across different data types.
The application uses Milvus as its vector database for efficient similarity search and integrates OpenAI's gpt-3.5 for natural language processing. It handles fashion queries through both text and image inputs, finding relevant product descriptions and precise video timestamps to show users exactly where their desired items appear.
This powerful combination creates a system that understands both textual and visual queries while delivering contextualized responses enriched with multimodal content.
Let's explore how this application works and how you can build similar solutions using the TwelveLabs Python SDK and Milvus Python SDK.
You can explore the demo of the application here: Fashion AI Chat App.
If you want to access the code and experiment with the app directly, you can use this Replit Template.
Prerequisites
Generate an API key by signing up at the Twelve Labs Playground.
Setting up the Milvus Server Installation by following Installation Guide.
Find the repository for this application on Fashion AI Chat Application.
There are several things you should already be familiar with - Python, Streamlit, CSS
Working of the Application
Here's an overview of how the application works and how its components interact:
The application has three main features:
Embedding Generation and Insertion into the Milvus Vector Database
Query Image to Video Segment Retrieval
Chat Retrieval Augmented Generation (RAG) for Multimodal Retrieval (Text and Video Segments)
This tutorial application shows how to store product catalog data in a vector database using Twelve Labs Embed - Marengo-retrieval-2.7. The embeddings for both text and video content are stored in the same Milvus vector database collection. For clarity and reusability, the Twelve Labs embedding function is defined in each utility function.
To make the application work as expected, you must insert the embedding data into the collection, or you can refer to the sample data provided here used in this application.
Preparation Steps
Obtain your API key from the Twelve Labs Playground and set up your environment variable.
Clone the project from Github or use the Replit Template. We recommend using the Replit template since it comes with a predefined virtual environment. Remember to add the secret file and consult the secret key replit docs during setup.
Create a
.envfile containing your Twelve Labs, Milvus Connection, and OpenAI API keys for the LLM model.
For the Milvus vector database, credentials are configured using Zilliz Cloud, though other connection methods are available in the Installation Guide.
TWELVELABS_API_KEY="your_twelvelabs_key" COLLECTION_NAME="your_collection_name" URL="your_milvus_url" TOKEN="your_milvus_token" OPENAI_API_KEY="your_openai_key"
Once you've completed these steps, you're ready to start developing!
Walkthrough for Fashion Chat Application
In this tutorial, we'll create a Streamlit application with a minimal frontend. Let's look at the directory structure:
├── pages/ │ ├── add_product_page.py │ └── visual_search.py ├── .gitignore ├── app.py └── utils.py └── requirements.txt
Creating the Streamlit Application
Now that you've finished the setup, let's build the Streamlit application.
Find all required dependencies for creating your virtual environment here: requirements.txt
Create a virtual Python environment, then set up the environment for the application using the following command:
pip install -r requirements.txt
Defining the Utility function
This section describes the utility.py, which contains the core logic and implementation. Let's examine each subsection:
1 - Setting up the Connection
The first step loads environment variables and establishes connections with OpenAI for LLM access, Milvus for collection management, and Twelve Labs initialization.
# Load environment variables COLLECTION_NAME = os.getenv('COLLECTION_NAME') URL = os.getenv('URL') TOKEN = os.getenv('TOKEN') TWELVELABS_API_KEY = os.getenv('TWELVELABS_API_KEY') # Initialize connections openai_client = OpenAI() connections.connect(uri=URL, token=TOKEN) collection = Collection(COLLECTION_NAME) collection.load() twelvelabs_client = TwelveLabs(api_key=TWELVELABS_API_KEY)
2 - Generation of Embedding with Twelve Labs Embed API
This section covers embedding generation using the Twelve Labs SDK with Marengo-retrieval-2.7 for multimodal retrieval. The solution integrates text and video processing to create efficient search embeddings.
# Generate text and segmented video embeddings for a product def generate_embedding(product_info): try: st.write("Starting embedding generation process...") st.write(f"Processing product: {product_info['title']}") # Initialize the Twelve Labs client twelvelabs_client = TwelveLabs(api_key=TWELVELABS_API_KEY) st.write("TwelveLabs client initialized successfully") st.write("Attempting to generate text embedding...") # Formatting the Text Data of Product Catalogue text = f"product type: {product_info['title']}. " \ f"product description: {product_info['desc']}. " \ f"product category: fashion apparel." st.write(f"Generating embedding for text: {text}") # Generating the Text Embeddings text_embedding = twelvelabs_client.embed.create( model_name="Marengo-retrieval-2.7", text=text ).text_embedding.segments[0].embeddings_float st.write("Text embedding generated successfully") # Create and wait for video embedding task st.write("Creating video embedding task...") video_task = twelvelabs_client.embed.task.create( model_name="Marengo-retrieval-2.7", video_url=product_info['video_url'], video_clip_length=6 ) def on_task_update(task): st.write(f"Video processing status: {task.status}") st.write("Waiting for video processing to complete...") video_task.wait_for_done(sleep_interval=2, callback=on_task_update) # Retrieve segmented video embeddings video_task = video_task.retrieve() if not video_task.video_embedding or not video_task.video_embedding.segments: raise Exception("Failed to retrieve video embeddings") video_segments = video_task.video_embedding.segments st.write(f"Retrieved {len(video_segments)} video segments") video_embeddings = [] for segment in video_segments: video_embeddings.append({ 'embedding': segment.embeddings_float, 'metadata': { 'scope': 'clip', 'start_time': segment.start_offset_sec, 'end_time': segment.end_offset_sec, 'video_url': product_info['video_url'] } }) return { 'text_embedding': text_embedding, 'video_embeddings': video_embeddings }, None except Exception as e: st.error("Error in embedding generation") st.error(f"Error message: {str(e)}") return None, str(e)
The process begins by structuring and formatting text to ensure consistent, meaningful embeddings. Video embedding follows, with status monitoring and progress tracking. Each video segment is set to 6 seconds (video_clip_length=6).
Metadata tracking is essential for maintaining traceability and enabling precise video segment and text searching. The results are then stored in the Milvus vector database collection.
3 - Embedding Insertion into the Milvus Vector Database
Vector databases efficiently store and retrieve high-dimensional embedding data. This section demonstrates how to insert both text and video embeddings into the Milvus vector database with proper metadata management and error handling.
# Insert text and all video segment embeddings into Milvus Collection def insert_embeddings(embeddings_data, product_info): try: metadata = { "product_id": product_info['product_id'], "title": product_info['title'], "description": product_info['desc'], "video_url": product_info['video_url'], "link": product_info['link'] } # Insert text embedding text_entry = { "id": int(uuid.uuid4().int & (1<<63)-1), "vector": embeddings_data['text_embedding'], "metadata": metadata, "embedding_type": "text" } collection.insert([text_entry]) st.write("Text embedding inserted successfully") # Insert each video segment embedding for video_segment in embeddings_data['video_embeddings']: video_entry = { "id": int(uuid.uuid4().int & (1<<63)-1), "vector": video_segment['embedding'], "metadata": {**metadata, **video_segment['metadata']}, "embedding_type": "video" } collection.insert([video_entry]) st.write(f"Inserted {len(embeddings_data['video_embeddings'])} video segment embeddings") return True except Exception as e: st.error(f"Error inserting embeddings: {str(e)}") return False
After defining the id, vector, and metadata, the embedding_type is specified to accommodate different formats in the same collection space. The data is then inserted using the collection.insert method.
4 - Semantic Search Implementation for Image to Video Retrieval
Semantic search with image queries enables finding similar video content. This implementation combines Twelve Labs embedding capabilities with Milvus vector search. Here's how the utility function searched_similar_videos works:
First, the system loads and reads the product image to find video segments containing similar products. Twelve Labs embed then converts the image into an embedding for semantic search against stored video embeddings in the Milvus collection.
# Load and Read Query Image image_path = "path/to/your/image.jpg" with open(image_path, 'rb') as f: image_file = f.read() # Intializing of client and Generation of Image Emebedding twelvelabs_client = TwelveLabs(api_key=TWELVELABS_API_KEY) image_embedding = twelvelabs_client.embed.create( model_name="Marengo-retrieval-2.7", image_file=image_file ).image_embedding.segments[0].embeddings_float
The search uses cosine similarity and cluster parameters to balance speed and accuracy. When collection.search runs with embedding_type == 'video' and other parameters, it retrieves the specified number of product video segments.
search_params = { "metric_type": "COSINE", "params": { "nprobe": 1024, "ef": 64 } } # Search relevant video segments results = collection.search( data=[image_embedding], anns_field="vector", param=search_params, limit=2, expr="embedding_type == 'video'", output_fields=["metadata"] )
The system processes the results, converts similarity scores to percentages for clarity, and organizes the metadata into a structured dictionary.
search_results = [] for hits in results: for hit in hits: metadata = hit.metadata # Convert score from [-1,1] to [0,100] range similarity = round((hit.score + 1) * 50, 2) similarity = max(0, min(100, similarity)) search_results.append({ 'Title': metadata.get('title', ''), 'Description': metadata.get('description', ''), 'Link': metadata.get('link', ''), 'Start Time': f"{metadata.get('start_time', 0):.1f}s", 'End Time': f"{metadata.get('end_time', 0):.1f}s", 'Video URL': metadata.get('video_url', ''), 'Similarity': f"{similarity}%", 'Raw Score': hit.score }) # Sort by similarity score in descending order search_results.sort(key=lambda x: float(x['Similarity'].rstrip('%')), reverse=True)
The sorted results can then be displayed. The UI implementation is available in vision_search.
5 - Developing Retrieval Augmented Generation System
This section focuses on question-answering in the fashion assistant context, combining multimodal retrieval with LLM (gpt-3.5) for contextual responses. It emphasizes multimodal retrieval from text and video data with metadata for effective personalization. The get_rag_response function implements the RAG functionality.
The process begins by converting the user's question and context into a text embedding using the Marengo-retrieval-2.7 engine with Twelve Labs embed, enabling semantic search across the database.
# Sample question question_with_context = f"fashion product: Suggest me black dresses for a party" # Generate embedding for the question question_embedding = twelvelabs_client.embed.create( model_name="Marengo-retrieval-2.7", text=question_with_context ).text_embedding.segments[0].embeddings_float
After setting semantic search parameters, the system performs separate collection searches for text and video segments. Video segment retrieval finds the most relevant segments matching the text query, providing users with comprehensive exploration options.
The expr method refines search factors, while different limits apply to text and video searches. A typical search retrieves two text products with metadata and three relevant video segments.
# Configure search parameters search_params = { "metric_type": "COSINE", "params": { "nprobe": 1024, "ef": 64 } } # Search for relevant text embeddings text_results = collection.search( data=[question_embedding], anns_field="vector", param=search_params, limit=2, # Get top 2 text matches expr="embedding_type == 'text'", output_fields=["metadata"] ) # Search for relevant video segments video_results = collection.search( data=[question_embedding], anns_field="vector", param=search_params, limit=3, # Get top 3 video segments expr="embedding_type == 'video'", output_fields=["metadata"] )
During result processing, the system extracts metadata from each segment, converts similarity scores to percentages, and organizes product details in a structured dictionary.
# Process text results text_docs = [] for hits in text_results: for hit in hits: metadata = hit.metadata similarity = round((hit.score + 1) * 50, 2) similarity = max(0, min(100, similarity)) text_docs.append({ "title": metadata.get('title', 'Untitled'), "description": metadata.get('description', 'No description available'), "product_id": metadata.get('product_id', ''), "video_url": metadata.get('video_url', ''), "link": metadata.get('link', ''), "similarity": similarity, "raw_score": hit.score, "type": "text" }) # Process video results video_docs = [] for hits in video_results: for hit in hits: metadata = hit.metadata similarity = round((hit.score + 1) * 50, 2) similarity = max(0, min(100, similarity)) video_docs.append({ "title": metadata.get('title', 'Untitled'), "description": metadata.get('description', 'No description available'), "product_id": metadata.get('product_id', ''), "video_url": metadata.get('video_url', ''), "link": metadata.get('link', ''), "similarity": similarity, "raw_score": hit.score, "start_time": metadata.get('start_time', 0), "end_time": metadata.get('end_time', 0), "type": "video" })
After gathering relevant information, the system focuses on retrieval-augmented generation. The retrieved context is structured for efficient LLM processing.
The system defines both System and User Prompts. The System Prompt establishes the fashion assistant context, while the User Prompt combines the user's query with retrieved database context. The system includes error handling for cases where context retrieval fails.
# Handle case when no results found if not text_docs and not video_docs: response_data = { "response": "I couldn't find any matching products. Try describing what you're looking for differently.", "metadata": None } else: # Create context from text results for LLM text_context = "\n\n".join([ f"Product: {doc['title']}\nDescription: {doc['description']}\nLink: {doc['link']}" for doc in text_docs ]) # Prepare messages for OpenAI messages = [ { "role": "system", "content": """You are a professional fashion advisor and AI shopping assistant. Organize your response in the following format: First, provide a brief, direct answer to the user's query Then, describe any relevant products found that match their request, including: - Product name and key features - Why this product matches their needs - Style suggestions for how to wear or use the item Finally, provide any additional style advice or recommendations Keep your response engaging and natural while maintaining this clear structure. Focus on being helpful and specific rather than promotional.""" }, { "role": "user", "content": f"""Query: {question} Available Products: {text_context} Please provide fashion advice and product recommendations based on these options.""" } ] # Get response from OpenAI chat_response = openai_client.chat.completions.create( model="gpt-3.5-turbo", messages=messages, temperature=0.5, max_tokens=500 ) # Format final response response_data = { "response": chat_response.choices[0].message.content, "metadata": { "sources": text_docs + video_docs, "total_sources": len(text_docs) + len(video_docs), "text_sources": len(text_docs), "video_sources": len(video_docs) } }
The text_context contains the retrieved information. Using gpt-3.5-turbo, the system generates responses with explanations, suggestions, and user guidance as specified in the system prompt. The response is formatted in an accessible dictionary structure. For UI implementation details, see the app.
Demo Application
This demo has three main parts, each with a specific purpose: simplifying database insertion, enabling efficient multimodal retrieval, and improving search functionality for users.
Generation and insertion of text and video embeddings into the database
Retrieval of multimodal data through LLM chat interactions
Product image-based search for finding relevant video segments
The product data catalog includes fields such as product ID, text, description, link, and video URL. Text data is converted into embeddings, while other data is stored as metadata. For video segments, the system processes the video URL. All embeddings are then stored in a single collection.
For multimodal retrieval, here's an example query: "I'm looking for a men's black T-shirt"—
For semantic video search, when using a black t-shirt image as a query with a limit of top 2 results—
More Ideas to Experiment with the Tutorial
Understanding an application's workings and development process helps you create innovative products that serve users' needs. Here are some potential use cases for video content creators:
🛍️ E-commerce: Enhance product search and recommendations using text and image queries
🎵 Music Discovery: Find similar songs, artists, or genres based on audio clips and user preferences
🎥 Intelligent Video Search Engine: Find videos based on their visual and audio content, helping content creators, journalists, and researchers
🗺️ Personalized Travel Planner: Create travel itineraries based on user preferences, reviews, and destination data
📚Educational Resource Management: Organize and find learning materials—including documents, presentations, and videos—based on content needs
Conclusion
This tutorial demonstrates how multimodal retrieval works through embeddings, powered by Twelve Labs and Milvus vector database. This implementation shows developers how to build scalable applications that handle both visual and textual data. Thanks for following along—we welcome your ideas for improving user experience and solving various challenges.
Additional Resources
Learn more about the embedding generation engine—Marengo-retrieval-2.7. To explore Twelve Labs further and deepen your understanding of video content analysis, check out these resources:
Discord Community: Join our vibrant community of developers and enthusiasts to discuss ideas, ask questions, and share your projects. Join the Twelve Labs Discord
Sample Applications: Explore a variety of sample applications to inspire your next project or learn new implementation techniques
Explore Tutorials: Dive deeper into Twelve Labs capabilities with our comprehensive tutorials
We encourage you to leverage these resources to expand your knowledge and create innovative applications using Twelve Labs video understanding technology.
Related articles








© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved
© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved
© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved