
WHAT OUR PARTNERS ARE SAYING
Multimodal AI and How Video Understanding Will Revolutionize Media

James Le
A beginner guide to video understanding for M&E with MASV and Twelve Labs
A beginner guide to video understanding for M&E with MASV and Twelve Labs

In this article
No headings found on page
Join our newsletter
Join our newsletter
Receive the latest advancements, tutorials, and industry insights in video understanding
Receive the latest advancements, tutorials, and industry insights in video understanding
Search, analyze, and explore your videos with AI.
Apr 22, 2024
10 Min
Copy link to article
This blog post is co-authored with the wonderful team at MASV: Ankit Verma (Product Marketing Manager) and Jim Donnelly (Head of Editorial)!
It’s not hyperbole to say that artificial intelligence (AI) is now everywhere. You can’t turn around these days without seeing a new incarnation of or application for AI. Nowhere is that more true than in the world of video and film production.
From script writing and location scouting in pre-production to object removal and scene stabilization in post, the AI and machine learning (ML) takeover is real. And that’s a good thing: Less time spent on tedious tasks means M&E pros can save money and spend their valuable time on more valuable tasks.
But perhaps one of the most innovative and powerful ways in which the power of AI is revolutionizing the video world is through video understanding.
What is Video Understanding?
Video understanding models analyze, interpret, and comprehend video content, extracting information in such a way that the entire context of the video is understood.

It’s not just about identifying objects frame by frame or parsing the audio components. AI-powered video understanding maps natural language to the actions within a video. To do that it has to perform various video understanding tasks, such as activity recognition and object detection, to grasp the nuance of what's being communicated through this most fluid of media by processing and understanding the visual, audio, and speech elements of a video.
It's also different from large language models (LLMs) such as ChatGPT, which aren't trained to specifically understand video data.
Put simply, AI video understanding models comprehend video just as we do.
It’s a huge challenge, but it’s one that we are eagerly tackling.
Applications of video understanding in M&E
Before diving into the technology behind deep video understanding, let’s explore exactly how video understanding can streamline the work of M&E pros and video content creators.
Video search
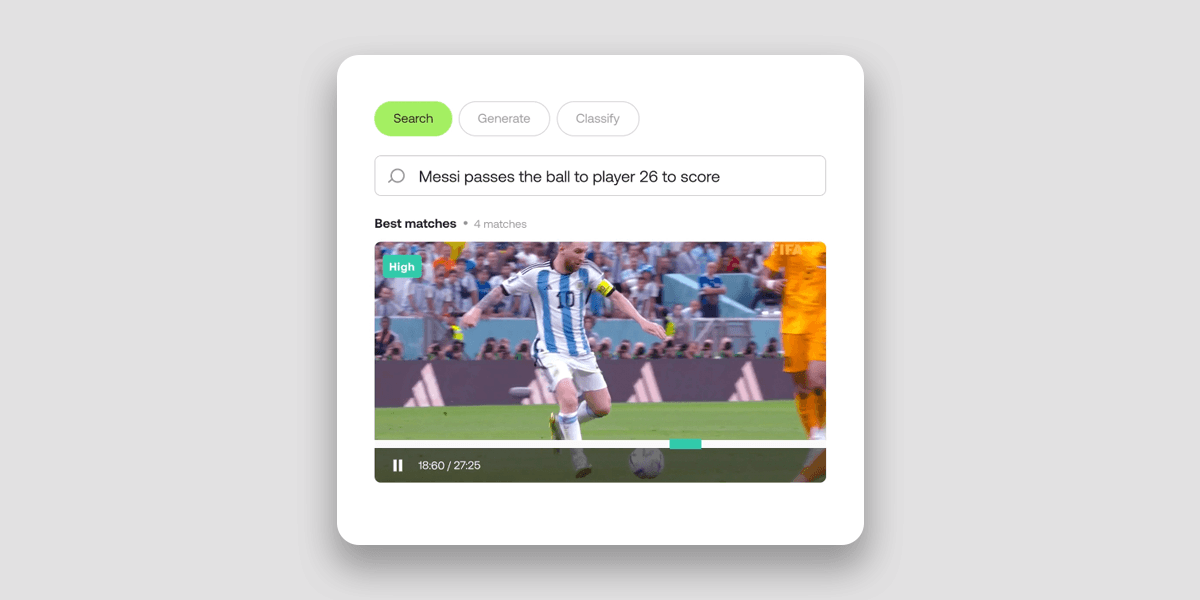
Imagine being able to find a particular video in a vast collection of petabytes of data, simply by describing its visual elements in natural language. Or as a sports league or club, asking your AI video understanding model to assemble a highlight reel of all a player’s goals in just a few seconds.
All these things are possible using AI video understanding.
Traditional video search, on the other hand, has severe limitations in its approach and execution. By relying primarily on keyword matching to index and retrieve videos, they don’t take advantage of multimodal AI techniques that provide a deeper understanding of video through visual and auditory cues.
By simultaneously integrating all available data types—including images, sounds, speech, and on-screen text—modern video understanding models capture the complex relationships among these elements to deliver a more nuanced, humanlike interpretation.
That results in much faster and far more accurate video search and retrieval from cloud object storage. Instead of time-consuming and ineffective manual tagging, video editors can use natural language to quickly and accurately search vast media archives to unearth video moments and hidden gems that otherwise might go unnoticed.
Twelve Labs’ Search API takes around 15 minutes to index an hour of video, making indexed video semantically searchable in more than 100 languages.
Video classification
AI-powered video understanding allows for automatic categorization of video into predefined classes or topics. Using Twelve Labs' Classify API, you can organize videos into sports, news, entertainment, or documentaries by analyzing semantic features, objects, actions, and other elements of the content.
Our model can also classify specific scenes, which can power practical applications around advertising or content moderation. The technology can identify a scene containing a weapon as educational, dramatic, or violent, for example, based on the context.
This benefits creators and video platforms, along with enhancing user experiences by providing more accurate recommendations based on a user’s interests and preferences. It also benefits post-production pros who need to quickly find and log items for editing, archiving or other purposes.
While every video used within Twelve Labs’ technology contains standard metadata, users also have the option of adding custom metadata to their videos to provide more detailed or context-specific information.
From surveillance and security to sports analysis, from content moderation to contextualized advertising, video understanding has the ability to completely upend video classification.
Video description
Video understanding can automatically summarize a video dataset through detailed descriptions generated in seconds. The technology improves comprehension and engagement by condensing long videos into concise representations that capture the most important content.
Such fast, detailed summaries can be a big help when enriching media with descriptive metadata and summaries. Notably among those with physical disabilities or cognitive impairments that make video a less than ideal medium.
In the media and entertainment industry, video description and summarization can be used to create previews or trailers for movies, TV shows, and other video content. These previews provide a concise overview of the content and help viewers decide whether to watch the full video. And anything that improves the user experience is a good thing.
Twelve Labs’ Generate API suite generates texts based on your videos. It offers three distinct endpoints tailored to meet various requirements. Each endpoint has been designed with specific levels of flexibility and customization to accommodate different needs.
The Gist API can produce concise text outputs like titles, topics, and lists of relevant hashtags.
The Summary API is designed to generate video summaries, chapters, and highlights.
For customized outputs, the Generate API allows users to prompt specific formats and styles, from bullet points to reports and even creative lyrics based on the content of the video.
The Technology Behind Video Understanding
“AI can’t understand 80% of the world’s data because it’s locked in video content,” explained Twelve Labs CEO Jae Lee in an interview with MASV. “We build the keys to unlock it.”
Indeed, legacy computer vision (CV) models, which use neural networks and ML to understand digital images, have always had trouble comprehending context within video. CV models are great at identifying objects and behaviors but not the relationship between them. It’s a gap that, until recently, limited our ability to accurately analyze video content using AI.
Travis Couture, founding solutions architect at Twelve Labs, framed the issue as content versus context.
“The traditional approach has been to break video content down into problems that are easier to solve, which would typically mean analyzing frame-by-frame as individual images, and breaking the audio channels out separately and doing transcription on those. Once those two processes are finished, you would bring it all back together and combine your findings.
“When you do that—break down and rebuild—you might have the content but you don’t have the context. And with video, context is king.
“The goal at Twelve Labs is to move away from that traditional computer vision approach and into the video understanding arena, and that means processing video like humans do, which is all together, all at once.”
Multimodal Video Understanding

Video is dynamic, layered, fluid—a combination of elements that, when broken down and separately analyzed, don’t add up to the whole. This is the problem that Twelve Labs has solved. But how did we do it?
By employing multimodal AI.
The term “modality” in this context refers to the way in which an event is experienced. With video, as in the real world, there are multiple modalities: Aural, visual, temporal, language, and others.
“When you analyze those modalities separately and attempt to piece them back together,” explained Twelve Labs co-founder and head of business development Soyoung Lee, “you’ll never achieve holistic understanding and context.”
Twelve Labs’ multimodal approach has allowed it to build a model that replicates the way humans interpret video. “Our Marengo video foundation model feeds perceptual, semantic, and contextual information to Pegasus, our generative model, mimicking the way humans go from perception to processing and logic,” explained .
Just as the human brain constantly receives, interprets, and arranges colossal amounts of information, Twelve Labs’ multimodal AI is all about synthesizing multiple stimuli into coherent understanding. It extracts data from video around variables such as time, objects, speech, text, people, and actions to synthesize the data into vectors, or mathematical representations.
It employs tasks such as action recognition or action detection, pattern recognition, object detection, and scene understanding to make this happen.
Because applications for holistic video understanding are so far reaching in M&E and beyond, Twelve Labs provides a sandbox environment—called the Playground—that allows users to explore and test video understanding technology. We also provide robust documentation and offer a robust API that allows users to embed video understanding capabilities into our platform in just a few API calls.
Enable AI Video Workflows in the Cloud With MASV and Twelve Labs
As of December 2023 approximately 328.77 million terabytes of global data were created every single day, with video responsible for 53.27 percent of that—and rising. It’s this dramatic and ongoing shift towards video that makes Twelve Labs’s video understanding technology so important.
MASV also understands the already-immense and growing potential of video. Their frictionless, fast large file transfer service can ingest huge datasets into popular cloud environments for AI processing, including Amazon S3, using an automated and secure file uploader. This helps simplify content ingest to support AI workflows involving video and other large datasets.
MASV already offers seamless integrations with popular media asset management systems and cloud storage, and no-code file transfer automations for virtually hands-free content ingestion.
Users can configure MASV to automatically upload any transferred files into the user’s S3 instance, and then use Twelve Labs to expedite AI video understanding tasks such as archive/content search or video summarization.
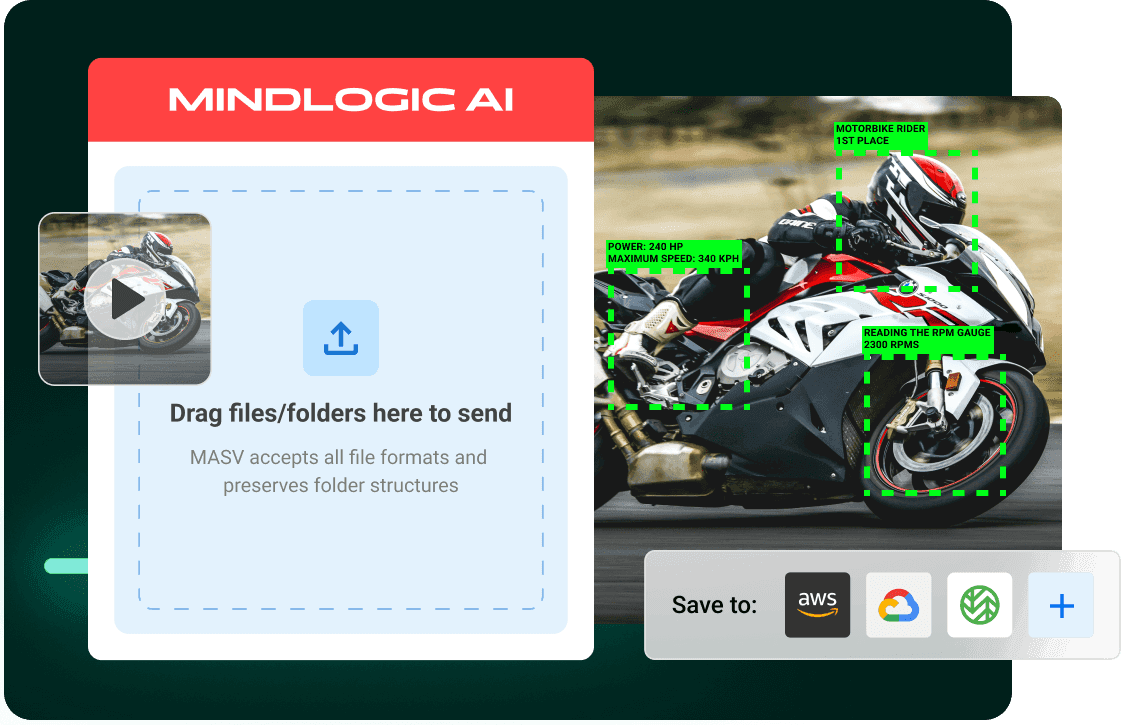
Want to give MASV and Twelve Labs a test drive? Sign up for MASV for free today and get 20GB of free data to try things out—and while you’re at it, sign up for Twelve Labs’ Playground environment and get 10 hours of free video credits to explore what the power of video understanding can do for you.
This blog post is co-authored with the wonderful team at MASV: Ankit Verma (Product Marketing Manager) and Jim Donnelly (Head of Editorial)!
It’s not hyperbole to say that artificial intelligence (AI) is now everywhere. You can’t turn around these days without seeing a new incarnation of or application for AI. Nowhere is that more true than in the world of video and film production.
From script writing and location scouting in pre-production to object removal and scene stabilization in post, the AI and machine learning (ML) takeover is real. And that’s a good thing: Less time spent on tedious tasks means M&E pros can save money and spend their valuable time on more valuable tasks.
But perhaps one of the most innovative and powerful ways in which the power of AI is revolutionizing the video world is through video understanding.
What is Video Understanding?
Video understanding models analyze, interpret, and comprehend video content, extracting information in such a way that the entire context of the video is understood.
It’s not just about identifying objects frame by frame or parsing the audio components. AI-powered video understanding maps natural language to the actions within a video. To do that it has to perform various video understanding tasks, such as activity recognition and object detection, to grasp the nuance of what's being communicated through this most fluid of media by processing and understanding the visual, audio, and speech elements of a video.
It's also different from large language models (LLMs) such as ChatGPT, which aren't trained to specifically understand video data.
Put simply, AI video understanding models comprehend video just as we do.
It’s a huge challenge, but it’s one that we are eagerly tackling.
Applications of video understanding in M&E
Before diving into the technology behind deep video understanding, let’s explore exactly how video understanding can streamline the work of M&E pros and video content creators.
Video search
Imagine being able to find a particular video in a vast collection of petabytes of data, simply by describing its visual elements in natural language. Or as a sports league or club, asking your AI video understanding model to assemble a highlight reel of all a player’s goals in just a few seconds.
All these things are possible using AI video understanding.
Traditional video search, on the other hand, has severe limitations in its approach and execution. By relying primarily on keyword matching to index and retrieve videos, they don’t take advantage of multimodal AI techniques that provide a deeper understanding of video through visual and auditory cues.
By simultaneously integrating all available data types—including images, sounds, speech, and on-screen text—modern video understanding models capture the complex relationships among these elements to deliver a more nuanced, humanlike interpretation.
That results in much faster and far more accurate video search and retrieval from cloud object storage. Instead of time-consuming and ineffective manual tagging, video editors can use natural language to quickly and accurately search vast media archives to unearth video moments and hidden gems that otherwise might go unnoticed.
Twelve Labs’ Search API takes around 15 minutes to index an hour of video, making indexed video semantically searchable in more than 100 languages.
Video classification
AI-powered video understanding allows for automatic categorization of video into predefined classes or topics. Using Twelve Labs' Classify API, you can organize videos into sports, news, entertainment, or documentaries by analyzing semantic features, objects, actions, and other elements of the content.
Our model can also classify specific scenes, which can power practical applications around advertising or content moderation. The technology can identify a scene containing a weapon as educational, dramatic, or violent, for example, based on the context.
This benefits creators and video platforms, along with enhancing user experiences by providing more accurate recommendations based on a user’s interests and preferences. It also benefits post-production pros who need to quickly find and log items for editing, archiving or other purposes.
While every video used within Twelve Labs’ technology contains standard metadata, users also have the option of adding custom metadata to their videos to provide more detailed or context-specific information.
From surveillance and security to sports analysis, from content moderation to contextualized advertising, video understanding has the ability to completely upend video classification.
Video description
Video understanding can automatically summarize a video dataset through detailed descriptions generated in seconds. The technology improves comprehension and engagement by condensing long videos into concise representations that capture the most important content.
Such fast, detailed summaries can be a big help when enriching media with descriptive metadata and summaries. Notably among those with physical disabilities or cognitive impairments that make video a less than ideal medium.
In the media and entertainment industry, video description and summarization can be used to create previews or trailers for movies, TV shows, and other video content. These previews provide a concise overview of the content and help viewers decide whether to watch the full video. And anything that improves the user experience is a good thing.
Twelve Labs’ Generate API suite generates texts based on your videos. It offers three distinct endpoints tailored to meet various requirements. Each endpoint has been designed with specific levels of flexibility and customization to accommodate different needs.
The Gist API can produce concise text outputs like titles, topics, and lists of relevant hashtags.
The Summary API is designed to generate video summaries, chapters, and highlights.
For customized outputs, the Generate API allows users to prompt specific formats and styles, from bullet points to reports and even creative lyrics based on the content of the video.
The Technology Behind Video Understanding
“AI can’t understand 80% of the world’s data because it’s locked in video content,” explained Twelve Labs CEO Jae Lee in an interview with MASV. “We build the keys to unlock it.”
Indeed, legacy computer vision (CV) models, which use neural networks and ML to understand digital images, have always had trouble comprehending context within video. CV models are great at identifying objects and behaviors but not the relationship between them. It’s a gap that, until recently, limited our ability to accurately analyze video content using AI.
Travis Couture, founding solutions architect at Twelve Labs, framed the issue as content versus context.
“The traditional approach has been to break video content down into problems that are easier to solve, which would typically mean analyzing frame-by-frame as individual images, and breaking the audio channels out separately and doing transcription on those. Once those two processes are finished, you would bring it all back together and combine your findings.
“When you do that—break down and rebuild—you might have the content but you don’t have the context. And with video, context is king.
“The goal at Twelve Labs is to move away from that traditional computer vision approach and into the video understanding arena, and that means processing video like humans do, which is all together, all at once.”
Multimodal Video Understanding
Video is dynamic, layered, fluid—a combination of elements that, when broken down and separately analyzed, don’t add up to the whole. This is the problem that Twelve Labs has solved. But how did we do it?
By employing multimodal AI.
The term “modality” in this context refers to the way in which an event is experienced. With video, as in the real world, there are multiple modalities: Aural, visual, temporal, language, and others.
“When you analyze those modalities separately and attempt to piece them back together,” explained Twelve Labs co-founder and head of business development Soyoung Lee, “you’ll never achieve holistic understanding and context.”
Twelve Labs’ multimodal approach has allowed it to build a model that replicates the way humans interpret video. “Our Marengo video foundation model feeds perceptual, semantic, and contextual information to Pegasus, our generative model, mimicking the way humans go from perception to processing and logic,” explained .
Just as the human brain constantly receives, interprets, and arranges colossal amounts of information, Twelve Labs’ multimodal AI is all about synthesizing multiple stimuli into coherent understanding. It extracts data from video around variables such as time, objects, speech, text, people, and actions to synthesize the data into vectors, or mathematical representations.
It employs tasks such as action recognition or action detection, pattern recognition, object detection, and scene understanding to make this happen.
Because applications for holistic video understanding are so far reaching in M&E and beyond, Twelve Labs provides a sandbox environment—called the Playground—that allows users to explore and test video understanding technology. We also provide robust documentation and offer a robust API that allows users to embed video understanding capabilities into our platform in just a few API calls.
Enable AI Video Workflows in the Cloud With MASV and Twelve Labs
As of December 2023 approximately 328.77 million terabytes of global data were created every single day, with video responsible for 53.27 percent of that—and rising. It’s this dramatic and ongoing shift towards video that makes Twelve Labs’s video understanding technology so important.
MASV also understands the already-immense and growing potential of video. Their frictionless, fast large file transfer service can ingest huge datasets into popular cloud environments for AI processing, including Amazon S3, using an automated and secure file uploader. This helps simplify content ingest to support AI workflows involving video and other large datasets.
MASV already offers seamless integrations with popular media asset management systems and cloud storage, and no-code file transfer automations for virtually hands-free content ingestion.
Users can configure MASV to automatically upload any transferred files into the user’s S3 instance, and then use Twelve Labs to expedite AI video understanding tasks such as archive/content search or video summarization.
Want to give MASV and Twelve Labs a test drive? Sign up for MASV for free today and get 20GB of free data to try things out—and while you’re at it, sign up for Twelve Labs’ Playground environment and get 10 hours of free video credits to explore what the power of video understanding can do for you.
This blog post is co-authored with the wonderful team at MASV: Ankit Verma (Product Marketing Manager) and Jim Donnelly (Head of Editorial)!
It’s not hyperbole to say that artificial intelligence (AI) is now everywhere. You can’t turn around these days without seeing a new incarnation of or application for AI. Nowhere is that more true than in the world of video and film production.
From script writing and location scouting in pre-production to object removal and scene stabilization in post, the AI and machine learning (ML) takeover is real. And that’s a good thing: Less time spent on tedious tasks means M&E pros can save money and spend their valuable time on more valuable tasks.
But perhaps one of the most innovative and powerful ways in which the power of AI is revolutionizing the video world is through video understanding.
What is Video Understanding?
Video understanding models analyze, interpret, and comprehend video content, extracting information in such a way that the entire context of the video is understood.
It’s not just about identifying objects frame by frame or parsing the audio components. AI-powered video understanding maps natural language to the actions within a video. To do that it has to perform various video understanding tasks, such as activity recognition and object detection, to grasp the nuance of what's being communicated through this most fluid of media by processing and understanding the visual, audio, and speech elements of a video.
It's also different from large language models (LLMs) such as ChatGPT, which aren't trained to specifically understand video data.
Put simply, AI video understanding models comprehend video just as we do.
It’s a huge challenge, but it’s one that we are eagerly tackling.
Applications of video understanding in M&E
Before diving into the technology behind deep video understanding, let’s explore exactly how video understanding can streamline the work of M&E pros and video content creators.
Video search
Imagine being able to find a particular video in a vast collection of petabytes of data, simply by describing its visual elements in natural language. Or as a sports league or club, asking your AI video understanding model to assemble a highlight reel of all a player’s goals in just a few seconds.
All these things are possible using AI video understanding.
Traditional video search, on the other hand, has severe limitations in its approach and execution. By relying primarily on keyword matching to index and retrieve videos, they don’t take advantage of multimodal AI techniques that provide a deeper understanding of video through visual and auditory cues.
By simultaneously integrating all available data types—including images, sounds, speech, and on-screen text—modern video understanding models capture the complex relationships among these elements to deliver a more nuanced, humanlike interpretation.
That results in much faster and far more accurate video search and retrieval from cloud object storage. Instead of time-consuming and ineffective manual tagging, video editors can use natural language to quickly and accurately search vast media archives to unearth video moments and hidden gems that otherwise might go unnoticed.
Twelve Labs’ Search API takes around 15 minutes to index an hour of video, making indexed video semantically searchable in more than 100 languages.
Video classification
AI-powered video understanding allows for automatic categorization of video into predefined classes or topics. Using Twelve Labs' Classify API, you can organize videos into sports, news, entertainment, or documentaries by analyzing semantic features, objects, actions, and other elements of the content.
Our model can also classify specific scenes, which can power practical applications around advertising or content moderation. The technology can identify a scene containing a weapon as educational, dramatic, or violent, for example, based on the context.
This benefits creators and video platforms, along with enhancing user experiences by providing more accurate recommendations based on a user’s interests and preferences. It also benefits post-production pros who need to quickly find and log items for editing, archiving or other purposes.
While every video used within Twelve Labs’ technology contains standard metadata, users also have the option of adding custom metadata to their videos to provide more detailed or context-specific information.
From surveillance and security to sports analysis, from content moderation to contextualized advertising, video understanding has the ability to completely upend video classification.
Video description
Video understanding can automatically summarize a video dataset through detailed descriptions generated in seconds. The technology improves comprehension and engagement by condensing long videos into concise representations that capture the most important content.
Such fast, detailed summaries can be a big help when enriching media with descriptive metadata and summaries. Notably among those with physical disabilities or cognitive impairments that make video a less than ideal medium.
In the media and entertainment industry, video description and summarization can be used to create previews or trailers for movies, TV shows, and other video content. These previews provide a concise overview of the content and help viewers decide whether to watch the full video. And anything that improves the user experience is a good thing.
Twelve Labs’ Generate API suite generates texts based on your videos. It offers three distinct endpoints tailored to meet various requirements. Each endpoint has been designed with specific levels of flexibility and customization to accommodate different needs.
The Gist API can produce concise text outputs like titles, topics, and lists of relevant hashtags.
The Summary API is designed to generate video summaries, chapters, and highlights.
For customized outputs, the Generate API allows users to prompt specific formats and styles, from bullet points to reports and even creative lyrics based on the content of the video.
The Technology Behind Video Understanding
“AI can’t understand 80% of the world’s data because it’s locked in video content,” explained Twelve Labs CEO Jae Lee in an interview with MASV. “We build the keys to unlock it.”
Indeed, legacy computer vision (CV) models, which use neural networks and ML to understand digital images, have always had trouble comprehending context within video. CV models are great at identifying objects and behaviors but not the relationship between them. It’s a gap that, until recently, limited our ability to accurately analyze video content using AI.
Travis Couture, founding solutions architect at Twelve Labs, framed the issue as content versus context.
“The traditional approach has been to break video content down into problems that are easier to solve, which would typically mean analyzing frame-by-frame as individual images, and breaking the audio channels out separately and doing transcription on those. Once those two processes are finished, you would bring it all back together and combine your findings.
“When you do that—break down and rebuild—you might have the content but you don’t have the context. And with video, context is king.
“The goal at Twelve Labs is to move away from that traditional computer vision approach and into the video understanding arena, and that means processing video like humans do, which is all together, all at once.”
Multimodal Video Understanding
Video is dynamic, layered, fluid—a combination of elements that, when broken down and separately analyzed, don’t add up to the whole. This is the problem that Twelve Labs has solved. But how did we do it?
By employing multimodal AI.
The term “modality” in this context refers to the way in which an event is experienced. With video, as in the real world, there are multiple modalities: Aural, visual, temporal, language, and others.
“When you analyze those modalities separately and attempt to piece them back together,” explained Twelve Labs co-founder and head of business development Soyoung Lee, “you’ll never achieve holistic understanding and context.”
Twelve Labs’ multimodal approach has allowed it to build a model that replicates the way humans interpret video. “Our Marengo video foundation model feeds perceptual, semantic, and contextual information to Pegasus, our generative model, mimicking the way humans go from perception to processing and logic,” explained .
Just as the human brain constantly receives, interprets, and arranges colossal amounts of information, Twelve Labs’ multimodal AI is all about synthesizing multiple stimuli into coherent understanding. It extracts data from video around variables such as time, objects, speech, text, people, and actions to synthesize the data into vectors, or mathematical representations.
It employs tasks such as action recognition or action detection, pattern recognition, object detection, and scene understanding to make this happen.
Because applications for holistic video understanding are so far reaching in M&E and beyond, Twelve Labs provides a sandbox environment—called the Playground—that allows users to explore and test video understanding technology. We also provide robust documentation and offer a robust API that allows users to embed video understanding capabilities into our platform in just a few API calls.
Enable AI Video Workflows in the Cloud With MASV and Twelve Labs
As of December 2023 approximately 328.77 million terabytes of global data were created every single day, with video responsible for 53.27 percent of that—and rising. It’s this dramatic and ongoing shift towards video that makes Twelve Labs’s video understanding technology so important.
MASV also understands the already-immense and growing potential of video. Their frictionless, fast large file transfer service can ingest huge datasets into popular cloud environments for AI processing, including Amazon S3, using an automated and secure file uploader. This helps simplify content ingest to support AI workflows involving video and other large datasets.
MASV already offers seamless integrations with popular media asset management systems and cloud storage, and no-code file transfer automations for virtually hands-free content ingestion.
Users can configure MASV to automatically upload any transferred files into the user’s S3 instance, and then use Twelve Labs to expedite AI video understanding tasks such as archive/content search or video summarization.
Want to give MASV and Twelve Labs a test drive? Sign up for MASV for free today and get 20GB of free data to try things out—and while you’re at it, sign up for Twelve Labs’ Playground environment and get 10 hours of free video credits to explore what the power of video understanding can do for you.
Related articles








© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved
© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved
© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved