WHAT OUR PARTNERS ARE SAYING
Integrating TwelveLabs Embed API with Snowflake Cortex for Multimodal Video Understanding

James Le
The integration of TwelveLabs Embed API with Snowflake Cortex empowers developers to unlock the full potential of video data. By combining advanced multimodal video understanding with Snowflake’s scalable AI Data Cloud, businesses can create innovative applications for search, personalization, moderation, and more. This partnership showcases the synergy between Twelve Labs’ cutting-edge technology and Snowflake’s enterprise-grade infrastructure, driving value for developers and organizations alike.
The integration of TwelveLabs Embed API with Snowflake Cortex empowers developers to unlock the full potential of video data. By combining advanced multimodal video understanding with Snowflake’s scalable AI Data Cloud, businesses can create innovative applications for search, personalization, moderation, and more. This partnership showcases the synergy between Twelve Labs’ cutting-edge technology and Snowflake’s enterprise-grade infrastructure, driving value for developers and organizations alike.

In this article
Join our newsletter
Join our newsletter
Receive the latest advancements, tutorials, and industry insights in video understanding
Receive the latest advancements, tutorials, and industry insights in video understanding
Search, analyze, and explore your videos with AI.
Mar 26, 2025
8 Min
Copy link to article
We'd like to give a huge thanks to Dash Desai from the Snowflake team for creating his Quickstart Guide on AI Video Search with Snowflake and TwelveLabs - which forms the basis for this tutorial!
1 - Introduction
This tutorial demonstrates how to create a powerful video search and summarization workflow using Snowflake Cortex and TwelveLabs Embed API. By combining the advanced capabilities of both products, developers can unlock multimodal video understanding, enabling applications such as semantic search, Retrieval Augmented Generation (RAG), and content recommendations.
Videos stored in cloud storage are processed using TwelveLabs Embed API to generate multimodal embeddings that encapsulate visual, audio, and textual cues. These embeddings are stored in Snowflake tables utilizing the VECTOR datatype, enabling efficient similarity searches with functions like VECTOR_COSINE_SIMILARITY. Text queries are converted into embeddings to retrieve the most relevant video clips. Additional processing includes audio extraction with MoviePy and transcription using OpenAI’s Whisper model. Finally, Snowflake Cortex Complete is leveraged to summarize results, including video details, timestamps, transcripts, and contextual insights.
Why Use Snowflake Container Runtime?
Snowflake Notebooks on Container Runtime provide a flexible environment for advanced machine learning workflows directly within Snowflake. Powered by Snowpark Container Services, this runtime supports Python-based data science tasks with tailored compute resources like GPUs and CPUs. It enables seamless integration of external libraries and tools, making it ideal for operationalizing TwelveLabs Embed API workflows without external infrastructure dependencies.
Why Use TwelveLabs Embed API?
TwelveLabs Embed API allows developers to create state-of-the-art multimodal embeddings for videos. Unlike traditional text-only or image-based models, this API captures spatial-temporal relationships across modalities such as visual expressions, spoken words, and body language. This unified approach ensures accurate video understanding for applications like text-to-video search, anomaly detection, and hybrid RAG workflows.

Key Features of the Workflow
Multimodal Embeddings: Generate embeddings that capture video context across visual, audio, and textual modalities.
Efficient Search: Perform similarity searches using Snowflake's
VECTORdatatype for fast retrieval of relevant video segments.Speech Transcription: Extract audio from matched clips and transcribe them using Whisper for enhanced accessibility.
Summarization: Leverage Snowflake Cortex Complete for summarizing video metadata and transcripts into actionable insights.
By following this tutorial, developers can build scalable AI-powered applications for video understanding while leveraging the robust infrastructure of Snowflake and TwelveLabs.
2 - Prerequisites
Before starting, ensure you have the following: (information in this Quickstart Setup)
Snowflake Account:
Access to a Snowflake account with Container Runtime enabled. This feature allows running Python-based machine learning workflows directly within Snowflake.
Switch your user role to
DASH_CONTAINER_RUNTIME_ROLEin Snowsight.
TwelveLabs API Key:
Sign up for a TwelveLabs account and obtain an API key.
Python Environment:
Familiarity with Snowpark Python and required libraries (
httpx,pydantic,moviepy, etc.).
Sample Video Data:
A list of publicly accessible video URLs for testing. Three sample videos are provided in this guide.
Notebook Setup:
Download the
Gen_AI_Video_Search.ipynbnotebook from the provided GitHub link and import it into your Snowflake account.
Environment Configuration:
Ensure external access integrations and secrets are configured in Snowflake for TwelveLabs API access.
3 - Step-by-Step Guide
Step 1: Install Required Libraries
In the first cell of the notebook, install all necessary Python packages, including TwelveLabs, Whisper, and MoviePy.
!pip install twelvelabs !pip install git+https://github.com/openai/whisper.git ffmpeg-python moviepy !DEBIAN_FRONTEND=noninteractive apt-get install -y ffmpeg
!pip install twelvelabs !pip install git+https://github.com/openai/whisper.git ffmpeg-python moviepy !DEBIAN_FRONTEND=noninteractive apt-get install -y ffmpeg
This ensures that all dependencies are available for embedding generation, audio processing, and transcription tasks.
Step 2: Import Libraries
In the second cell, import the installed libraries into your environment. These include TwelveLabs for embedding generation, Snowpark for interacting with Snowflake, and Streamlit for the frontend application.
from twelvelabs import TwelveLabs from snowflake.snowpark.context import get_active_session import streamlit as st import pandas as pd import snowflake.cortex as cortex session = get_active_session()
from twelvelabs import TwelveLabs from snowflake.snowpark.context import get_active_session import streamlit as st import pandas as pd import snowflake.cortex as cortex session = get_active_session()
This initializes the Snowflake session and sets up the necessary tools for embedding creation and processing.
Step 3: Provide Video URLs
In the third cell, define a list of publicly accessible video URLs to be processed. These videos will serve as input for generating embeddings.
video_urls = ['http://commondatastorage.googleapis.com/gtv-videos-bucket/sample/ForBiggerJoyrides.mp4', 'http://commondatastorage.googleapis.com/gtv-videos-bucket/sample/ForBiggerMeltdowns.mp4', 'https://commondatastorage.googleapis.com/gtv-videos-bucket/sample/WeAreGoingOnBullrun.mp4']
video_urls = ['http://commondatastorage.googleapis.com/gtv-videos-bucket/sample/ForBiggerJoyrides.mp4', 'http://commondatastorage.googleapis.com/gtv-videos-bucket/sample/ForBiggerMeltdowns.mp4', 'https://commondatastorage.googleapis.com/gtv-videos-bucket/sample/WeAreGoingOnBullrun.mp4']
Step 4: Create a Snowpark UDTF for Embedding Generation
Next, we define and register a create_video_embeddings User Defined Table Function (UDTF) in Snowpark to generate embeddings using TwelveLabs Embed API.
Key components of this step include:
Adding the
twelvelabs.zippackage to your environment.Specifying external access integrations and secrets for secure API access.
Defining an output schema with a VECTOR datatype for embeddings.
from snowflake.snowpark.functions import udtf from snowflake.snowpark.types import StructType, StructField, FloatType, StringType, VectorType session.clear_imports() session.add_import('@"DASH_DB"."DASH_SCHEMA"."DASH_PKGS"/twelvelabs.zip') @udtf(name="create_video_embeddings", packages=['httpx','pydantic'], external_access_integrations=['twelvelabs_access_integration'], secrets={'cred': 'twelve_labs_api'}, if_not_exists=True, is_permanent=True, stage_location='@DASH_DB.DASH_SCHEMA.DASH_UDFS', output_schema=StructType([ StructField("embedding", VectorType(float,1024)), StructField("start_offset_sec", FloatType()), StructField("end_offset_sec", FloatType()), StructField("embedding_scope", StringType()) ]) ) class create_video_embeddings: def __init__(self): from twelvelabs import TwelveLabs from twelvelabs.models.embed import EmbeddingsTask import _snowflake twelve_labs_api_key = _snowflake.get_generic_secret_string('cred') twelvelabs_client = TwelveLabs(api_key=twelve_labs_api_key) self.twelvelabs_client = twelvelabs_client def process(self, video_url: str) -> Iterable[Tuple[list, float, float, str]]: # Create an embeddings task task = self.twelvelabs_client.embed.task.create( model_name="Marengo-retrieval-2.7", video_url=video_url ) # Wait for the task to complete status = task.wait_for_done(sleep_interval=60) # Retrieve and process embeddings task = task.retrieve() if task.video_embedding is not None and task.video_embedding.segments is not None: for segment in task.video_embedding.segments: yield ( segment.embeddings_float, # Embedding (list of floats) segment.start_offset_sec, # Start offset in seconds segment.end_offset_sec, # End offset in seconds segment.embedding_scope, # Embedding scope )
from snowflake.snowpark.functions import udtf from snowflake.snowpark.types import StructType, StructField, FloatType, StringType, VectorType session.clear_imports() session.add_import('@"DASH_DB"."DASH_SCHEMA"."DASH_PKGS"/twelvelabs.zip') @udtf(name="create_video_embeddings", packages=['httpx','pydantic'], external_access_integrations=['twelvelabs_access_integration'], secrets={'cred': 'twelve_labs_api'}, if_not_exists=True, is_permanent=True, stage_location='@DASH_DB.DASH_SCHEMA.DASH_UDFS', output_schema=StructType([ StructField("embedding", VectorType(float,1024)), StructField("start_offset_sec", FloatType()), StructField("end_offset_sec", FloatType()), StructField("embedding_scope", StringType()) ]) ) class create_video_embeddings: def __init__(self): from twelvelabs import TwelveLabs from twelvelabs.models.embed import EmbeddingsTask import _snowflake twelve_labs_api_key = _snowflake.get_generic_secret_string('cred') twelvelabs_client = TwelveLabs(api_key=twelve_labs_api_key) self.twelvelabs_client = twelvelabs_client def process(self, video_url: str) -> Iterable[Tuple[list, float, float, str]]: # Create an embeddings task task = self.twelvelabs_client.embed.task.create( model_name="Marengo-retrieval-2.7", video_url=video_url ) # Wait for the task to complete status = task.wait_for_done(sleep_interval=60) # Retrieve and process embeddings task = task.retrieve() if task.video_embedding is not None and task.video_embedding.segments is not None: for segment in task.video_embedding.segments: yield ( segment.embeddings_float, # Embedding (list of floats) segment.start_offset_sec, # Start offset in seconds segment.end_offset_sec, # End offset in seconds segment.embedding_scope, # Embedding scope )
Step 5: Generate Embeddings and Save to Snowflake
Use a Snowpark DataFrame to process the list of video URLs in parallel and save the generated embeddings into a Snowflake table called video_embeddings.
df = session.create_dataframe(video_urls, schema=['url']) df = df.join_table_function(create_video_embeddings(df['url']).over(partition_by="url")) df.write.mode('overwrite').save_as_table('video_embeddings') df = session.table('video_embeddings')
df = session.create_dataframe(video_urls, schema=['url']) df = df.join_table_function(create_video_embeddings(df['url']).over(partition_by="url")) df.write.mode('overwrite').save_as_table('video_embeddings') df = session.table('video_embeddings')
Step 6: Transcribe Video Clips
Download OpenAI’s Whisper model and define helper functions to download videos, extract audio clips, and transcribe them.
import urllib.request import os from moviepy import VideoFileClip import whisper import warnings import logging # Suppress Whisper warnings warnings.filterwarnings("ignore", category=FutureWarning) warnings.filterwarnings("ignore", category=UserWarning) # Set MoviePy logger level to ERROR or CRITICAL to suppress INFO logs logging.getLogger("moviepy").setLevel(logging.ERROR) # Load the Whisper model once whisper_model = whisper.load_model("base") # or any other model you want to use, e.g., 'small', 'medium', 'large' def download_video(video_url, output_video_path, status): try: # status.caption("Downloading video file...") urllib.request.urlretrieve(video_url, output_video_path) # status.caption(f"Video downloaded to {output_video_path}.") return output_video_path except Exception as e: status.caption(f"An error occurred during video download: {e}") return None def extract_audio_from_video(video_path, output_audio_path, status, start_time=None, end_time=None): try: # status.caption("Extracting audio from video...") video_clip = VideoFileClip(video_path) # If start and end times are provided, trim the video if start_time is not None or end_time is not None: video_clip = video_clip.subclipped(start_time, end_time) video_clip.audio.write_audiofile(output_audio_path) # status.caption(f"Audio extracted to {output_audio_path}.") return output_audio_path except Exception as e: status.caption(f"An error occurred during audio extraction: {e}") return None def transcribe_with_whisper(audio_path, status): try: # status.caption("Transcribing audio with Whisper...") result = whisper_model.transcribe(audio_path) # status.caption("Transcription complete.") return result["text"] except Exception as e: status.caption(f"An error occurred during transcription: {e}") return None def transcribe_video(video_url, status, temp_video_path="temp_video.mp4", temp_audio_path="temp_audio.mp3"): try: # Step 1: Download video video_path = download_video(video_url, temp_video_path, status) if not video_path: return None # Step 2: Extract audio from video audio_path = extract_audio_from_video(video_path, temp_audio_path, status) if not audio_path: return None # Step 3: Transcribe audio with Whisper transcription = transcribe_with_whisper(audio_path, status) return transcription finally: # Clean up temporary files if os.path.exists(temp_video_path): os.remove(temp_video_path) # status.caption("Temporary video file removed.") if os.path.exists(temp_audio_path): os.remove(temp_audio_path) # status.caption("Temporary audio file removed.") def transcribe_video_clip(video_url, status, start_time, end_time, temp_video_path="temp_video.mp4", temp_audio_path="temp_audio_clip.mp3"): try: # Step 1: Download video video_path = download_video(video_url, temp_video_path, status) if not video_path: return None # Step 2: Extract audio from the specified clip audio_path = extract_audio_from_video(video_path, temp_audio_path, status, start_time, end_time) if not audio_path: return None # Step 3: Transcribe the extracted audio clip with Whisper transcription = transcribe_with_whisper(audio_path, status) return transcription finally: # Clean up temporary files if os.path.exists(temp_video_path): os.remove(temp_video_path) # status.caption("Temporary video file removed.") if os.path.exists(temp_audio_path): os.remove(temp_audio_path) # status.caption("Temporary audio file removed.")
import urllib.request import os from moviepy import VideoFileClip import whisper import warnings import logging # Suppress Whisper warnings warnings.filterwarnings("ignore", category=FutureWarning) warnings.filterwarnings("ignore", category=UserWarning) # Set MoviePy logger level to ERROR or CRITICAL to suppress INFO logs logging.getLogger("moviepy").setLevel(logging.ERROR) # Load the Whisper model once whisper_model = whisper.load_model("base") # or any other model you want to use, e.g., 'small', 'medium', 'large' def download_video(video_url, output_video_path, status): try: # status.caption("Downloading video file...") urllib.request.urlretrieve(video_url, output_video_path) # status.caption(f"Video downloaded to {output_video_path}.") return output_video_path except Exception as e: status.caption(f"An error occurred during video download: {e}") return None def extract_audio_from_video(video_path, output_audio_path, status, start_time=None, end_time=None): try: # status.caption("Extracting audio from video...") video_clip = VideoFileClip(video_path) # If start and end times are provided, trim the video if start_time is not None or end_time is not None: video_clip = video_clip.subclipped(start_time, end_time) video_clip.audio.write_audiofile(output_audio_path) # status.caption(f"Audio extracted to {output_audio_path}.") return output_audio_path except Exception as e: status.caption(f"An error occurred during audio extraction: {e}") return None def transcribe_with_whisper(audio_path, status): try: # status.caption("Transcribing audio with Whisper...") result = whisper_model.transcribe(audio_path) # status.caption("Transcription complete.") return result["text"] except Exception as e: status.caption(f"An error occurred during transcription: {e}") return None def transcribe_video(video_url, status, temp_video_path="temp_video.mp4", temp_audio_path="temp_audio.mp3"): try: # Step 1: Download video video_path = download_video(video_url, temp_video_path, status) if not video_path: return None # Step 2: Extract audio from video audio_path = extract_audio_from_video(video_path, temp_audio_path, status) if not audio_path: return None # Step 3: Transcribe audio with Whisper transcription = transcribe_with_whisper(audio_path, status) return transcription finally: # Clean up temporary files if os.path.exists(temp_video_path): os.remove(temp_video_path) # status.caption("Temporary video file removed.") if os.path.exists(temp_audio_path): os.remove(temp_audio_path) # status.caption("Temporary audio file removed.") def transcribe_video_clip(video_url, status, start_time, end_time, temp_video_path="temp_video.mp4", temp_audio_path="temp_audio_clip.mp3"): try: # Step 1: Download video video_path = download_video(video_url, temp_video_path, status) if not video_path: return None # Step 2: Extract audio from the specified clip audio_path = extract_audio_from_video(video_path, temp_audio_path, status, start_time, end_time) if not audio_path: return None # Step 3: Transcribe the extracted audio clip with Whisper transcription = transcribe_with_whisper(audio_path, status) return transcription finally: # Clean up temporary files if os.path.exists(temp_video_path): os.remove(temp_video_path) # status.caption("Temporary video file removed.") if os.path.exists(temp_audio_path): os.remove(temp_audio_path) # status.caption("Temporary audio file removed.")
These functions will be used later to process video clips retrieved during similarity searches.
Step 7: Define Similarity Search Function
Create a similarity_scores function to calculate similarity scores between text queries and stored video embeddings using VECTOR_COSINE_SIMILARITY in Snowflake.
# TODO: Replace tlk_XXXXXXXXXXXXXXXXXX with your Twelve Labs API Key TWELVE_LABS_API_KEY ="tlk_XXXXXXXXXXXXXXXXXX" # Initialize the Twelve Labs client twelvelabs_client = TwelveLabs(api_key=TWELVE_LABS_API_KEY) def truncate_text(text, max_tokens=77): # Truncate text to roughly 77 tokens (assuming ~6 chars per token on average) return text[:max_tokens * 6] # Adjust based on actual tokenization behavior def similarity_scores(search_text,results_limit=5): # Twelve Labs Embed API supports text-to-embedding truncated_text = truncate_text(search_text, max_tokens=77) twelvelabs_response = twelvelabs_client.embed.create( model_name="Marengo-retrieval-2.7", text=truncated_text, text_truncate='start' ) if twelvelabs_response.text_embedding is not None and twelvelabs_response.text_embedding.segments is not None: text_query_embeddings = twelvelabs_response.text_embedding.segments[0].embeddings_float return session.sql(f""" SELECT URL as VIDEO_URL,START_OFFSET_SEC,END_OFFSET_SEC, round(VECTOR_COSINE_SIMILARITY(embedding::VECTOR(FLOAT, 1024),{text_query_embeddings}::VECTOR(FLOAT, 1024)),2) as SIMILARITY_SCORE from video_embeddings order by similarity_score desc limit {results_limit}""") else: return twelvelabs_response
# TODO: Replace tlk_XXXXXXXXXXXXXXXXXX with your Twelve Labs API Key TWELVE_LABS_API_KEY ="tlk_XXXXXXXXXXXXXXXXXX" # Initialize the Twelve Labs client twelvelabs_client = TwelveLabs(api_key=TWELVE_LABS_API_KEY) def truncate_text(text, max_tokens=77): # Truncate text to roughly 77 tokens (assuming ~6 chars per token on average) return text[:max_tokens * 6] # Adjust based on actual tokenization behavior def similarity_scores(search_text,results_limit=5): # Twelve Labs Embed API supports text-to-embedding truncated_text = truncate_text(search_text, max_tokens=77) twelvelabs_response = twelvelabs_client.embed.create( model_name="Marengo-retrieval-2.7", text=truncated_text, text_truncate='start' ) if twelvelabs_response.text_embedding is not None and twelvelabs_response.text_embedding.segments is not None: text_query_embeddings = twelvelabs_response.text_embedding.segments[0].embeddings_float return session.sql(f""" SELECT URL as VIDEO_URL,START_OFFSET_SEC,END_OFFSET_SEC, round(VECTOR_COSINE_SIMILARITY(embedding::VECTOR(FLOAT, 1024),{text_query_embeddings}::VECTOR(FLOAT, 1024)),2) as SIMILARITY_SCORE from video_embeddings order by similarity_score desc limit {results_limit}""") else: return twelvelabs_response
Step 8: Build Streamlit Application
Develop an interactive Streamlit app that:
Accepts user input (search text, max results).
Retrieves matching video clips using
similarity_scores.Transcribes each clip using Whisper.
Summarizes results with Snowflake Cortex Complete.
st.subheader("Search Clips Application") with st.container(): with st.expander("Enter search text and select max results", expanded=True): left_col,mid_col,right_col = st.columns(3) with left_col: entered_text = st.text_input('Search Text') with mid_col: max_results = st.selectbox('Max Results',(1,2,3,4,5)) with right_col: selected_llm = st.selectbox('Select Summary LLM',('llama3.2-3b','llama3.1-405b','mistral-large2', 'snowflake-arctic',)) with st.container(): _,mid_col1,_ = st.columns([.3,.4,.2]) with mid_col1: similarity_scores_btn = st.button('Search and Summarize Matching Video Clips',type="primary") with st.container(): if similarity_scores_btn: if entered_text: with st.status("In progress...") as status: df = similarity_scores(entered_text,max_results).to_pandas() status.subheader(f"Top {max_results} clip(s) for search query '{entered_text}'") for row in df.itertuples(): transcribed_clip = transcribe_video_clip(row.VIDEO_URL, status, row.START_OFFSET_SEC, row.END_OFFSET_SEC) prompt = f""" [INST] Summarize the following and include name of the video as well as start and end clip times in seconds with everything in natural language as opposed to attributes: ### Video URL: {row.VIDEO_URL}, Clip Start: {row.START_OFFSET_SEC} | Clip End: {row.END_OFFSET_SEC} | Similarity Score: {row.SIMILARITY_SCORE} Clip Transcript: {transcribed_clip} ### [/INST] """ status.write(f"Video URL: {row.VIDEO_URL}") status.caption(f"-- Clip Start: {row.START_OFFSET_SEC} | Clip End: {row.END_OFFSET_SEC} | Similarity Score: {row.SIMILARITY_SCORE}") status.caption(f"-- Clip Transcript: {transcribed_clip}") status.write(f"Summary: {cortex.Complete(selected_llm,prompt)}") status.divider() status.update(label="Done!", state="complete", expanded=True) else: st.caption("User ERROR: Please enter search text!")
st.subheader("Search Clips Application") with st.container(): with st.expander("Enter search text and select max results", expanded=True): left_col,mid_col,right_col = st.columns(3) with left_col: entered_text = st.text_input('Search Text') with mid_col: max_results = st.selectbox('Max Results',(1,2,3,4,5)) with right_col: selected_llm = st.selectbox('Select Summary LLM',('llama3.2-3b','llama3.1-405b','mistral-large2', 'snowflake-arctic',)) with st.container(): _,mid_col1,_ = st.columns([.3,.4,.2]) with mid_col1: similarity_scores_btn = st.button('Search and Summarize Matching Video Clips',type="primary") with st.container(): if similarity_scores_btn: if entered_text: with st.status("In progress...") as status: df = similarity_scores(entered_text,max_results).to_pandas() status.subheader(f"Top {max_results} clip(s) for search query '{entered_text}'") for row in df.itertuples(): transcribed_clip = transcribe_video_clip(row.VIDEO_URL, status, row.START_OFFSET_SEC, row.END_OFFSET_SEC) prompt = f""" [INST] Summarize the following and include name of the video as well as start and end clip times in seconds with everything in natural language as opposed to attributes: ### Video URL: {row.VIDEO_URL}, Clip Start: {row.START_OFFSET_SEC} | Clip End: {row.END_OFFSET_SEC} | Similarity Score: {row.SIMILARITY_SCORE} Clip Transcript: {transcribed_clip} ### [/INST] """ status.write(f"Video URL: {row.VIDEO_URL}") status.caption(f"-- Clip Start: {row.START_OFFSET_SEC} | Clip End: {row.END_OFFSET_SEC} | Similarity Score: {row.SIMILARITY_SCORE}") status.caption(f"-- Clip Transcript: {transcribed_clip}") status.write(f"Summary: {cortex.Complete(selected_llm,prompt)}") status.divider() status.update(label="Done!", state="complete", expanded=True) else: st.caption("User ERROR: Please enter search text!")
Search Examples
For example queries like "Welcome home, Buster," the app displays:
Video URL.
Clip start/end times.
Similarity score.
Transcription.
Summary generated by Cortex Complete.
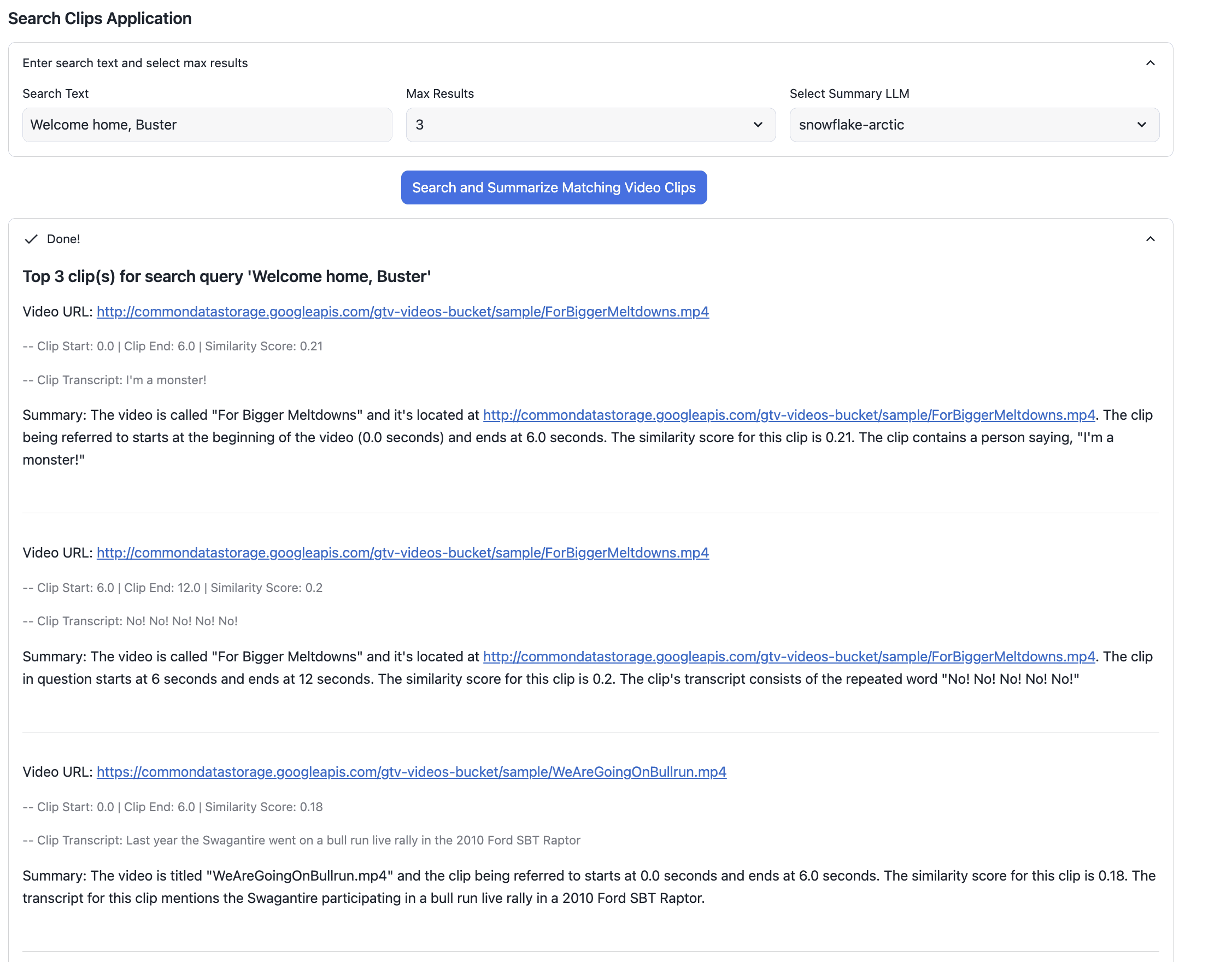
The top result shown above is from this video. You can see clearly that “Welcome home, Buster” is highlighted in the white banner.

Let’s try another search query “A white car and a black car” and see the app display.
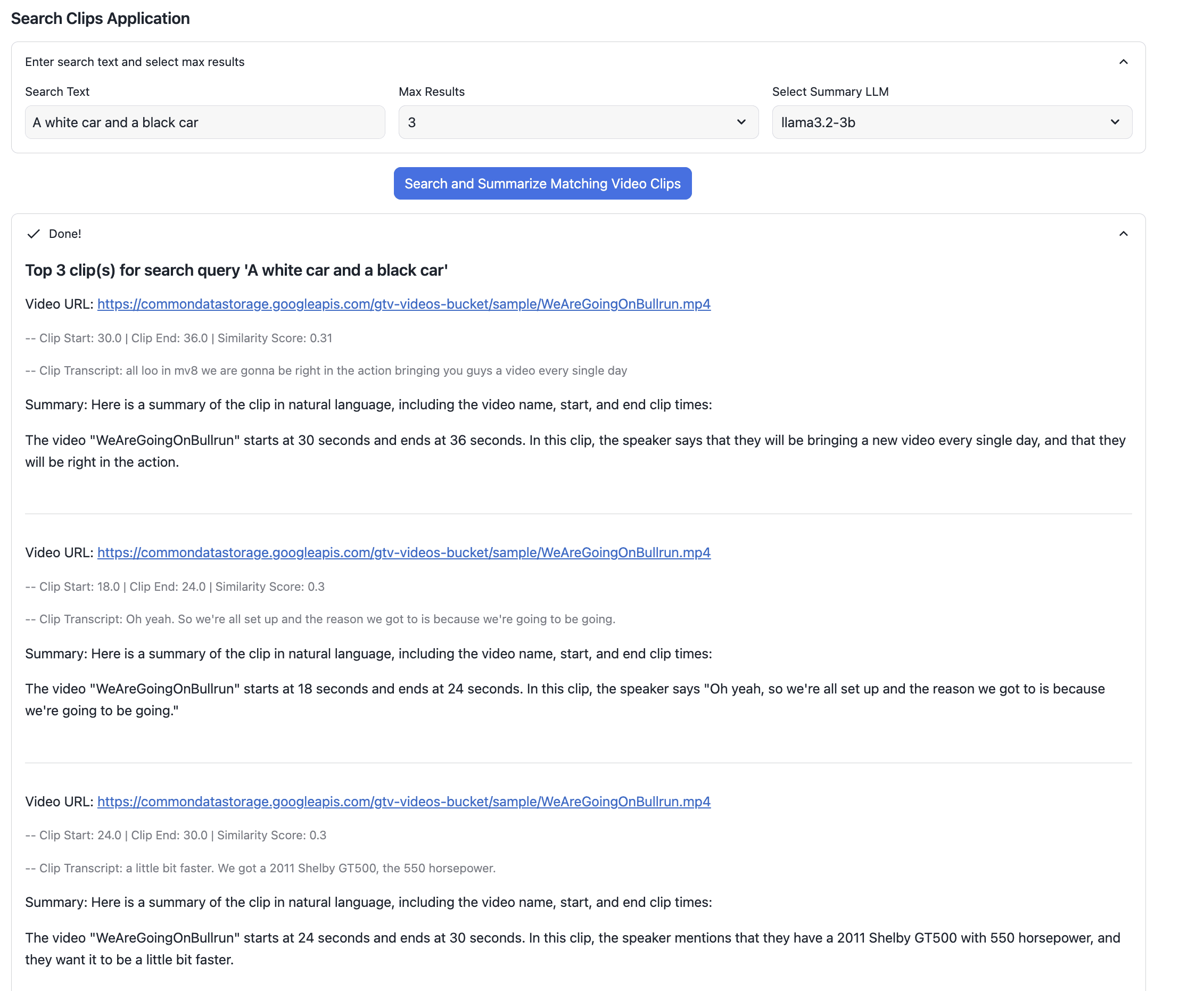
The top result shown above is from this video. You can see clearly that there are a white car and a black car in the frame.

4 - Use Cases and Benefits
The workflow above enables developers to build innovative video applications:
Contextual Personalized Ads: Combine TwelveLabs' multimodal embeddings with Snowflake's user data to deliver relevant, brand-safe video advertisements. This deep understanding of video context helps align ads with user preferences while maintaining safety standards.
Video Search Engines: Create sophisticated search applications that match natural language queries with video embeddings for precise results.
Content Moderation: Screen video libraries for inappropriate or sensitive content by analyzing visual, audio, and textual elements.
Recommendation Systems: Boost user engagement through video recommendations based on contextual understanding and viewing patterns.
Training Data Curation: Select diverse and representative samples for multimodal video datasets through video embedding analysis.
The integration of TwelveLabs with Snowflake offers significant business value through enhanced video understanding capabilities. TwelveLabs' multimodal embeddings provide comprehensive analysis of video content by capturing visuals, audio, and text in context. The integration leverages Snowflake's Container Runtime to create a scalable, native environment that significantly reduces operational complexity. Additionally, the ability to store and process embeddings using Snowflake's VECTOR datatype enables efficient similarity searches and downstream AI applications.
From a developer perspective, the integration streamlines productivity by providing simplified workflows through Snowpark Python UDTFs for parallel video processing. Developers can also implement real-time semantic search and leverage Snowflake Cortex Complete for advanced summarization tasks.
Finally, the solution delivers exceptional performance and reliability by combining TwelveLabs' state-of-the-art video-native models for low-latency embedding generation with Snowflake's robust infrastructure, ensuring secure and high-throughput processing capabilities.
5 - Conclusion
The integration of TwelveLabs Embed API with Snowflake Cortex empowers developers to unlock the full potential of video data. By combining advanced multimodal video understanding with Snowflake’s scalable AI Data Cloud, businesses can create innovative applications for search, personalization, moderation, and more. This partnership showcases the synergy between TwelveLabs’ cutting-edge technology and Snowflake’s enterprise-grade infrastructure, driving value for developers and organizations alike.
Call to Action
Ready to transform your video data into actionable intelligence?
Try the Integration: Sign up for the TwelveLabs Embed API Open Beta and start building your own AI-powered video applications in Snowflake today.
Explore More Use Cases: Visit the Snowflake QuickStart Guide to learn how to implement similar workflows tailored to your business needs.
Join the Conversation: Share your feedback on this integration in the TwelveLabs Discord and Snowflake developer community forum.
We'd like to give a huge thanks to Dash Desai from the Snowflake team for creating his Quickstart Guide on AI Video Search with Snowflake and TwelveLabs - which forms the basis for this tutorial!
1 - Introduction
This tutorial demonstrates how to create a powerful video search and summarization workflow using Snowflake Cortex and TwelveLabs Embed API. By combining the advanced capabilities of both products, developers can unlock multimodal video understanding, enabling applications such as semantic search, Retrieval Augmented Generation (RAG), and content recommendations.
Videos stored in cloud storage are processed using TwelveLabs Embed API to generate multimodal embeddings that encapsulate visual, audio, and textual cues. These embeddings are stored in Snowflake tables utilizing the VECTOR datatype, enabling efficient similarity searches with functions like VECTOR_COSINE_SIMILARITY. Text queries are converted into embeddings to retrieve the most relevant video clips. Additional processing includes audio extraction with MoviePy and transcription using OpenAI’s Whisper model. Finally, Snowflake Cortex Complete is leveraged to summarize results, including video details, timestamps, transcripts, and contextual insights.
Why Use Snowflake Container Runtime?
Snowflake Notebooks on Container Runtime provide a flexible environment for advanced machine learning workflows directly within Snowflake. Powered by Snowpark Container Services, this runtime supports Python-based data science tasks with tailored compute resources like GPUs and CPUs. It enables seamless integration of external libraries and tools, making it ideal for operationalizing TwelveLabs Embed API workflows without external infrastructure dependencies.
Why Use TwelveLabs Embed API?
TwelveLabs Embed API allows developers to create state-of-the-art multimodal embeddings for videos. Unlike traditional text-only or image-based models, this API captures spatial-temporal relationships across modalities such as visual expressions, spoken words, and body language. This unified approach ensures accurate video understanding for applications like text-to-video search, anomaly detection, and hybrid RAG workflows.
Key Features of the Workflow
Multimodal Embeddings: Generate embeddings that capture video context across visual, audio, and textual modalities.
Efficient Search: Perform similarity searches using Snowflake's
VECTORdatatype for fast retrieval of relevant video segments.Speech Transcription: Extract audio from matched clips and transcribe them using Whisper for enhanced accessibility.
Summarization: Leverage Snowflake Cortex Complete for summarizing video metadata and transcripts into actionable insights.
By following this tutorial, developers can build scalable AI-powered applications for video understanding while leveraging the robust infrastructure of Snowflake and TwelveLabs.
2 - Prerequisites
Before starting, ensure you have the following: (information in this Quickstart Setup)
Snowflake Account:
Access to a Snowflake account with Container Runtime enabled. This feature allows running Python-based machine learning workflows directly within Snowflake.
Switch your user role to
DASH_CONTAINER_RUNTIME_ROLEin Snowsight.
TwelveLabs API Key:
Sign up for a TwelveLabs account and obtain an API key.
Python Environment:
Familiarity with Snowpark Python and required libraries (
httpx,pydantic,moviepy, etc.).
Sample Video Data:
A list of publicly accessible video URLs for testing. Three sample videos are provided in this guide.
Notebook Setup:
Download the
Gen_AI_Video_Search.ipynbnotebook from the provided GitHub link and import it into your Snowflake account.
Environment Configuration:
Ensure external access integrations and secrets are configured in Snowflake for TwelveLabs API access.
3 - Step-by-Step Guide
Step 1: Install Required Libraries
In the first cell of the notebook, install all necessary Python packages, including TwelveLabs, Whisper, and MoviePy.
!pip install twelvelabs !pip install git+https://github.com/openai/whisper.git ffmpeg-python moviepy !DEBIAN_FRONTEND=noninteractive apt-get install -y ffmpeg
This ensures that all dependencies are available for embedding generation, audio processing, and transcription tasks.
Step 2: Import Libraries
In the second cell, import the installed libraries into your environment. These include TwelveLabs for embedding generation, Snowpark for interacting with Snowflake, and Streamlit for the frontend application.
from twelvelabs import TwelveLabs from snowflake.snowpark.context import get_active_session import streamlit as st import pandas as pd import snowflake.cortex as cortex session = get_active_session()
This initializes the Snowflake session and sets up the necessary tools for embedding creation and processing.
Step 3: Provide Video URLs
In the third cell, define a list of publicly accessible video URLs to be processed. These videos will serve as input for generating embeddings.
video_urls = ['http://commondatastorage.googleapis.com/gtv-videos-bucket/sample/ForBiggerJoyrides.mp4', 'http://commondatastorage.googleapis.com/gtv-videos-bucket/sample/ForBiggerMeltdowns.mp4', 'https://commondatastorage.googleapis.com/gtv-videos-bucket/sample/WeAreGoingOnBullrun.mp4']
Step 4: Create a Snowpark UDTF for Embedding Generation
Next, we define and register a create_video_embeddings User Defined Table Function (UDTF) in Snowpark to generate embeddings using TwelveLabs Embed API.
Key components of this step include:
Adding the
twelvelabs.zippackage to your environment.Specifying external access integrations and secrets for secure API access.
Defining an output schema with a VECTOR datatype for embeddings.
from snowflake.snowpark.functions import udtf from snowflake.snowpark.types import StructType, StructField, FloatType, StringType, VectorType session.clear_imports() session.add_import('@"DASH_DB"."DASH_SCHEMA"."DASH_PKGS"/twelvelabs.zip') @udtf(name="create_video_embeddings", packages=['httpx','pydantic'], external_access_integrations=['twelvelabs_access_integration'], secrets={'cred': 'twelve_labs_api'}, if_not_exists=True, is_permanent=True, stage_location='@DASH_DB.DASH_SCHEMA.DASH_UDFS', output_schema=StructType([ StructField("embedding", VectorType(float,1024)), StructField("start_offset_sec", FloatType()), StructField("end_offset_sec", FloatType()), StructField("embedding_scope", StringType()) ]) ) class create_video_embeddings: def __init__(self): from twelvelabs import TwelveLabs from twelvelabs.models.embed import EmbeddingsTask import _snowflake twelve_labs_api_key = _snowflake.get_generic_secret_string('cred') twelvelabs_client = TwelveLabs(api_key=twelve_labs_api_key) self.twelvelabs_client = twelvelabs_client def process(self, video_url: str) -> Iterable[Tuple[list, float, float, str]]: # Create an embeddings task task = self.twelvelabs_client.embed.task.create( model_name="Marengo-retrieval-2.7", video_url=video_url ) # Wait for the task to complete status = task.wait_for_done(sleep_interval=60) # Retrieve and process embeddings task = task.retrieve() if task.video_embedding is not None and task.video_embedding.segments is not None: for segment in task.video_embedding.segments: yield ( segment.embeddings_float, # Embedding (list of floats) segment.start_offset_sec, # Start offset in seconds segment.end_offset_sec, # End offset in seconds segment.embedding_scope, # Embedding scope )
Step 5: Generate Embeddings and Save to Snowflake
Use a Snowpark DataFrame to process the list of video URLs in parallel and save the generated embeddings into a Snowflake table called video_embeddings.
df = session.create_dataframe(video_urls, schema=['url']) df = df.join_table_function(create_video_embeddings(df['url']).over(partition_by="url")) df.write.mode('overwrite').save_as_table('video_embeddings') df = session.table('video_embeddings')
Step 6: Transcribe Video Clips
Download OpenAI’s Whisper model and define helper functions to download videos, extract audio clips, and transcribe them.
import urllib.request import os from moviepy import VideoFileClip import whisper import warnings import logging # Suppress Whisper warnings warnings.filterwarnings("ignore", category=FutureWarning) warnings.filterwarnings("ignore", category=UserWarning) # Set MoviePy logger level to ERROR or CRITICAL to suppress INFO logs logging.getLogger("moviepy").setLevel(logging.ERROR) # Load the Whisper model once whisper_model = whisper.load_model("base") # or any other model you want to use, e.g., 'small', 'medium', 'large' def download_video(video_url, output_video_path, status): try: # status.caption("Downloading video file...") urllib.request.urlretrieve(video_url, output_video_path) # status.caption(f"Video downloaded to {output_video_path}.") return output_video_path except Exception as e: status.caption(f"An error occurred during video download: {e}") return None def extract_audio_from_video(video_path, output_audio_path, status, start_time=None, end_time=None): try: # status.caption("Extracting audio from video...") video_clip = VideoFileClip(video_path) # If start and end times are provided, trim the video if start_time is not None or end_time is not None: video_clip = video_clip.subclipped(start_time, end_time) video_clip.audio.write_audiofile(output_audio_path) # status.caption(f"Audio extracted to {output_audio_path}.") return output_audio_path except Exception as e: status.caption(f"An error occurred during audio extraction: {e}") return None def transcribe_with_whisper(audio_path, status): try: # status.caption("Transcribing audio with Whisper...") result = whisper_model.transcribe(audio_path) # status.caption("Transcription complete.") return result["text"] except Exception as e: status.caption(f"An error occurred during transcription: {e}") return None def transcribe_video(video_url, status, temp_video_path="temp_video.mp4", temp_audio_path="temp_audio.mp3"): try: # Step 1: Download video video_path = download_video(video_url, temp_video_path, status) if not video_path: return None # Step 2: Extract audio from video audio_path = extract_audio_from_video(video_path, temp_audio_path, status) if not audio_path: return None # Step 3: Transcribe audio with Whisper transcription = transcribe_with_whisper(audio_path, status) return transcription finally: # Clean up temporary files if os.path.exists(temp_video_path): os.remove(temp_video_path) # status.caption("Temporary video file removed.") if os.path.exists(temp_audio_path): os.remove(temp_audio_path) # status.caption("Temporary audio file removed.") def transcribe_video_clip(video_url, status, start_time, end_time, temp_video_path="temp_video.mp4", temp_audio_path="temp_audio_clip.mp3"): try: # Step 1: Download video video_path = download_video(video_url, temp_video_path, status) if not video_path: return None # Step 2: Extract audio from the specified clip audio_path = extract_audio_from_video(video_path, temp_audio_path, status, start_time, end_time) if not audio_path: return None # Step 3: Transcribe the extracted audio clip with Whisper transcription = transcribe_with_whisper(audio_path, status) return transcription finally: # Clean up temporary files if os.path.exists(temp_video_path): os.remove(temp_video_path) # status.caption("Temporary video file removed.") if os.path.exists(temp_audio_path): os.remove(temp_audio_path) # status.caption("Temporary audio file removed.")
These functions will be used later to process video clips retrieved during similarity searches.
Step 7: Define Similarity Search Function
Create a similarity_scores function to calculate similarity scores between text queries and stored video embeddings using VECTOR_COSINE_SIMILARITY in Snowflake.
# TODO: Replace tlk_XXXXXXXXXXXXXXXXXX with your Twelve Labs API Key TWELVE_LABS_API_KEY ="tlk_XXXXXXXXXXXXXXXXXX" # Initialize the Twelve Labs client twelvelabs_client = TwelveLabs(api_key=TWELVE_LABS_API_KEY) def truncate_text(text, max_tokens=77): # Truncate text to roughly 77 tokens (assuming ~6 chars per token on average) return text[:max_tokens * 6] # Adjust based on actual tokenization behavior def similarity_scores(search_text,results_limit=5): # Twelve Labs Embed API supports text-to-embedding truncated_text = truncate_text(search_text, max_tokens=77) twelvelabs_response = twelvelabs_client.embed.create( model_name="Marengo-retrieval-2.7", text=truncated_text, text_truncate='start' ) if twelvelabs_response.text_embedding is not None and twelvelabs_response.text_embedding.segments is not None: text_query_embeddings = twelvelabs_response.text_embedding.segments[0].embeddings_float return session.sql(f""" SELECT URL as VIDEO_URL,START_OFFSET_SEC,END_OFFSET_SEC, round(VECTOR_COSINE_SIMILARITY(embedding::VECTOR(FLOAT, 1024),{text_query_embeddings}::VECTOR(FLOAT, 1024)),2) as SIMILARITY_SCORE from video_embeddings order by similarity_score desc limit {results_limit}""") else: return twelvelabs_response
Step 8: Build Streamlit Application
Develop an interactive Streamlit app that:
Accepts user input (search text, max results).
Retrieves matching video clips using
similarity_scores.Transcribes each clip using Whisper.
Summarizes results with Snowflake Cortex Complete.
st.subheader("Search Clips Application") with st.container(): with st.expander("Enter search text and select max results", expanded=True): left_col,mid_col,right_col = st.columns(3) with left_col: entered_text = st.text_input('Search Text') with mid_col: max_results = st.selectbox('Max Results',(1,2,3,4,5)) with right_col: selected_llm = st.selectbox('Select Summary LLM',('llama3.2-3b','llama3.1-405b','mistral-large2', 'snowflake-arctic',)) with st.container(): _,mid_col1,_ = st.columns([.3,.4,.2]) with mid_col1: similarity_scores_btn = st.button('Search and Summarize Matching Video Clips',type="primary") with st.container(): if similarity_scores_btn: if entered_text: with st.status("In progress...") as status: df = similarity_scores(entered_text,max_results).to_pandas() status.subheader(f"Top {max_results} clip(s) for search query '{entered_text}'") for row in df.itertuples(): transcribed_clip = transcribe_video_clip(row.VIDEO_URL, status, row.START_OFFSET_SEC, row.END_OFFSET_SEC) prompt = f""" [INST] Summarize the following and include name of the video as well as start and end clip times in seconds with everything in natural language as opposed to attributes: ### Video URL: {row.VIDEO_URL}, Clip Start: {row.START_OFFSET_SEC} | Clip End: {row.END_OFFSET_SEC} | Similarity Score: {row.SIMILARITY_SCORE} Clip Transcript: {transcribed_clip} ### [/INST] """ status.write(f"Video URL: {row.VIDEO_URL}") status.caption(f"-- Clip Start: {row.START_OFFSET_SEC} | Clip End: {row.END_OFFSET_SEC} | Similarity Score: {row.SIMILARITY_SCORE}") status.caption(f"-- Clip Transcript: {transcribed_clip}") status.write(f"Summary: {cortex.Complete(selected_llm,prompt)}") status.divider() status.update(label="Done!", state="complete", expanded=True) else: st.caption("User ERROR: Please enter search text!")
Search Examples
For example queries like "Welcome home, Buster," the app displays:
Video URL.
Clip start/end times.
Similarity score.
Transcription.
Summary generated by Cortex Complete.
The top result shown above is from this video. You can see clearly that “Welcome home, Buster” is highlighted in the white banner.
Let’s try another search query “A white car and a black car” and see the app display.
The top result shown above is from this video. You can see clearly that there are a white car and a black car in the frame.
4 - Use Cases and Benefits
The workflow above enables developers to build innovative video applications:
Contextual Personalized Ads: Combine TwelveLabs' multimodal embeddings with Snowflake's user data to deliver relevant, brand-safe video advertisements. This deep understanding of video context helps align ads with user preferences while maintaining safety standards.
Video Search Engines: Create sophisticated search applications that match natural language queries with video embeddings for precise results.
Content Moderation: Screen video libraries for inappropriate or sensitive content by analyzing visual, audio, and textual elements.
Recommendation Systems: Boost user engagement through video recommendations based on contextual understanding and viewing patterns.
Training Data Curation: Select diverse and representative samples for multimodal video datasets through video embedding analysis.
The integration of TwelveLabs with Snowflake offers significant business value through enhanced video understanding capabilities. TwelveLabs' multimodal embeddings provide comprehensive analysis of video content by capturing visuals, audio, and text in context. The integration leverages Snowflake's Container Runtime to create a scalable, native environment that significantly reduces operational complexity. Additionally, the ability to store and process embeddings using Snowflake's VECTOR datatype enables efficient similarity searches and downstream AI applications.
From a developer perspective, the integration streamlines productivity by providing simplified workflows through Snowpark Python UDTFs for parallel video processing. Developers can also implement real-time semantic search and leverage Snowflake Cortex Complete for advanced summarization tasks.
Finally, the solution delivers exceptional performance and reliability by combining TwelveLabs' state-of-the-art video-native models for low-latency embedding generation with Snowflake's robust infrastructure, ensuring secure and high-throughput processing capabilities.
5 - Conclusion
The integration of TwelveLabs Embed API with Snowflake Cortex empowers developers to unlock the full potential of video data. By combining advanced multimodal video understanding with Snowflake’s scalable AI Data Cloud, businesses can create innovative applications for search, personalization, moderation, and more. This partnership showcases the synergy between TwelveLabs’ cutting-edge technology and Snowflake’s enterprise-grade infrastructure, driving value for developers and organizations alike.
Call to Action
Ready to transform your video data into actionable intelligence?
Try the Integration: Sign up for the TwelveLabs Embed API Open Beta and start building your own AI-powered video applications in Snowflake today.
Explore More Use Cases: Visit the Snowflake QuickStart Guide to learn how to implement similar workflows tailored to your business needs.
Join the Conversation: Share your feedback on this integration in the TwelveLabs Discord and Snowflake developer community forum.
We'd like to give a huge thanks to Dash Desai from the Snowflake team for creating his Quickstart Guide on AI Video Search with Snowflake and TwelveLabs - which forms the basis for this tutorial!
1 - Introduction
This tutorial demonstrates how to create a powerful video search and summarization workflow using Snowflake Cortex and TwelveLabs Embed API. By combining the advanced capabilities of both products, developers can unlock multimodal video understanding, enabling applications such as semantic search, Retrieval Augmented Generation (RAG), and content recommendations.
Videos stored in cloud storage are processed using TwelveLabs Embed API to generate multimodal embeddings that encapsulate visual, audio, and textual cues. These embeddings are stored in Snowflake tables utilizing the VECTOR datatype, enabling efficient similarity searches with functions like VECTOR_COSINE_SIMILARITY. Text queries are converted into embeddings to retrieve the most relevant video clips. Additional processing includes audio extraction with MoviePy and transcription using OpenAI’s Whisper model. Finally, Snowflake Cortex Complete is leveraged to summarize results, including video details, timestamps, transcripts, and contextual insights.
Why Use Snowflake Container Runtime?
Snowflake Notebooks on Container Runtime provide a flexible environment for advanced machine learning workflows directly within Snowflake. Powered by Snowpark Container Services, this runtime supports Python-based data science tasks with tailored compute resources like GPUs and CPUs. It enables seamless integration of external libraries and tools, making it ideal for operationalizing TwelveLabs Embed API workflows without external infrastructure dependencies.
Why Use TwelveLabs Embed API?
TwelveLabs Embed API allows developers to create state-of-the-art multimodal embeddings for videos. Unlike traditional text-only or image-based models, this API captures spatial-temporal relationships across modalities such as visual expressions, spoken words, and body language. This unified approach ensures accurate video understanding for applications like text-to-video search, anomaly detection, and hybrid RAG workflows.
Key Features of the Workflow
Multimodal Embeddings: Generate embeddings that capture video context across visual, audio, and textual modalities.
Efficient Search: Perform similarity searches using Snowflake's
VECTORdatatype for fast retrieval of relevant video segments.Speech Transcription: Extract audio from matched clips and transcribe them using Whisper for enhanced accessibility.
Summarization: Leverage Snowflake Cortex Complete for summarizing video metadata and transcripts into actionable insights.
By following this tutorial, developers can build scalable AI-powered applications for video understanding while leveraging the robust infrastructure of Snowflake and TwelveLabs.
2 - Prerequisites
Before starting, ensure you have the following: (information in this Quickstart Setup)
Snowflake Account:
Access to a Snowflake account with Container Runtime enabled. This feature allows running Python-based machine learning workflows directly within Snowflake.
Switch your user role to
DASH_CONTAINER_RUNTIME_ROLEin Snowsight.
TwelveLabs API Key:
Sign up for a TwelveLabs account and obtain an API key.
Python Environment:
Familiarity with Snowpark Python and required libraries (
httpx,pydantic,moviepy, etc.).
Sample Video Data:
A list of publicly accessible video URLs for testing. Three sample videos are provided in this guide.
Notebook Setup:
Download the
Gen_AI_Video_Search.ipynbnotebook from the provided GitHub link and import it into your Snowflake account.
Environment Configuration:
Ensure external access integrations and secrets are configured in Snowflake for TwelveLabs API access.
3 - Step-by-Step Guide
Step 1: Install Required Libraries
In the first cell of the notebook, install all necessary Python packages, including TwelveLabs, Whisper, and MoviePy.
!pip install twelvelabs !pip install git+https://github.com/openai/whisper.git ffmpeg-python moviepy !DEBIAN_FRONTEND=noninteractive apt-get install -y ffmpeg
This ensures that all dependencies are available for embedding generation, audio processing, and transcription tasks.
Step 2: Import Libraries
In the second cell, import the installed libraries into your environment. These include TwelveLabs for embedding generation, Snowpark for interacting with Snowflake, and Streamlit for the frontend application.
from twelvelabs import TwelveLabs from snowflake.snowpark.context import get_active_session import streamlit as st import pandas as pd import snowflake.cortex as cortex session = get_active_session()
This initializes the Snowflake session and sets up the necessary tools for embedding creation and processing.
Step 3: Provide Video URLs
In the third cell, define a list of publicly accessible video URLs to be processed. These videos will serve as input for generating embeddings.
video_urls = ['http://commondatastorage.googleapis.com/gtv-videos-bucket/sample/ForBiggerJoyrides.mp4', 'http://commondatastorage.googleapis.com/gtv-videos-bucket/sample/ForBiggerMeltdowns.mp4', 'https://commondatastorage.googleapis.com/gtv-videos-bucket/sample/WeAreGoingOnBullrun.mp4']
Step 4: Create a Snowpark UDTF for Embedding Generation
Next, we define and register a create_video_embeddings User Defined Table Function (UDTF) in Snowpark to generate embeddings using TwelveLabs Embed API.
Key components of this step include:
Adding the
twelvelabs.zippackage to your environment.Specifying external access integrations and secrets for secure API access.
Defining an output schema with a VECTOR datatype for embeddings.
from snowflake.snowpark.functions import udtf from snowflake.snowpark.types import StructType, StructField, FloatType, StringType, VectorType session.clear_imports() session.add_import('@"DASH_DB"."DASH_SCHEMA"."DASH_PKGS"/twelvelabs.zip') @udtf(name="create_video_embeddings", packages=['httpx','pydantic'], external_access_integrations=['twelvelabs_access_integration'], secrets={'cred': 'twelve_labs_api'}, if_not_exists=True, is_permanent=True, stage_location='@DASH_DB.DASH_SCHEMA.DASH_UDFS', output_schema=StructType([ StructField("embedding", VectorType(float,1024)), StructField("start_offset_sec", FloatType()), StructField("end_offset_sec", FloatType()), StructField("embedding_scope", StringType()) ]) ) class create_video_embeddings: def __init__(self): from twelvelabs import TwelveLabs from twelvelabs.models.embed import EmbeddingsTask import _snowflake twelve_labs_api_key = _snowflake.get_generic_secret_string('cred') twelvelabs_client = TwelveLabs(api_key=twelve_labs_api_key) self.twelvelabs_client = twelvelabs_client def process(self, video_url: str) -> Iterable[Tuple[list, float, float, str]]: # Create an embeddings task task = self.twelvelabs_client.embed.task.create( model_name="Marengo-retrieval-2.7", video_url=video_url ) # Wait for the task to complete status = task.wait_for_done(sleep_interval=60) # Retrieve and process embeddings task = task.retrieve() if task.video_embedding is not None and task.video_embedding.segments is not None: for segment in task.video_embedding.segments: yield ( segment.embeddings_float, # Embedding (list of floats) segment.start_offset_sec, # Start offset in seconds segment.end_offset_sec, # End offset in seconds segment.embedding_scope, # Embedding scope )
Step 5: Generate Embeddings and Save to Snowflake
Use a Snowpark DataFrame to process the list of video URLs in parallel and save the generated embeddings into a Snowflake table called video_embeddings.
df = session.create_dataframe(video_urls, schema=['url']) df = df.join_table_function(create_video_embeddings(df['url']).over(partition_by="url")) df.write.mode('overwrite').save_as_table('video_embeddings') df = session.table('video_embeddings')
Step 6: Transcribe Video Clips
Download OpenAI’s Whisper model and define helper functions to download videos, extract audio clips, and transcribe them.
import urllib.request import os from moviepy import VideoFileClip import whisper import warnings import logging # Suppress Whisper warnings warnings.filterwarnings("ignore", category=FutureWarning) warnings.filterwarnings("ignore", category=UserWarning) # Set MoviePy logger level to ERROR or CRITICAL to suppress INFO logs logging.getLogger("moviepy").setLevel(logging.ERROR) # Load the Whisper model once whisper_model = whisper.load_model("base") # or any other model you want to use, e.g., 'small', 'medium', 'large' def download_video(video_url, output_video_path, status): try: # status.caption("Downloading video file...") urllib.request.urlretrieve(video_url, output_video_path) # status.caption(f"Video downloaded to {output_video_path}.") return output_video_path except Exception as e: status.caption(f"An error occurred during video download: {e}") return None def extract_audio_from_video(video_path, output_audio_path, status, start_time=None, end_time=None): try: # status.caption("Extracting audio from video...") video_clip = VideoFileClip(video_path) # If start and end times are provided, trim the video if start_time is not None or end_time is not None: video_clip = video_clip.subclipped(start_time, end_time) video_clip.audio.write_audiofile(output_audio_path) # status.caption(f"Audio extracted to {output_audio_path}.") return output_audio_path except Exception as e: status.caption(f"An error occurred during audio extraction: {e}") return None def transcribe_with_whisper(audio_path, status): try: # status.caption("Transcribing audio with Whisper...") result = whisper_model.transcribe(audio_path) # status.caption("Transcription complete.") return result["text"] except Exception as e: status.caption(f"An error occurred during transcription: {e}") return None def transcribe_video(video_url, status, temp_video_path="temp_video.mp4", temp_audio_path="temp_audio.mp3"): try: # Step 1: Download video video_path = download_video(video_url, temp_video_path, status) if not video_path: return None # Step 2: Extract audio from video audio_path = extract_audio_from_video(video_path, temp_audio_path, status) if not audio_path: return None # Step 3: Transcribe audio with Whisper transcription = transcribe_with_whisper(audio_path, status) return transcription finally: # Clean up temporary files if os.path.exists(temp_video_path): os.remove(temp_video_path) # status.caption("Temporary video file removed.") if os.path.exists(temp_audio_path): os.remove(temp_audio_path) # status.caption("Temporary audio file removed.") def transcribe_video_clip(video_url, status, start_time, end_time, temp_video_path="temp_video.mp4", temp_audio_path="temp_audio_clip.mp3"): try: # Step 1: Download video video_path = download_video(video_url, temp_video_path, status) if not video_path: return None # Step 2: Extract audio from the specified clip audio_path = extract_audio_from_video(video_path, temp_audio_path, status, start_time, end_time) if not audio_path: return None # Step 3: Transcribe the extracted audio clip with Whisper transcription = transcribe_with_whisper(audio_path, status) return transcription finally: # Clean up temporary files if os.path.exists(temp_video_path): os.remove(temp_video_path) # status.caption("Temporary video file removed.") if os.path.exists(temp_audio_path): os.remove(temp_audio_path) # status.caption("Temporary audio file removed.")
These functions will be used later to process video clips retrieved during similarity searches.
Step 7: Define Similarity Search Function
Create a similarity_scores function to calculate similarity scores between text queries and stored video embeddings using VECTOR_COSINE_SIMILARITY in Snowflake.
# TODO: Replace tlk_XXXXXXXXXXXXXXXXXX with your Twelve Labs API Key TWELVE_LABS_API_KEY ="tlk_XXXXXXXXXXXXXXXXXX" # Initialize the Twelve Labs client twelvelabs_client = TwelveLabs(api_key=TWELVE_LABS_API_KEY) def truncate_text(text, max_tokens=77): # Truncate text to roughly 77 tokens (assuming ~6 chars per token on average) return text[:max_tokens * 6] # Adjust based on actual tokenization behavior def similarity_scores(search_text,results_limit=5): # Twelve Labs Embed API supports text-to-embedding truncated_text = truncate_text(search_text, max_tokens=77) twelvelabs_response = twelvelabs_client.embed.create( model_name="Marengo-retrieval-2.7", text=truncated_text, text_truncate='start' ) if twelvelabs_response.text_embedding is not None and twelvelabs_response.text_embedding.segments is not None: text_query_embeddings = twelvelabs_response.text_embedding.segments[0].embeddings_float return session.sql(f""" SELECT URL as VIDEO_URL,START_OFFSET_SEC,END_OFFSET_SEC, round(VECTOR_COSINE_SIMILARITY(embedding::VECTOR(FLOAT, 1024),{text_query_embeddings}::VECTOR(FLOAT, 1024)),2) as SIMILARITY_SCORE from video_embeddings order by similarity_score desc limit {results_limit}""") else: return twelvelabs_response
Step 8: Build Streamlit Application
Develop an interactive Streamlit app that:
Accepts user input (search text, max results).
Retrieves matching video clips using
similarity_scores.Transcribes each clip using Whisper.
Summarizes results with Snowflake Cortex Complete.
st.subheader("Search Clips Application") with st.container(): with st.expander("Enter search text and select max results", expanded=True): left_col,mid_col,right_col = st.columns(3) with left_col: entered_text = st.text_input('Search Text') with mid_col: max_results = st.selectbox('Max Results',(1,2,3,4,5)) with right_col: selected_llm = st.selectbox('Select Summary LLM',('llama3.2-3b','llama3.1-405b','mistral-large2', 'snowflake-arctic',)) with st.container(): _,mid_col1,_ = st.columns([.3,.4,.2]) with mid_col1: similarity_scores_btn = st.button('Search and Summarize Matching Video Clips',type="primary") with st.container(): if similarity_scores_btn: if entered_text: with st.status("In progress...") as status: df = similarity_scores(entered_text,max_results).to_pandas() status.subheader(f"Top {max_results} clip(s) for search query '{entered_text}'") for row in df.itertuples(): transcribed_clip = transcribe_video_clip(row.VIDEO_URL, status, row.START_OFFSET_SEC, row.END_OFFSET_SEC) prompt = f""" [INST] Summarize the following and include name of the video as well as start and end clip times in seconds with everything in natural language as opposed to attributes: ### Video URL: {row.VIDEO_URL}, Clip Start: {row.START_OFFSET_SEC} | Clip End: {row.END_OFFSET_SEC} | Similarity Score: {row.SIMILARITY_SCORE} Clip Transcript: {transcribed_clip} ### [/INST] """ status.write(f"Video URL: {row.VIDEO_URL}") status.caption(f"-- Clip Start: {row.START_OFFSET_SEC} | Clip End: {row.END_OFFSET_SEC} | Similarity Score: {row.SIMILARITY_SCORE}") status.caption(f"-- Clip Transcript: {transcribed_clip}") status.write(f"Summary: {cortex.Complete(selected_llm,prompt)}") status.divider() status.update(label="Done!", state="complete", expanded=True) else: st.caption("User ERROR: Please enter search text!")
Search Examples
For example queries like "Welcome home, Buster," the app displays:
Video URL.
Clip start/end times.
Similarity score.
Transcription.
Summary generated by Cortex Complete.
The top result shown above is from this video. You can see clearly that “Welcome home, Buster” is highlighted in the white banner.
Let’s try another search query “A white car and a black car” and see the app display.
The top result shown above is from this video. You can see clearly that there are a white car and a black car in the frame.
4 - Use Cases and Benefits
The workflow above enables developers to build innovative video applications:
Contextual Personalized Ads: Combine TwelveLabs' multimodal embeddings with Snowflake's user data to deliver relevant, brand-safe video advertisements. This deep understanding of video context helps align ads with user preferences while maintaining safety standards.
Video Search Engines: Create sophisticated search applications that match natural language queries with video embeddings for precise results.
Content Moderation: Screen video libraries for inappropriate or sensitive content by analyzing visual, audio, and textual elements.
Recommendation Systems: Boost user engagement through video recommendations based on contextual understanding and viewing patterns.
Training Data Curation: Select diverse and representative samples for multimodal video datasets through video embedding analysis.
The integration of TwelveLabs with Snowflake offers significant business value through enhanced video understanding capabilities. TwelveLabs' multimodal embeddings provide comprehensive analysis of video content by capturing visuals, audio, and text in context. The integration leverages Snowflake's Container Runtime to create a scalable, native environment that significantly reduces operational complexity. Additionally, the ability to store and process embeddings using Snowflake's VECTOR datatype enables efficient similarity searches and downstream AI applications.
From a developer perspective, the integration streamlines productivity by providing simplified workflows through Snowpark Python UDTFs for parallel video processing. Developers can also implement real-time semantic search and leverage Snowflake Cortex Complete for advanced summarization tasks.
Finally, the solution delivers exceptional performance and reliability by combining TwelveLabs' state-of-the-art video-native models for low-latency embedding generation with Snowflake's robust infrastructure, ensuring secure and high-throughput processing capabilities.
5 - Conclusion
The integration of TwelveLabs Embed API with Snowflake Cortex empowers developers to unlock the full potential of video data. By combining advanced multimodal video understanding with Snowflake’s scalable AI Data Cloud, businesses can create innovative applications for search, personalization, moderation, and more. This partnership showcases the synergy between TwelveLabs’ cutting-edge technology and Snowflake’s enterprise-grade infrastructure, driving value for developers and organizations alike.
Call to Action
Ready to transform your video data into actionable intelligence?
Try the Integration: Sign up for the TwelveLabs Embed API Open Beta and start building your own AI-powered video applications in Snowflake today.
Explore More Use Cases: Visit the Snowflake QuickStart Guide to learn how to implement similar workflows tailored to your business needs.
Join the Conversation: Share your feedback on this integration in the TwelveLabs Discord and Snowflake developer community forum.
Related articles

Announcing TwelveLabs Claude Code Plugin: Work With Videos Without Leaving Your Terminal

The Apparatus: Building the Machine That Runs While We Don't

How TwelveLabs Saves Hours of Manual Video Annotation with a Few API Calls

From Raw Surveillance to Training-Ready Datasets in Minutes: Building an Automated Video Curator with TwelveLabs and FiftyOne




© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved
© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved
© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved