WHAT OUR PARTNERS ARE SAYING
How to find brand logos within videos using Twelve Labs API?

Ankit Khare
A tutorial on performing logo detection within videos using Twelve Labs API
A tutorial on performing logo detection within videos using Twelve Labs API

In this article
Join our newsletter
Join our newsletter
Receive the latest advancements, tutorials, and industry insights in video understanding
Receive the latest advancements, tutorials, and industry insights in video understanding
Search, analyze, and explore your videos with AI.
Jun 9, 2023
13 min
Copy link to article
Introduction
Logo detection in videos refers to the automated process of identifying and recognizing logos or trademarks embedded within video content. This involves dissecting video frames or segments to detect and locate specific logo patterns or visual elements associated with a brand. This technology empowers us to quickly navigate through video content, accurately identifying the specific instances when certain logo patterns manifest on screen. Logo detection in videos refers to the automated process of identifying and recognizing logos or trademarks embedded within video content. This involves dissecting video frames or segments to detect and locate specific logo patterns or visual elements associated with a brand. This technology empowers us to quickly navigate through video content, accurately identifying the specific instances when certain logo patterns manifest on screen. Logo detection in video data can identify a wide range of elements, and thus, it has a broad array of applications across various industry verticals:
Advertising and marketing: Companies can monitor their brand presence and visibility across different media, both online and offline. It helps in assessing the impact of marketing campaigns, identifying unauthorized use of logos, and understanding competitors' marketing strategies.
Social media monitoring: Logo detection helps brands understand where and how often their logo appears in user-generated content. It can provide insights into brand popularity, usage context, and sentiment analysis.
Retail and e-commerce: Retailers can use logo detection to monitor and manage their inventory. For example, it can help identify counterfeit products or unauthorized sellers.
Sports sponsorship: Logo detection can quantify brand exposure during live broadcasts of sports events. It can provide insights into the value delivered to sponsors and advertisers.
Media and entertainment: In the entertainment industry, logo detection can be used to track product placements in movies and TV shows. It can also identify copyright infringements.
Security and surveillance: Logo detection can aid in identifying and tracking vehicles or objects based on company logos for security purposes.
Automotive: In the automotive industry, logo detection can help identify car makes and models, aiding in traffic analysis, parking management, or autonomous driving systems.
In this tutorial, we're going to delve into the world of logo detection from two distinct perspectives and levels. The first one is at the video level, where we tackle the entire video content as a single entity, seeking to unearth every bit of logo information it contains. The second approach, the index level, narrows our lens to concentrate on a specific logo or a group of logos. We'll employ natural language queries to conduct an exhaustive search across a rich library of videos indexed on the Twelve Labs platform.
Here's the best part – with Twelve Labs API at your fingertips, you can achieve all of this without getting bogged down in the intricacies of model training, deployment, inference, or load scaling that make up the detection process. We've got you covered from development to infrastructure, and even provide continuous support. So, buckle up and join us on this fascinating journey into the domain of logo detection.
Text-in-video vs Logo detection - potential overlap
There may be instances where a logo is simply the name of a brand or company, leading to questions about whether it could be treated as text on screen, and if text-in-video indexing and search options might suffice for logo detection. It's true that such text will be detected as it appears on screen during video playback. However, in cases where text might have different meanings in different contexts, specifically configuring the indexing and search options to detect logos is key.
For instance, 'Amazon' could refer to the multinational technology company or the South American river. If you employ logo detection, the system will differentiate between searches for Amazon's brand logo and the text 'Amazon'. Hence, even though text-in-video and logo detection may seemingly overlap in cases where the brand logo is text-based, choosing to use the logo detection feature should be intentional to ensure accurate results.
Prerequisites
The Twelve Labs platform is presently in open beta, and we are offering free video indexing credits for up to 10 hours upon sign-up. I'd recommend familiarizing yourself with the core aspects of the Twelve Labs platform prior to embarking on this tutorial. A solid understanding of concepts such as video indexing, indexing options, the Task API, and search options is essential to seamlessly navigate through this tutorial. I've covered these topics in depth in my first tutorial. Nonetheless, if you encounter any obstacles or find yourself stuck at any point, please feel free to reach out. I'm here to assist you on this exciting journey into the realm of logo detection. Additionally, our response times on our Discord server are lightning fast 🚅🏎️⚡️ if Discord is your preferred platform.
A Quick Guide to the Tutorial
In continuation with our previous discussion, we'll delve into logo detection from two distinct perspectives and levels. I've segmented this tutorial into two crucial sections, culminating in a final demonstration where we amalgamate all elements into a fully functional web-app:
Logo Detection in Three Easy Steps
The extraction of recognized logos from a specific video involves the following three steps:
Video indexing - There should be no surprises here; if you've been keeping up with my previous tutorials, this step will feel like second nature.
Retrieving the unique identifier of the video - Once the Twelve Labs platform completes the indexing of our video, we will fetch the unique identifier of the video we need the logo detection for.
Extracting the logos appearing on screen - We'll zero in on the video by utilizing the specific index we've created and the video id associated with the video we need logo detection for. The API will shoulder the heavy lifting, delivering the results we're seeking.
Logo Search - searching for specific logo(s) within all indexed videos
Applying logo detection on the entire video enabled us to scrutinize and distill it for all instances of logo pattern(s). Now, the logo search feature empowers us to zero in on precise moments or video snippets where the input or searched logo or brand name materializes. This greatly diminishes the time spent perusing a sizable catalogue of videos, yielding accurate search results predicated on alignment of search terms with the logo that becomes visible on screen during video playbacks.
In our earlier tutorials, we delved into content search within indexed videos, utilizing natural language queries and a variety of search options like visual (audio-visual search), conversation (dialogue search), and text-in-video (OCR). In this tutorial, we'll pivot our approach, harnessing exclusively the logo detection pipeline to search for logo(s) within indexed videos. To maximize processing efficiency and minimize costs, we'll establish an index using solely the 'logo' indexing option. Subsequently, we'll trigger our search query with the 'logo' search option, thereby enabling us to uncover relevant logo matches within the indexed videos.
Building the Demo App
To tie everything together, we will utilize the data generated by the API endpoints and present them on a webpage, spinning up a demo app based on Flask that hosts a minimalistic HTML page. The outcome of the logo detection process will be systematically tabulated, exhibiting timestamps and their corresponding logo names. The logo search section, on the other hand, will display the query we used and the relevant video segments we discovered in response.
Detecting logos in three simple steps
For the sake of simplicity, I've uploaded just five videos to an index using a pre-existing account. Feel free to sign up; given we're currently in open beta, you'll receive complimentary credits allowing you to index up to 10 hours of video content. If your needs extend beyond that, check out our pricing page for upgrading to the Developer plan.
Video Indexing
Here, we’re going to delve into the essential elements that we'll need to include in our Jupyter notebook. This includes the necessary imports, defining API URLs, creating the index, and uploading videos from our local file system to kick off the indexing process:
<pre><code class="python">%env API_URL = https://api.twelvelabs.io/v1.1 %env API_KEY= <your API key> !pip install requests import os import requests import glob from pprint import pprint # Retrieve the URL of the API and my API key API_URL = os.getenv("API_URL") assert API_URL API_KEY = os.getenv("API_KEY") assert API_KEY </code></pre>
<pre><code class="python">%env API_URL = https://api.twelvelabs.io/v1.1 %env API_KEY= <your API key> !pip install requests import os import requests import glob from pprint import pprint # Retrieve the URL of the API and my API key API_URL = os.getenv("API_URL") assert API_URL API_KEY = os.getenv("API_KEY") assert API_KEY </code></pre>
<pre><code class="python"># Construct the URL of the `/indexes` endpoint INDEXES_URL = f"{API_URL}/indexes" # Set the header of the request default_header = { "x-api-key": API_KEY } # Define a function to create an index with a given name def create_index(index_name, index_options, engine): # Declare a dictionary named data data = { "engine_id": engine, "index_options": index_options, "index_name": index_name, } # Create an index response = requests.post(INDEXES_URL, headers=default_header, json=data) # Store the unique identifier of your index INDEX_ID = response.json().get('_id') # Check if the status code is 201 and print success if response.status_code == 201: print(f"Status code: {response.status_code} - The request was successful and a new index was created.") else: print(f"Status code: {response.status_code}") pprint(response.json()) return INDEX_ID # Create the indexes index_id = create_index(index_name = "extract_text", index_options=["logo"], engine = "marengo2.5") # Print the created index IDs print(f"Created index IDs: {index_id}") </code></pre>
<pre><code class="python"># Construct the URL of the `/indexes` endpoint INDEXES_URL = f"{API_URL}/indexes" # Set the header of the request default_header = { "x-api-key": API_KEY } # Define a function to create an index with a given name def create_index(index_name, index_options, engine): # Declare a dictionary named data data = { "engine_id": engine, "index_options": index_options, "index_name": index_name, } # Create an index response = requests.post(INDEXES_URL, headers=default_header, json=data) # Store the unique identifier of your index INDEX_ID = response.json().get('_id') # Check if the status code is 201 and print success if response.status_code == 201: print(f"Status code: {response.status_code} - The request was successful and a new index was created.") else: print(f"Status code: {response.status_code}") pprint(response.json()) return INDEX_ID # Create the indexes index_id = create_index(index_name = "extract_text", index_options=["logo"], engine = "marengo2.5") # Print the created index IDs print(f"Created index IDs: {index_id}") </code></pre>
Uploading five formula one race videos to the index we've just created. I have downloaded these videos from their some formula one related YouTube channels and saved them in a folder named 'static' on my local hard drive. We'll use these local files to index the videos onto the Twelve Labs platform:
<pre><code class="python">import os import requests from concurrent.futures import ThreadPoolExecutor TASKS_URL = f"{API_URL}/tasks" TASK_ID_LIST = [] video_folder = 'static' # folder containing the video files def upload_video(file_name): # Validate if a video already exists in the index task_list_response = requests.get( TASKS_URL, headers=default_header, params={"index_id": INDEX_ID, "filename": file_name}, ) if "data" in task_list_response.json(): task_list = task_list_response.json()["data"] if len(task_list) > 0: if task_list[0]['status'] == 'ready': print(f"Video '{file_name}' already exists in index {INDEX_ID}") else: print("task pending or validating") return # Proceed further to create a new task to index the current video if the video didn't exist in the index already print("Entering task creation code for the file: ", file_name) if file_name.endswith('.mp4'): # Make sure the file is an MP4 video file_path = os.path.join(video_folder, file_name) # Get the full path of the video file with open(file_path, "rb") as file_stream: data = { "index_id": INDEX_ID, "language": "en" } file_param = [ ("video_file", (file_name, file_stream, "application/octet-stream")),] #The video will be indexed on the platform using the same name as the video file itself. response = requests.post(TASKS_URL, headers=default_header, data=data, files=file_param) TASK_ID = response.json().get("_id") TASK_ID_LIST.append(TASK_ID) # Check if the status code is 201 and print success if response.status_code == 201: print(f"Status code: {response.status_code} - The request was successful and a new resource was created.") else: print(f"Status code: {response.status_code}") print(f"File name: {file_name}") pprint(response.json()) print("\n") # Get list of video files video_files = [f for f in os.listdir(video_folder) if f.endswith('.mp4')] # Create a ThreadPoolExecutor with ThreadPoolExecutor() as executor: # Use executor to run upload_video in parallel for all video files executor.map(upload_video, video_files) </code></pre>
<pre><code class="python">import os import requests from concurrent.futures import ThreadPoolExecutor TASKS_URL = f"{API_URL}/tasks" TASK_ID_LIST = [] video_folder = 'static' # folder containing the video files def upload_video(file_name): # Validate if a video already exists in the index task_list_response = requests.get( TASKS_URL, headers=default_header, params={"index_id": INDEX_ID, "filename": file_name}, ) if "data" in task_list_response.json(): task_list = task_list_response.json()["data"] if len(task_list) > 0: if task_list[0]['status'] == 'ready': print(f"Video '{file_name}' already exists in index {INDEX_ID}") else: print("task pending or validating") return # Proceed further to create a new task to index the current video if the video didn't exist in the index already print("Entering task creation code for the file: ", file_name) if file_name.endswith('.mp4'): # Make sure the file is an MP4 video file_path = os.path.join(video_folder, file_name) # Get the full path of the video file with open(file_path, "rb") as file_stream: data = { "index_id": INDEX_ID, "language": "en" } file_param = [ ("video_file", (file_name, file_stream, "application/octet-stream")),] #The video will be indexed on the platform using the same name as the video file itself. response = requests.post(TASKS_URL, headers=default_header, data=data, files=file_param) TASK_ID = response.json().get("_id") TASK_ID_LIST.append(TASK_ID) # Check if the status code is 201 and print success if response.status_code == 201: print(f"Status code: {response.status_code} - The request was successful and a new resource was created.") else: print(f"Status code: {response.status_code}") print(f"File name: {file_name}") pprint(response.json()) print("\n") # Get list of video files video_files = [f for f in os.listdir(video_folder) if f.endswith('.mp4')] # Create a ThreadPoolExecutor with ThreadPoolExecutor() as executor: # Use executor to run upload_video in parallel for all video files executor.map(upload_video, video_files) </code></pre>
Retrieving the unique identifier of the video
Now let's enumerate all the videos in our index. This allows us to retain the video ID of a specific video, the goal being to extract all the text embedded within it. Furthermore, akin to our methods in prior tutorials, I'm assembling a list of video IDs and their respective titles, designed to be subsequently fed into our Flask application.
<pre><code class="python"># List all the videos in an index default_header = { "x-api-key": API_KEY } INDEX_ID='##4a73aa8b1dd6cde172a9##' INDEXES_VIDEOS_URL = f"{API_URL}/indexes/{INDEX_ID}/videos" response = requests.get(INDEXES_VIDEOS_URL, headers=default_header) response_json = response.json() pprint(response_json) video_id_name_list = [{'video_id': video['_id'], 'video_name': video['metadata']['filename']} for video in response_json['data']] pprint(video_id_name_list) </code></pre>
<pre><code class="python"># List all the videos in an index default_header = { "x-api-key": API_KEY } INDEX_ID='##4a73aa8b1dd6cde172a9##' INDEXES_VIDEOS_URL = f"{API_URL}/indexes/{INDEX_ID}/videos" response = requests.get(INDEXES_VIDEOS_URL, headers=default_header) response_json = response.json() pprint(response_json) video_id_name_list = [{'video_id': video['_id'], 'video_name': video['metadata']['filename']} for video in response_json['data']] pprint(video_id_name_list) </code></pre>
Output:
<pre><code class="python">{'data': [{'_id': '##d978c86daab572f3481##', 'created_at': '2023-04-17T18:56:51Z', 'metadata': {'duration': 1800.56, 'engine_id': 'marengo2.5', 'filename': '20211113T190000Z.mp4', 'fps': 25, 'height': 396, 'size': 415876158, 'width': 704}, 'updated_at': '2023-04-17T19:01:32Z'}, {'_id': '##3d975786daab572f3481##', 'created_at': '2023-04-17T18:56:44Z', 'metadata': {'duration': 1800.56, 'engine_id': 'marengo2.5', 'filename': '20211114T170000Z.mp4', 'fps': 25, 'height': 396, 'size': 387273943, 'width': 704}, 'updated_at': '2023-04-17T19:00:39Z'}, {'_id': '##3d972e86daab572f3481##', 'created_at': '2023-04-17T18:56:38Z', 'metadata': {'duration': 1800.56, 'engine_id': 'marengo2.5', 'filename': '20211113T193000Z.mp4', 'fps': 25, 'height': 396, 'size': 386209689, 'width': 704}, 'updated_at': '2023-04-17T18:59:58Z'}, {'_id': '##3d96d386daab572f3481##', 'created_at': '2023-04-17T18:56:28Z', 'metadata': {'duration': 1800.52, 'engine_id': 'marengo2.5', 'filename': '20211121T133000Z.mp4', 'fps': 25, 'height': 396, 'size': 348611416, 'width': 704}, 'updated_at': '2023-04-17T18:58:27Z'}, {'_id': '##3d96af86daab572f3481##', 'created_at': '2023-04-17T18:56:08Z', 'metadata': {'duration': 1800.56, 'engine_id': 'marengo2.5', 'filename': '20211113T200000Z.mp4', 'fps': 25, 'height': 396, 'size': 327766175, 'width': 704}, 'updated_at': '2023-04-17T18:57:51Z'}], 'page_info': {'limit_per_page': 10, 'page': 1, 'total_duration': 9002.76, 'total_page': 1, 'total_results': 5}} [{'video_id': '##3d978c86daab572f3481##', 'video_name': '20211113T190000Z.mp4'}, {'video_id': '##3d975786daab572f3481##', 'video_name': '20211114T170000Z.mp4'}, {'video_id': '##3d972e86daab572f3481##', 'video_name': '20211113T193000Z.mp4'}, {'video_id': '##3d96d386daab572f3481##', 'video_name': '20211121T133000Z.mp4'}, {'video_id': '##3d96af86daab572f3481##', 'video_name': '20211113T200000Z.mp4'}] </code></pre>
<pre><code class="python">{'data': [{'_id': '##d978c86daab572f3481##', 'created_at': '2023-04-17T18:56:51Z', 'metadata': {'duration': 1800.56, 'engine_id': 'marengo2.5', 'filename': '20211113T190000Z.mp4', 'fps': 25, 'height': 396, 'size': 415876158, 'width': 704}, 'updated_at': '2023-04-17T19:01:32Z'}, {'_id': '##3d975786daab572f3481##', 'created_at': '2023-04-17T18:56:44Z', 'metadata': {'duration': 1800.56, 'engine_id': 'marengo2.5', 'filename': '20211114T170000Z.mp4', 'fps': 25, 'height': 396, 'size': 387273943, 'width': 704}, 'updated_at': '2023-04-17T19:00:39Z'}, {'_id': '##3d972e86daab572f3481##', 'created_at': '2023-04-17T18:56:38Z', 'metadata': {'duration': 1800.56, 'engine_id': 'marengo2.5', 'filename': '20211113T193000Z.mp4', 'fps': 25, 'height': 396, 'size': 386209689, 'width': 704}, 'updated_at': '2023-04-17T18:59:58Z'}, {'_id': '##3d96d386daab572f3481##', 'created_at': '2023-04-17T18:56:28Z', 'metadata': {'duration': 1800.52, 'engine_id': 'marengo2.5', 'filename': '20211121T133000Z.mp4', 'fps': 25, 'height': 396, 'size': 348611416, 'width': 704}, 'updated_at': '2023-04-17T18:58:27Z'}, {'_id': '##3d96af86daab572f3481##', 'created_at': '2023-04-17T18:56:08Z', 'metadata': {'duration': 1800.56, 'engine_id': 'marengo2.5', 'filename': '20211113T200000Z.mp4', 'fps': 25, 'height': 396, 'size': 327766175, 'width': 704}, 'updated_at': '2023-04-17T18:57:51Z'}], 'page_info': {'limit_per_page': 10, 'page': 1, 'total_duration': 9002.76, 'total_page': 1, 'total_results': 5}} [{'video_id': '##3d978c86daab572f3481##', 'video_name': '20211113T190000Z.mp4'}, {'video_id': '##3d975786daab572f3481##', 'video_name': '20211114T170000Z.mp4'}, {'video_id': '##3d972e86daab572f3481##', 'video_name': '20211113T193000Z.mp4'}, {'video_id': '##3d96d386daab572f3481##', 'video_name': '20211121T133000Z.mp4'}, {'video_id': '##3d96af86daab572f3481##', 'video_name': '20211113T200000Z.mp4'}] </code></pre>
Extracting the logo appearing on screen
Time to put our plan into action! We'll now proceed to extract all logo content from the chosen video:
<pre><code class="python">VIDEO_ID = '###a849b86daab572f349242' LOGO_URL = f"{API_URL}/indexes/{INDEX_ID}/videos/{VIDEO_ID}/logo" response = requests.get(LOGO_URL, headers=default_header) print (f"Status code: {response.status_code}") logo_data = response.json() pprint (logo_data) </code></pre>
<pre><code class="python">VIDEO_ID = '###a849b86daab572f349242' LOGO_URL = f"{API_URL}/indexes/{INDEX_ID}/videos/{VIDEO_ID}/logo" response = requests.get(LOGO_URL, headers=default_header) print (f"Status code: {response.status_code}") logo_data = response.json() pprint (logo_data) </code></pre>
Output:
<pre><code class="python">Status code: 200 {'data': [{'end': 16, 'start': 15, 'value': 'Ducati Corse'}, {'end': 23, 'start': 22, 'value': 'Bank of Jordan'}, {'end': 23, 'start': 22, 'value': 'Han Chiang High School'}, {'end': 24, 'start': 23, 'value': 'Peugeot'}, {'end': 25, 'start': 24, 'value': 'Dr Lal Path Labs'}, {'end': 26, 'start': 25, 'value': 'Z8Games'}, {'end': 29, 'start': 27, 'value': 'Sky Sports'}, {'end': 29, 'start': 28, 'value': 'Tout'}, {'end': 31, 'start': 30, 'value': 'Sky UK'}, {'end': 31, 'start': 30, 'value': 'New Balance'}, {'end': 31, 'start': 30, 'value': 'Industria'}, {'end': 33, 'start': 32, 'value': 'Esport3'}, {'end': 35, 'start': 32, 'value': 'Nissan'}, {'end': 33, 'start': 32, 'value': 'GoCar'}, {'end': 34, 'start': 33, 'value': 'Land Bank of the Philippines'}, {'end': 34, 'start': 33, 'value': 'Z8Games'}, {'end': 37, 'start': 36, 'value': 'Tout'}, {'end': 37, 'start': 36, 'value': 'Zazzle'}, {'end': 39, 'start': 38, 'value': 'Z8Games'}, {'end': 39, 'start': 38, 'value': 'Giochi Preziosi'}, {'end': 41, 'start': 40, 'value': 'Mini'}], 'id': '###a849b86daab572f349242', 'index_id': '###a73aa8b1dd6cde172a933'} </code></pre>
<pre><code class="python">Status code: 200 {'data': [{'end': 16, 'start': 15, 'value': 'Ducati Corse'}, {'end': 23, 'start': 22, 'value': 'Bank of Jordan'}, {'end': 23, 'start': 22, 'value': 'Han Chiang High School'}, {'end': 24, 'start': 23, 'value': 'Peugeot'}, {'end': 25, 'start': 24, 'value': 'Dr Lal Path Labs'}, {'end': 26, 'start': 25, 'value': 'Z8Games'}, {'end': 29, 'start': 27, 'value': 'Sky Sports'}, {'end': 29, 'start': 28, 'value': 'Tout'}, {'end': 31, 'start': 30, 'value': 'Sky UK'}, {'end': 31, 'start': 30, 'value': 'New Balance'}, {'end': 31, 'start': 30, 'value': 'Industria'}, {'end': 33, 'start': 32, 'value': 'Esport3'}, {'end': 35, 'start': 32, 'value': 'Nissan'}, {'end': 33, 'start': 32, 'value': 'GoCar'}, {'end': 34, 'start': 33, 'value': 'Land Bank of the Philippines'}, {'end': 34, 'start': 33, 'value': 'Z8Games'}, {'end': 37, 'start': 36, 'value': 'Tout'}, {'end': 37, 'start': 36, 'value': 'Zazzle'}, {'end': 39, 'start': 38, 'value': 'Z8Games'}, {'end': 39, 'start': 38, 'value': 'Giochi Preziosi'}, {'end': 41, 'start': 40, 'value': 'Mini'}], 'id': '###a849b86daab572f349242', 'index_id': '###a73aa8b1dd6cde172a933'} </code></pre>
Clearly, the API skillfully extracted all the on-screen logos line by line. This information can be stored as metadata for subsequent workflows, including content filtering, classification, and search purposes. Please note that the output displayed here is abbreviated for conciseness - the actual output was considerably more extensive.
Logo Search - searching for specific logo(s) within all indexed videos
Launching our search query utilizing the logo search option to uncover pertinent logo pattern matches within our collection of indexed videos:
<pre><code class="python"># Construct the URL of the `/search` endpoint SEARCH_URL = f"{API_URL}/search/" # Declare a dictionary named `data` data = { "index_id": INDEX_ID, "query": "honda", "search_options": [ "logo" ] } # Extracting query to later pass it to flask application input_query = data["query"] # Make a search request response = requests.post(SEARCH_URL, headers=default_header, json=data) if response.status_code == 200: print(f"Status code: {response.status_code} - Success") else: print(f"Status code: {response.status_code}") pprint(response.json()) </code></pre>
<pre><code class="python"># Construct the URL of the `/search` endpoint SEARCH_URL = f"{API_URL}/search/" # Declare a dictionary named `data` data = { "index_id": INDEX_ID, "query": "honda", "search_options": [ "logo" ] } # Extracting query to later pass it to flask application input_query = data["query"] # Make a search request response = requests.post(SEARCH_URL, headers=default_header, json=data) if response.status_code == 200: print(f"Status code: {response.status_code} - Success") else: print(f"Status code: {response.status_code}") pprint(response.json()) </code></pre>
Output:
<pre><code class="python">Status code: 200 - Success {'data': [{'confidence': 'high', 'end': 19, 'metadata': [{'text': 'Honda', 'type': 'logo'}], 'score': 92.28, 'start': 18, 'video_id': '###d96af86daab572f348###'}, {'confidence': 'high', 'end': 104, 'metadata': [{'text': 'Honda', 'type': 'logo'}], 'score': 92.28, 'start': 103, 'video_id': '###d978c86daab572f348###'}, {'confidence': 'high', 'end': 137, 'metadata': [{'text': 'Honda', 'type': 'logo'}], 'score': 92.28, 'start': 136, 'video_id': '###d978c86daab572f348###'}, {'confidence': 'high', 'end': 269, 'metadata': [{'text': 'Honda', 'type': 'logo'}], 'score': 92.28, 'start': 268, 'video_id': '###d96af86daab572f348###'}, {'confidence': 'high', 'end': 392, 'metadata': [{'text': 'Honda', 'type': 'logo'}], 'score': 92.28, 'start': 391, 'video_id': '###d96af86daab572f348###'}, {'confidence': 'high', 'end': 478, 'metadata': [{'text': 'Honda', 'type': 'logo'}], 'score': 92.28, 'start': 477, 'video_id': '###d975786daab572f348###'}, {'confidence': 'high', 'end': 483, 'metadata': [{'text': 'Honda', 'type': 'logo'}], 'score': 92.28, 'start': 482, 'video_id': '###d978c86daab572f348###'}], 'page_info': {'limit_per_page': 10, 'next_page_token': 'fc3c420a-5971-428a-8796-9e5c077754c0-1', 'page_expired_at': '2023-05-26T18:40:26Z', 'total_results': 47}, 'search_pool': {'index_id': '###d9556f607a5a7bd9ea###', 'total_count': 5, 'total_duration': 9003}} </code></pre>
<pre><code class="python">Status code: 200 - Success {'data': [{'confidence': 'high', 'end': 19, 'metadata': [{'text': 'Honda', 'type': 'logo'}], 'score': 92.28, 'start': 18, 'video_id': '###d96af86daab572f348###'}, {'confidence': 'high', 'end': 104, 'metadata': [{'text': 'Honda', 'type': 'logo'}], 'score': 92.28, 'start': 103, 'video_id': '###d978c86daab572f348###'}, {'confidence': 'high', 'end': 137, 'metadata': [{'text': 'Honda', 'type': 'logo'}], 'score': 92.28, 'start': 136, 'video_id': '###d978c86daab572f348###'}, {'confidence': 'high', 'end': 269, 'metadata': [{'text': 'Honda', 'type': 'logo'}], 'score': 92.28, 'start': 268, 'video_id': '###d96af86daab572f348###'}, {'confidence': 'high', 'end': 392, 'metadata': [{'text': 'Honda', 'type': 'logo'}], 'score': 92.28, 'start': 391, 'video_id': '###d96af86daab572f348###'}, {'confidence': 'high', 'end': 478, 'metadata': [{'text': 'Honda', 'type': 'logo'}], 'score': 92.28, 'start': 477, 'video_id': '###d975786daab572f348###'}, {'confidence': 'high', 'end': 483, 'metadata': [{'text': 'Honda', 'type': 'logo'}], 'score': 92.28, 'start': 482, 'video_id': '###d978c86daab572f348###'}], 'page_info': {'limit_per_page': 10, 'next_page_token': 'fc3c420a-5971-428a-8796-9e5c077754c0-1', 'page_expired_at': '2023-05-26T18:40:26Z', 'total_results': 47}, 'search_pool': {'index_id': '###d9556f607a5a7bd9ea###', 'total_count': 5, 'total_duration': 9003}} </code></pre>
Once more, the API proficiently scoured and retrieved all on-screen logos corresponding to the input logo name, but this time across the entire index of videos we've uploaded.
Preparing the data for the Flask application to ensure our results will be presented neatly:
<pre><code class="python">video_data = [{'start': d['start'], 'end': d['end'], 'confidence': d['confidence'], 'text': d['metadata'][0]['text']} for d in search_data['data']] video_search_dict = {} for vd in video_data: if search_data['data'][0]['video_id'] in video_search_dict: video_search_dict[search_data['data'][0]['video_id']].append(vd) else: video_search_dict[search_data['data'][0]['video_id']] = [vd] pprint(video_search_dict) </code></pre>
<pre><code class="python">video_data = [{'start': d['start'], 'end': d['end'], 'confidence': d['confidence'], 'text': d['metadata'][0]['text']} for d in search_data['data']] video_search_dict = {} for vd in video_data: if search_data['data'][0]['video_id'] in video_search_dict: video_search_dict[search_data['data'][0]['video_id']].append(vd) else: video_search_dict[search_data['data'][0]['video_id']] = [vd] pprint(video_search_dict) </code></pre>
Output:
<pre><code class="python"> {'###d96af86daab572f348###': [{'confidence': 'high', 'end': 19, 'start': 18, 'text': 'Honda'}, {'confidence': 'high', 'end': 104, 'start': 103, 'text': 'Honda'}, {'confidence': 'high', 'end': 137, 'start': 136, 'text': 'Honda'}, {'confidence': 'high', 'end': 269, 'start': 268, 'text': 'Honda'}, {'confidence': 'high', 'end': 392, 'start': 391, 'text': 'Honda'}, {'confidence': 'high', 'end': 478, 'start': 477, 'text': 'Honda'}, {'confidence': 'high', 'end': 483, 'start': 482, 'text': 'Honda'}, {'confidence': 'high', 'end': 491, 'start': 487, 'text': 'Honda'}, {'confidence': 'high', 'end': 561, 'start': 560, 'text': 'Honda'}, {'confidence': 'high', 'end': 586, 'start': 585, 'text': 'Honda'}]} </code></pre>
<pre><code class="python"> {'###d96af86daab572f348###': [{'confidence': 'high', 'end': 19, 'start': 18, 'text': 'Honda'}, {'confidence': 'high', 'end': 104, 'start': 103, 'text': 'Honda'}, {'confidence': 'high', 'end': 137, 'start': 136, 'text': 'Honda'}, {'confidence': 'high', 'end': 269, 'start': 268, 'text': 'Honda'}, {'confidence': 'high', 'end': 392, 'start': 391, 'text': 'Honda'}, {'confidence': 'high', 'end': 478, 'start': 477, 'text': 'Honda'}, {'confidence': 'high', 'end': 483, 'start': 482, 'text': 'Honda'}, {'confidence': 'high', 'end': 491, 'start': 487, 'text': 'Honda'}, {'confidence': 'high', 'end': 561, 'start': 560, 'text': 'Honda'}, {'confidence': 'high', 'end': 586, 'start': 585, 'text': 'Honda'}]} </code></pre>
Further data preparation for the logo detection results, followed by our standard procedure of pickling everything:
<pre><code class="python">video_id = ocr_data.get('id') data_list = logo_data.get('data') data_to_save = { 'video_id': video_id, 'data_list': data_list, 'video_id_name_list': video_id_name_list, 'video_search_dict': video_search_dict } import pickle # Save data to a pickle file with open('data.pkl', 'wb') as f: pickle.dump(data_to_save, f) </code></pre>
<pre><code class="python">video_id = ocr_data.get('id') data_list = logo_data.get('data') data_to_save = { 'video_id': video_id, 'data_list': data_list, 'video_id_name_list': video_id_name_list, 'video_search_dict': video_search_dict } import pickle # Save data to a pickle file with open('data.pkl', 'wb') as f: pickle.dump(data_to_save, f) </code></pre>
Building the Demo App
Now we've reached the last stretch of our current journey – integrating everything to make our outputs come to life. Besides the standard configuration we implement for fetching videos from the local folder and loading the pickled data dispatched from the Jupyter notebook, this time we have some additional requirements - a conversion of timestamps from a seconds-only format to a minutes-and-seconds format. This makes the data visualization on the webpage more intuitive. Here's the code for the app.py file:
<pre><code class="python">from flask import Flask, render_template, send_from_directory import pickle import os from collections import defaultdict app = Flask(__name__) # Load data from a pickle file with open('data.pkl', 'rb') as f: loaded_data = pickle.load(f) # Access the data video_id = loaded_data['video_id'] data_list = loaded_data['data_list'] video_id_name_list = loaded_data['video_id_name_list'] video_search_dict = loaded_data['video_search_dict'] VIDEO_DIRECTORY = os.path.join(os.path.dirname(os.path.realpath(__file__)), "static") @app.route('/<path:filename>') def serve_video(filename): print(VIDEO_DIRECTORY, filename) return send_from_directory(directory=VIDEO_DIRECTORY, path=filename) @app.route('/') def home(): for item in data_list: if ":" not in str(item['start']): item['start'] = int(item['start']) item['start'] = f"{item['start'] // 60}:{item['start'] % 60:02}" if ":" not in str(item['end']): item['end'] = int(item['end']) item['end'] = f"{item['end'] // 60}:{item['end'] % 60:02}" video_id_name_dict = {video['video_id']: video['video_name'] for video in video_id_name_list} # video_name = video_id_name_dict.get(video_id) return render_template('index.html', data=data_list[:10], video_id_name_dict=video_id_name_dict, video_id=video_id, video_search_dict = video_search_dict) if __name__ == '__main__': app.run(debug=True) </code></pre>
<pre><code class="python">from flask import Flask, render_template, send_from_directory import pickle import os from collections import defaultdict app = Flask(__name__) # Load data from a pickle file with open('data.pkl', 'rb') as f: loaded_data = pickle.load(f) # Access the data video_id = loaded_data['video_id'] data_list = loaded_data['data_list'] video_id_name_list = loaded_data['video_id_name_list'] video_search_dict = loaded_data['video_search_dict'] VIDEO_DIRECTORY = os.path.join(os.path.dirname(os.path.realpath(__file__)), "static") @app.route('/<path:filename>') def serve_video(filename): print(VIDEO_DIRECTORY, filename) return send_from_directory(directory=VIDEO_DIRECTORY, path=filename) @app.route('/') def home(): for item in data_list: if ":" not in str(item['start']): item['start'] = int(item['start']) item['start'] = f"{item['start'] // 60}:{item['start'] % 60:02}" if ":" not in str(item['end']): item['end'] = int(item['end']) item['end'] = f"{item['end'] // 60}:{item['end'] % 60:02}" video_id_name_dict = {video['video_id']: video['video_name'] for video in video_id_name_list} # video_name = video_id_name_dict.get(video_id) return render_template('index.html', data=data_list[:10], video_id_name_dict=video_id_name_dict, video_id=video_id, video_search_dict = video_search_dict) if __name__ == '__main__': app.run(debug=True) </code></pre>
HTML Template
Now, it's time to weave together the final piece: our Jinja-2 based HTML template code. This pulls together all the data we've transmitted through the Flask app.py file. We'll kick things off by showcasing the logo detection results. The video player will cover the entire duration of the video, and just below it, a table will display the start, end, and text identified during that specific duration on the screen. To improve clarity, timestamps will be formatted in minutes-and-seconds and will be interactive, allowing us to jump to the exact timestamp and commence video playback from there. Keep in mind, I've converted the timestamps back to seconds when passing them to the JavaScript function playVideo, as this function is designed to accept timestamps in a seconds-only format for video playback.
<pre><code class="language-html"><!DOCTYPE html> <html> <head> <link rel="shortcut icon" href="#" /> <title>Logo Detection</title> <style> body { text-align: center; font-family: Arial, sans-serif; color: #333; background-color: #f5f5f5; } h1, h2 { color: #444; } table { margin: 0 auto; border-collapse: collapse; width: 80%; margin-top: 20px; } th, td { border: 1px solid #ddd; padding: 8px; text-align: center; } th { padding-top: 12px; padding-bottom: 12px; text-decoration: underline; color: black; } video { width: 40%; height: auto; margin-top: 20px; } /* search style */ .video-container { text-align: center; margin-bottom: 2em; padding: 1em; background-color: #fff; border: 1px solid #ddd; border-radius: 4px; box-shadow: 0 2px 4px rgba(0,0,0,0.1); } table { margin: 0 auto; margin-bottom: 1em; } th, td { padding: 0.5em; border: 1px solid #ddd; } </style> <script> function playVideo(timeString) { var timeParts = timeString.split(":"); var time = parseInt(timeParts[0]) * 60 + parseInt(timeParts[1]); var video = document.querySelector('#mainVideo'); video.currentTime = time; video.play(); } </script> </head> <body> <h1>Logo detection in the entire Video</h1> <h3>Video file: <i>{{ video_id_name_dict[video_id]}}</i></h3> <video id="mainVideo" controls> <source src="{{ url_for('static', filename=video_id_name_dict[video_id]|string) }}" type="video/mp4"> Your browser does not support the video tag. </video> <br /> <br /> <br /> <table> <tr> <th>Start</th> <th>End</th> <th>Value</th> </tr> {% for item in data %} <tr> <td><a href="javascript:void(0)" onclick="playVideo('{{ item['start'] }}')">{{ item['start'] }}</a></td> <td>{{ item['end'] }}</td> <td>{{ item['value'] }}</td> </tr> {% endfor %} </table> <br /> <br /> {% for video_id, results in video_search_dict.items() %} <div class="video-container"> <h1>Logo search results</h1> <h2>Video file: <i>{{ video_id_name_dict[video_id] }}</i></h2> <h2>Entered query: <i>{{input_query}}</i></h2> {% for result in results %} <video controls preload="metadata" style="width: 40%;"> <source src="{{ url_for('static', filename=video_id_name_dict[video_id]) }}#t={{ result['start'] }},{{ result['end'] }}" type="video/mp4"> Your browser does not support the video tag. </video> <table> <tr> <th>Start</th> <th>End</th> <th>Confidence</th> <th>Text</th> </tr> <tr> <td>{{ result['start'] }}</td> <td>{{ result['end'] }}</td> <td>{{ result['confidence'] }}</td> <td>{{ result['text'] }}</td> </tr> </table> {% endfor %} </div> {% endfor %} </body> </html> </code></pre>
<pre><code class="language-html"><!DOCTYPE html> <html> <head> <link rel="shortcut icon" href="#" /> <title>Logo Detection</title> <style> body { text-align: center; font-family: Arial, sans-serif; color: #333; background-color: #f5f5f5; } h1, h2 { color: #444; } table { margin: 0 auto; border-collapse: collapse; width: 80%; margin-top: 20px; } th, td { border: 1px solid #ddd; padding: 8px; text-align: center; } th { padding-top: 12px; padding-bottom: 12px; text-decoration: underline; color: black; } video { width: 40%; height: auto; margin-top: 20px; } /* search style */ .video-container { text-align: center; margin-bottom: 2em; padding: 1em; background-color: #fff; border: 1px solid #ddd; border-radius: 4px; box-shadow: 0 2px 4px rgba(0,0,0,0.1); } table { margin: 0 auto; margin-bottom: 1em; } th, td { padding: 0.5em; border: 1px solid #ddd; } </style> <script> function playVideo(timeString) { var timeParts = timeString.split(":"); var time = parseInt(timeParts[0]) * 60 + parseInt(timeParts[1]); var video = document.querySelector('#mainVideo'); video.currentTime = time; video.play(); } </script> </head> <body> <h1>Logo detection in the entire Video</h1> <h3>Video file: <i>{{ video_id_name_dict[video_id]}}</i></h3> <video id="mainVideo" controls> <source src="{{ url_for('static', filename=video_id_name_dict[video_id]|string) }}" type="video/mp4"> Your browser does not support the video tag. </video> <br /> <br /> <br /> <table> <tr> <th>Start</th> <th>End</th> <th>Value</th> </tr> {% for item in data %} <tr> <td><a href="javascript:void(0)" onclick="playVideo('{{ item['start'] }}')">{{ item['start'] }}</a></td> <td>{{ item['end'] }}</td> <td>{{ item['value'] }}</td> </tr> {% endfor %} </table> <br /> <br /> {% for video_id, results in video_search_dict.items() %} <div class="video-container"> <h1>Logo search results</h1> <h2>Video file: <i>{{ video_id_name_dict[video_id] }}</i></h2> <h2>Entered query: <i>{{input_query}}</i></h2> {% for result in results %} <video controls preload="metadata" style="width: 40%;"> <source src="{{ url_for('static', filename=video_id_name_dict[video_id]) }}#t={{ result['start'] }},{{ result['end'] }}" type="video/mp4"> Your browser does not support the video tag. </video> <table> <tr> <th>Start</th> <th>End</th> <th>Confidence</th> <th>Text</th> </tr> <tr> <td>{{ result['start'] }}</td> <td>{{ result['end'] }}</td> <td>{{ result['confidence'] }}</td> <td>{{ result['text'] }}</td> </tr> </table> {% endfor %} </div> {% endfor %} </body> </html> </code></pre>
Running the Flask app
Awesome! let’s just run the last cell of our Jupyter notebook to launch our Flask app:
<pre><code class="python">%run app.py </code></pre>
<pre><code class="python">%run app.py </code></pre>
You should see an output similar to the one below, confirming that everything went as anticipated 😊:

After clicking on the URL link http://127.0.0.1:5000, you should be greeted with the following web page:
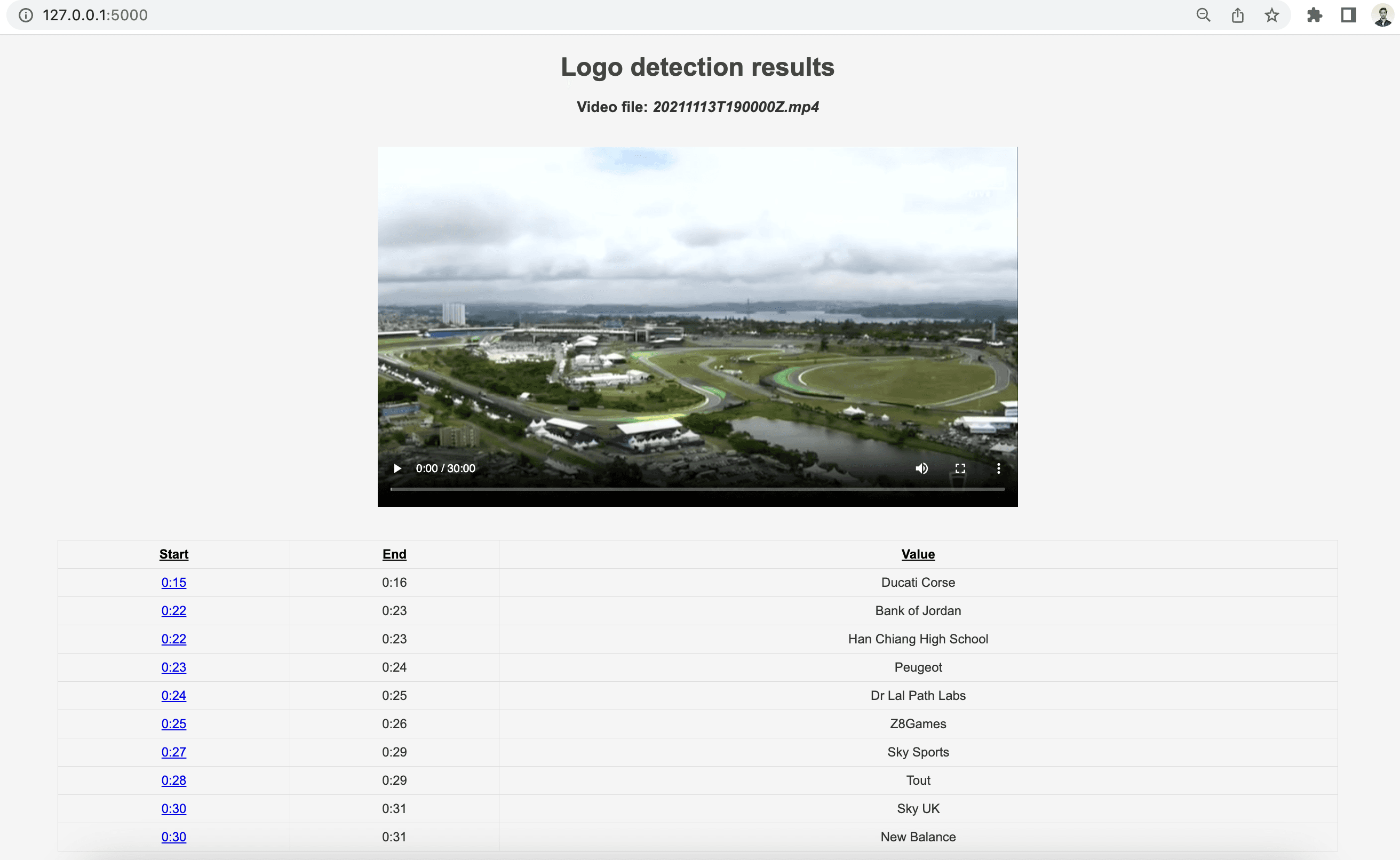
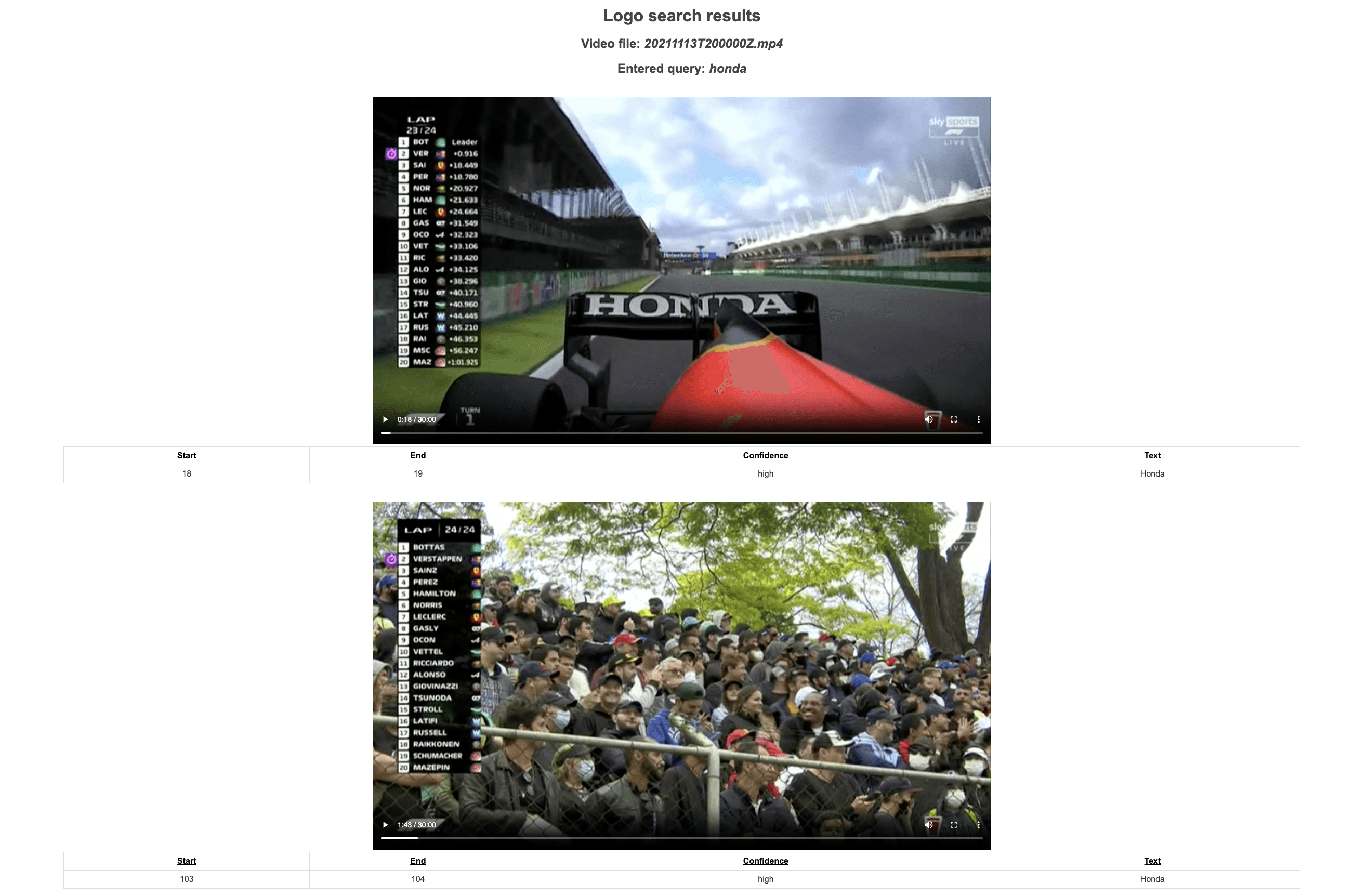
Here's the Jupyter Notebook containing the complete code that we've put together throughout this tutorial - https://drive.google.com/drive/folders/1D97_UU2Z0lvp3y52BHV5GKkSNOQKv3Xi?usp=share_link
Outro
Expect more exciting content coming your way! If you haven't already, I cordially invite you to join our vibrant Discord community, populated with individuals who share a passion for multimodal AI.
See you next time,
Ankit
Crafting stellar Developer Experiences @Twelve Labs
Cheers!
Introduction
Logo detection in videos refers to the automated process of identifying and recognizing logos or trademarks embedded within video content. This involves dissecting video frames or segments to detect and locate specific logo patterns or visual elements associated with a brand. This technology empowers us to quickly navigate through video content, accurately identifying the specific instances when certain logo patterns manifest on screen. Logo detection in videos refers to the automated process of identifying and recognizing logos or trademarks embedded within video content. This involves dissecting video frames or segments to detect and locate specific logo patterns or visual elements associated with a brand. This technology empowers us to quickly navigate through video content, accurately identifying the specific instances when certain logo patterns manifest on screen. Logo detection in video data can identify a wide range of elements, and thus, it has a broad array of applications across various industry verticals:
Advertising and marketing: Companies can monitor their brand presence and visibility across different media, both online and offline. It helps in assessing the impact of marketing campaigns, identifying unauthorized use of logos, and understanding competitors' marketing strategies.
Social media monitoring: Logo detection helps brands understand where and how often their logo appears in user-generated content. It can provide insights into brand popularity, usage context, and sentiment analysis.
Retail and e-commerce: Retailers can use logo detection to monitor and manage their inventory. For example, it can help identify counterfeit products or unauthorized sellers.
Sports sponsorship: Logo detection can quantify brand exposure during live broadcasts of sports events. It can provide insights into the value delivered to sponsors and advertisers.
Media and entertainment: In the entertainment industry, logo detection can be used to track product placements in movies and TV shows. It can also identify copyright infringements.
Security and surveillance: Logo detection can aid in identifying and tracking vehicles or objects based on company logos for security purposes.
Automotive: In the automotive industry, logo detection can help identify car makes and models, aiding in traffic analysis, parking management, or autonomous driving systems.
In this tutorial, we're going to delve into the world of logo detection from two distinct perspectives and levels. The first one is at the video level, where we tackle the entire video content as a single entity, seeking to unearth every bit of logo information it contains. The second approach, the index level, narrows our lens to concentrate on a specific logo or a group of logos. We'll employ natural language queries to conduct an exhaustive search across a rich library of videos indexed on the Twelve Labs platform.
Here's the best part – with Twelve Labs API at your fingertips, you can achieve all of this without getting bogged down in the intricacies of model training, deployment, inference, or load scaling that make up the detection process. We've got you covered from development to infrastructure, and even provide continuous support. So, buckle up and join us on this fascinating journey into the domain of logo detection.
Text-in-video vs Logo detection - potential overlap
There may be instances where a logo is simply the name of a brand or company, leading to questions about whether it could be treated as text on screen, and if text-in-video indexing and search options might suffice for logo detection. It's true that such text will be detected as it appears on screen during video playback. However, in cases where text might have different meanings in different contexts, specifically configuring the indexing and search options to detect logos is key.
For instance, 'Amazon' could refer to the multinational technology company or the South American river. If you employ logo detection, the system will differentiate between searches for Amazon's brand logo and the text 'Amazon'. Hence, even though text-in-video and logo detection may seemingly overlap in cases where the brand logo is text-based, choosing to use the logo detection feature should be intentional to ensure accurate results.
Prerequisites
The Twelve Labs platform is presently in open beta, and we are offering free video indexing credits for up to 10 hours upon sign-up. I'd recommend familiarizing yourself with the core aspects of the Twelve Labs platform prior to embarking on this tutorial. A solid understanding of concepts such as video indexing, indexing options, the Task API, and search options is essential to seamlessly navigate through this tutorial. I've covered these topics in depth in my first tutorial. Nonetheless, if you encounter any obstacles or find yourself stuck at any point, please feel free to reach out. I'm here to assist you on this exciting journey into the realm of logo detection. Additionally, our response times on our Discord server are lightning fast 🚅🏎️⚡️ if Discord is your preferred platform.
A Quick Guide to the Tutorial
In continuation with our previous discussion, we'll delve into logo detection from two distinct perspectives and levels. I've segmented this tutorial into two crucial sections, culminating in a final demonstration where we amalgamate all elements into a fully functional web-app:
Logo Detection in Three Easy Steps
The extraction of recognized logos from a specific video involves the following three steps:
Video indexing - There should be no surprises here; if you've been keeping up with my previous tutorials, this step will feel like second nature.
Retrieving the unique identifier of the video - Once the Twelve Labs platform completes the indexing of our video, we will fetch the unique identifier of the video we need the logo detection for.
Extracting the logos appearing on screen - We'll zero in on the video by utilizing the specific index we've created and the video id associated with the video we need logo detection for. The API will shoulder the heavy lifting, delivering the results we're seeking.
Logo Search - searching for specific logo(s) within all indexed videos
Applying logo detection on the entire video enabled us to scrutinize and distill it for all instances of logo pattern(s). Now, the logo search feature empowers us to zero in on precise moments or video snippets where the input or searched logo or brand name materializes. This greatly diminishes the time spent perusing a sizable catalogue of videos, yielding accurate search results predicated on alignment of search terms with the logo that becomes visible on screen during video playbacks.
In our earlier tutorials, we delved into content search within indexed videos, utilizing natural language queries and a variety of search options like visual (audio-visual search), conversation (dialogue search), and text-in-video (OCR). In this tutorial, we'll pivot our approach, harnessing exclusively the logo detection pipeline to search for logo(s) within indexed videos. To maximize processing efficiency and minimize costs, we'll establish an index using solely the 'logo' indexing option. Subsequently, we'll trigger our search query with the 'logo' search option, thereby enabling us to uncover relevant logo matches within the indexed videos.
Building the Demo App
To tie everything together, we will utilize the data generated by the API endpoints and present them on a webpage, spinning up a demo app based on Flask that hosts a minimalistic HTML page. The outcome of the logo detection process will be systematically tabulated, exhibiting timestamps and their corresponding logo names. The logo search section, on the other hand, will display the query we used and the relevant video segments we discovered in response.
Detecting logos in three simple steps
For the sake of simplicity, I've uploaded just five videos to an index using a pre-existing account. Feel free to sign up; given we're currently in open beta, you'll receive complimentary credits allowing you to index up to 10 hours of video content. If your needs extend beyond that, check out our pricing page for upgrading to the Developer plan.
Video Indexing
Here, we’re going to delve into the essential elements that we'll need to include in our Jupyter notebook. This includes the necessary imports, defining API URLs, creating the index, and uploading videos from our local file system to kick off the indexing process:
<pre><code class="python">%env API_URL = https://api.twelvelabs.io/v1.1 %env API_KEY= <your API key> !pip install requests import os import requests import glob from pprint import pprint # Retrieve the URL of the API and my API key API_URL = os.getenv("API_URL") assert API_URL API_KEY = os.getenv("API_KEY") assert API_KEY </code></pre>
<pre><code class="python"># Construct the URL of the `/indexes` endpoint INDEXES_URL = f"{API_URL}/indexes" # Set the header of the request default_header = { "x-api-key": API_KEY } # Define a function to create an index with a given name def create_index(index_name, index_options, engine): # Declare a dictionary named data data = { "engine_id": engine, "index_options": index_options, "index_name": index_name, } # Create an index response = requests.post(INDEXES_URL, headers=default_header, json=data) # Store the unique identifier of your index INDEX_ID = response.json().get('_id') # Check if the status code is 201 and print success if response.status_code == 201: print(f"Status code: {response.status_code} - The request was successful and a new index was created.") else: print(f"Status code: {response.status_code}") pprint(response.json()) return INDEX_ID # Create the indexes index_id = create_index(index_name = "extract_text", index_options=["logo"], engine = "marengo2.5") # Print the created index IDs print(f"Created index IDs: {index_id}") </code></pre>
Uploading five formula one race videos to the index we've just created. I have downloaded these videos from their some formula one related YouTube channels and saved them in a folder named 'static' on my local hard drive. We'll use these local files to index the videos onto the Twelve Labs platform:
<pre><code class="python">import os import requests from concurrent.futures import ThreadPoolExecutor TASKS_URL = f"{API_URL}/tasks" TASK_ID_LIST = [] video_folder = 'static' # folder containing the video files def upload_video(file_name): # Validate if a video already exists in the index task_list_response = requests.get( TASKS_URL, headers=default_header, params={"index_id": INDEX_ID, "filename": file_name}, ) if "data" in task_list_response.json(): task_list = task_list_response.json()["data"] if len(task_list) > 0: if task_list[0]['status'] == 'ready': print(f"Video '{file_name}' already exists in index {INDEX_ID}") else: print("task pending or validating") return # Proceed further to create a new task to index the current video if the video didn't exist in the index already print("Entering task creation code for the file: ", file_name) if file_name.endswith('.mp4'): # Make sure the file is an MP4 video file_path = os.path.join(video_folder, file_name) # Get the full path of the video file with open(file_path, "rb") as file_stream: data = { "index_id": INDEX_ID, "language": "en" } file_param = [ ("video_file", (file_name, file_stream, "application/octet-stream")),] #The video will be indexed on the platform using the same name as the video file itself. response = requests.post(TASKS_URL, headers=default_header, data=data, files=file_param) TASK_ID = response.json().get("_id") TASK_ID_LIST.append(TASK_ID) # Check if the status code is 201 and print success if response.status_code == 201: print(f"Status code: {response.status_code} - The request was successful and a new resource was created.") else: print(f"Status code: {response.status_code}") print(f"File name: {file_name}") pprint(response.json()) print("\n") # Get list of video files video_files = [f for f in os.listdir(video_folder) if f.endswith('.mp4')] # Create a ThreadPoolExecutor with ThreadPoolExecutor() as executor: # Use executor to run upload_video in parallel for all video files executor.map(upload_video, video_files) </code></pre>
Retrieving the unique identifier of the video
Now let's enumerate all the videos in our index. This allows us to retain the video ID of a specific video, the goal being to extract all the text embedded within it. Furthermore, akin to our methods in prior tutorials, I'm assembling a list of video IDs and their respective titles, designed to be subsequently fed into our Flask application.
<pre><code class="python"># List all the videos in an index default_header = { "x-api-key": API_KEY } INDEX_ID='##4a73aa8b1dd6cde172a9##' INDEXES_VIDEOS_URL = f"{API_URL}/indexes/{INDEX_ID}/videos" response = requests.get(INDEXES_VIDEOS_URL, headers=default_header) response_json = response.json() pprint(response_json) video_id_name_list = [{'video_id': video['_id'], 'video_name': video['metadata']['filename']} for video in response_json['data']] pprint(video_id_name_list) </code></pre>
Output:
<pre><code class="python">{'data': [{'_id': '##d978c86daab572f3481##', 'created_at': '2023-04-17T18:56:51Z', 'metadata': {'duration': 1800.56, 'engine_id': 'marengo2.5', 'filename': '20211113T190000Z.mp4', 'fps': 25, 'height': 396, 'size': 415876158, 'width': 704}, 'updated_at': '2023-04-17T19:01:32Z'}, {'_id': '##3d975786daab572f3481##', 'created_at': '2023-04-17T18:56:44Z', 'metadata': {'duration': 1800.56, 'engine_id': 'marengo2.5', 'filename': '20211114T170000Z.mp4', 'fps': 25, 'height': 396, 'size': 387273943, 'width': 704}, 'updated_at': '2023-04-17T19:00:39Z'}, {'_id': '##3d972e86daab572f3481##', 'created_at': '2023-04-17T18:56:38Z', 'metadata': {'duration': 1800.56, 'engine_id': 'marengo2.5', 'filename': '20211113T193000Z.mp4', 'fps': 25, 'height': 396, 'size': 386209689, 'width': 704}, 'updated_at': '2023-04-17T18:59:58Z'}, {'_id': '##3d96d386daab572f3481##', 'created_at': '2023-04-17T18:56:28Z', 'metadata': {'duration': 1800.52, 'engine_id': 'marengo2.5', 'filename': '20211121T133000Z.mp4', 'fps': 25, 'height': 396, 'size': 348611416, 'width': 704}, 'updated_at': '2023-04-17T18:58:27Z'}, {'_id': '##3d96af86daab572f3481##', 'created_at': '2023-04-17T18:56:08Z', 'metadata': {'duration': 1800.56, 'engine_id': 'marengo2.5', 'filename': '20211113T200000Z.mp4', 'fps': 25, 'height': 396, 'size': 327766175, 'width': 704}, 'updated_at': '2023-04-17T18:57:51Z'}], 'page_info': {'limit_per_page': 10, 'page': 1, 'total_duration': 9002.76, 'total_page': 1, 'total_results': 5}} [{'video_id': '##3d978c86daab572f3481##', 'video_name': '20211113T190000Z.mp4'}, {'video_id': '##3d975786daab572f3481##', 'video_name': '20211114T170000Z.mp4'}, {'video_id': '##3d972e86daab572f3481##', 'video_name': '20211113T193000Z.mp4'}, {'video_id': '##3d96d386daab572f3481##', 'video_name': '20211121T133000Z.mp4'}, {'video_id': '##3d96af86daab572f3481##', 'video_name': '20211113T200000Z.mp4'}] </code></pre>
Extracting the logo appearing on screen
Time to put our plan into action! We'll now proceed to extract all logo content from the chosen video:
<pre><code class="python">VIDEO_ID = '###a849b86daab572f349242' LOGO_URL = f"{API_URL}/indexes/{INDEX_ID}/videos/{VIDEO_ID}/logo" response = requests.get(LOGO_URL, headers=default_header) print (f"Status code: {response.status_code}") logo_data = response.json() pprint (logo_data) </code></pre>
Output:
<pre><code class="python">Status code: 200 {'data': [{'end': 16, 'start': 15, 'value': 'Ducati Corse'}, {'end': 23, 'start': 22, 'value': 'Bank of Jordan'}, {'end': 23, 'start': 22, 'value': 'Han Chiang High School'}, {'end': 24, 'start': 23, 'value': 'Peugeot'}, {'end': 25, 'start': 24, 'value': 'Dr Lal Path Labs'}, {'end': 26, 'start': 25, 'value': 'Z8Games'}, {'end': 29, 'start': 27, 'value': 'Sky Sports'}, {'end': 29, 'start': 28, 'value': 'Tout'}, {'end': 31, 'start': 30, 'value': 'Sky UK'}, {'end': 31, 'start': 30, 'value': 'New Balance'}, {'end': 31, 'start': 30, 'value': 'Industria'}, {'end': 33, 'start': 32, 'value': 'Esport3'}, {'end': 35, 'start': 32, 'value': 'Nissan'}, {'end': 33, 'start': 32, 'value': 'GoCar'}, {'end': 34, 'start': 33, 'value': 'Land Bank of the Philippines'}, {'end': 34, 'start': 33, 'value': 'Z8Games'}, {'end': 37, 'start': 36, 'value': 'Tout'}, {'end': 37, 'start': 36, 'value': 'Zazzle'}, {'end': 39, 'start': 38, 'value': 'Z8Games'}, {'end': 39, 'start': 38, 'value': 'Giochi Preziosi'}, {'end': 41, 'start': 40, 'value': 'Mini'}], 'id': '###a849b86daab572f349242', 'index_id': '###a73aa8b1dd6cde172a933'} </code></pre>
Clearly, the API skillfully extracted all the on-screen logos line by line. This information can be stored as metadata for subsequent workflows, including content filtering, classification, and search purposes. Please note that the output displayed here is abbreviated for conciseness - the actual output was considerably more extensive.
Logo Search - searching for specific logo(s) within all indexed videos
Launching our search query utilizing the logo search option to uncover pertinent logo pattern matches within our collection of indexed videos:
<pre><code class="python"># Construct the URL of the `/search` endpoint SEARCH_URL = f"{API_URL}/search/" # Declare a dictionary named `data` data = { "index_id": INDEX_ID, "query": "honda", "search_options": [ "logo" ] } # Extracting query to later pass it to flask application input_query = data["query"] # Make a search request response = requests.post(SEARCH_URL, headers=default_header, json=data) if response.status_code == 200: print(f"Status code: {response.status_code} - Success") else: print(f"Status code: {response.status_code}") pprint(response.json()) </code></pre>
Output:
<pre><code class="python">Status code: 200 - Success {'data': [{'confidence': 'high', 'end': 19, 'metadata': [{'text': 'Honda', 'type': 'logo'}], 'score': 92.28, 'start': 18, 'video_id': '###d96af86daab572f348###'}, {'confidence': 'high', 'end': 104, 'metadata': [{'text': 'Honda', 'type': 'logo'}], 'score': 92.28, 'start': 103, 'video_id': '###d978c86daab572f348###'}, {'confidence': 'high', 'end': 137, 'metadata': [{'text': 'Honda', 'type': 'logo'}], 'score': 92.28, 'start': 136, 'video_id': '###d978c86daab572f348###'}, {'confidence': 'high', 'end': 269, 'metadata': [{'text': 'Honda', 'type': 'logo'}], 'score': 92.28, 'start': 268, 'video_id': '###d96af86daab572f348###'}, {'confidence': 'high', 'end': 392, 'metadata': [{'text': 'Honda', 'type': 'logo'}], 'score': 92.28, 'start': 391, 'video_id': '###d96af86daab572f348###'}, {'confidence': 'high', 'end': 478, 'metadata': [{'text': 'Honda', 'type': 'logo'}], 'score': 92.28, 'start': 477, 'video_id': '###d975786daab572f348###'}, {'confidence': 'high', 'end': 483, 'metadata': [{'text': 'Honda', 'type': 'logo'}], 'score': 92.28, 'start': 482, 'video_id': '###d978c86daab572f348###'}], 'page_info': {'limit_per_page': 10, 'next_page_token': 'fc3c420a-5971-428a-8796-9e5c077754c0-1', 'page_expired_at': '2023-05-26T18:40:26Z', 'total_results': 47}, 'search_pool': {'index_id': '###d9556f607a5a7bd9ea###', 'total_count': 5, 'total_duration': 9003}} </code></pre>
Once more, the API proficiently scoured and retrieved all on-screen logos corresponding to the input logo name, but this time across the entire index of videos we've uploaded.
Preparing the data for the Flask application to ensure our results will be presented neatly:
<pre><code class="python">video_data = [{'start': d['start'], 'end': d['end'], 'confidence': d['confidence'], 'text': d['metadata'][0]['text']} for d in search_data['data']] video_search_dict = {} for vd in video_data: if search_data['data'][0]['video_id'] in video_search_dict: video_search_dict[search_data['data'][0]['video_id']].append(vd) else: video_search_dict[search_data['data'][0]['video_id']] = [vd] pprint(video_search_dict) </code></pre>
Output:
<pre><code class="python"> {'###d96af86daab572f348###': [{'confidence': 'high', 'end': 19, 'start': 18, 'text': 'Honda'}, {'confidence': 'high', 'end': 104, 'start': 103, 'text': 'Honda'}, {'confidence': 'high', 'end': 137, 'start': 136, 'text': 'Honda'}, {'confidence': 'high', 'end': 269, 'start': 268, 'text': 'Honda'}, {'confidence': 'high', 'end': 392, 'start': 391, 'text': 'Honda'}, {'confidence': 'high', 'end': 478, 'start': 477, 'text': 'Honda'}, {'confidence': 'high', 'end': 483, 'start': 482, 'text': 'Honda'}, {'confidence': 'high', 'end': 491, 'start': 487, 'text': 'Honda'}, {'confidence': 'high', 'end': 561, 'start': 560, 'text': 'Honda'}, {'confidence': 'high', 'end': 586, 'start': 585, 'text': 'Honda'}]} </code></pre>
Further data preparation for the logo detection results, followed by our standard procedure of pickling everything:
<pre><code class="python">video_id = ocr_data.get('id') data_list = logo_data.get('data') data_to_save = { 'video_id': video_id, 'data_list': data_list, 'video_id_name_list': video_id_name_list, 'video_search_dict': video_search_dict } import pickle # Save data to a pickle file with open('data.pkl', 'wb') as f: pickle.dump(data_to_save, f) </code></pre>
Building the Demo App
Now we've reached the last stretch of our current journey – integrating everything to make our outputs come to life. Besides the standard configuration we implement for fetching videos from the local folder and loading the pickled data dispatched from the Jupyter notebook, this time we have some additional requirements - a conversion of timestamps from a seconds-only format to a minutes-and-seconds format. This makes the data visualization on the webpage more intuitive. Here's the code for the app.py file:
<pre><code class="python">from flask import Flask, render_template, send_from_directory import pickle import os from collections import defaultdict app = Flask(__name__) # Load data from a pickle file with open('data.pkl', 'rb') as f: loaded_data = pickle.load(f) # Access the data video_id = loaded_data['video_id'] data_list = loaded_data['data_list'] video_id_name_list = loaded_data['video_id_name_list'] video_search_dict = loaded_data['video_search_dict'] VIDEO_DIRECTORY = os.path.join(os.path.dirname(os.path.realpath(__file__)), "static") @app.route('/<path:filename>') def serve_video(filename): print(VIDEO_DIRECTORY, filename) return send_from_directory(directory=VIDEO_DIRECTORY, path=filename) @app.route('/') def home(): for item in data_list: if ":" not in str(item['start']): item['start'] = int(item['start']) item['start'] = f"{item['start'] // 60}:{item['start'] % 60:02}" if ":" not in str(item['end']): item['end'] = int(item['end']) item['end'] = f"{item['end'] // 60}:{item['end'] % 60:02}" video_id_name_dict = {video['video_id']: video['video_name'] for video in video_id_name_list} # video_name = video_id_name_dict.get(video_id) return render_template('index.html', data=data_list[:10], video_id_name_dict=video_id_name_dict, video_id=video_id, video_search_dict = video_search_dict) if __name__ == '__main__': app.run(debug=True) </code></pre>
HTML Template
Now, it's time to weave together the final piece: our Jinja-2 based HTML template code. This pulls together all the data we've transmitted through the Flask app.py file. We'll kick things off by showcasing the logo detection results. The video player will cover the entire duration of the video, and just below it, a table will display the start, end, and text identified during that specific duration on the screen. To improve clarity, timestamps will be formatted in minutes-and-seconds and will be interactive, allowing us to jump to the exact timestamp and commence video playback from there. Keep in mind, I've converted the timestamps back to seconds when passing them to the JavaScript function playVideo, as this function is designed to accept timestamps in a seconds-only format for video playback.
<pre><code class="language-html"><!DOCTYPE html> <html> <head> <link rel="shortcut icon" href="#" /> <title>Logo Detection</title> <style> body { text-align: center; font-family: Arial, sans-serif; color: #333; background-color: #f5f5f5; } h1, h2 { color: #444; } table { margin: 0 auto; border-collapse: collapse; width: 80%; margin-top: 20px; } th, td { border: 1px solid #ddd; padding: 8px; text-align: center; } th { padding-top: 12px; padding-bottom: 12px; text-decoration: underline; color: black; } video { width: 40%; height: auto; margin-top: 20px; } /* search style */ .video-container { text-align: center; margin-bottom: 2em; padding: 1em; background-color: #fff; border: 1px solid #ddd; border-radius: 4px; box-shadow: 0 2px 4px rgba(0,0,0,0.1); } table { margin: 0 auto; margin-bottom: 1em; } th, td { padding: 0.5em; border: 1px solid #ddd; } </style> <script> function playVideo(timeString) { var timeParts = timeString.split(":"); var time = parseInt(timeParts[0]) * 60 + parseInt(timeParts[1]); var video = document.querySelector('#mainVideo'); video.currentTime = time; video.play(); } </script> </head> <body> <h1>Logo detection in the entire Video</h1> <h3>Video file: <i>{{ video_id_name_dict[video_id]}}</i></h3> <video id="mainVideo" controls> <source src="{{ url_for('static', filename=video_id_name_dict[video_id]|string) }}" type="video/mp4"> Your browser does not support the video tag. </video> <br /> <br /> <br /> <table> <tr> <th>Start</th> <th>End</th> <th>Value</th> </tr> {% for item in data %} <tr> <td><a href="javascript:void(0)" onclick="playVideo('{{ item['start'] }}')">{{ item['start'] }}</a></td> <td>{{ item['end'] }}</td> <td>{{ item['value'] }}</td> </tr> {% endfor %} </table> <br /> <br /> {% for video_id, results in video_search_dict.items() %} <div class="video-container"> <h1>Logo search results</h1> <h2>Video file: <i>{{ video_id_name_dict[video_id] }}</i></h2> <h2>Entered query: <i>{{input_query}}</i></h2> {% for result in results %} <video controls preload="metadata" style="width: 40%;"> <source src="{{ url_for('static', filename=video_id_name_dict[video_id]) }}#t={{ result['start'] }},{{ result['end'] }}" type="video/mp4"> Your browser does not support the video tag. </video> <table> <tr> <th>Start</th> <th>End</th> <th>Confidence</th> <th>Text</th> </tr> <tr> <td>{{ result['start'] }}</td> <td>{{ result['end'] }}</td> <td>{{ result['confidence'] }}</td> <td>{{ result['text'] }}</td> </tr> </table> {% endfor %} </div> {% endfor %} </body> </html> </code></pre>
Running the Flask app
Awesome! let’s just run the last cell of our Jupyter notebook to launch our Flask app:
<pre><code class="python">%run app.py </code></pre>
You should see an output similar to the one below, confirming that everything went as anticipated 😊:
After clicking on the URL link http://127.0.0.1:5000, you should be greeted with the following web page:
Here's the Jupyter Notebook containing the complete code that we've put together throughout this tutorial - https://drive.google.com/drive/folders/1D97_UU2Z0lvp3y52BHV5GKkSNOQKv3Xi?usp=share_link
Outro
Expect more exciting content coming your way! If you haven't already, I cordially invite you to join our vibrant Discord community, populated with individuals who share a passion for multimodal AI.
See you next time,
Ankit
Crafting stellar Developer Experiences @Twelve Labs
Cheers!
Introduction
Logo detection in videos refers to the automated process of identifying and recognizing logos or trademarks embedded within video content. This involves dissecting video frames or segments to detect and locate specific logo patterns or visual elements associated with a brand. This technology empowers us to quickly navigate through video content, accurately identifying the specific instances when certain logo patterns manifest on screen. Logo detection in videos refers to the automated process of identifying and recognizing logos or trademarks embedded within video content. This involves dissecting video frames or segments to detect and locate specific logo patterns or visual elements associated with a brand. This technology empowers us to quickly navigate through video content, accurately identifying the specific instances when certain logo patterns manifest on screen. Logo detection in video data can identify a wide range of elements, and thus, it has a broad array of applications across various industry verticals:
Advertising and marketing: Companies can monitor their brand presence and visibility across different media, both online and offline. It helps in assessing the impact of marketing campaigns, identifying unauthorized use of logos, and understanding competitors' marketing strategies.
Social media monitoring: Logo detection helps brands understand where and how often their logo appears in user-generated content. It can provide insights into brand popularity, usage context, and sentiment analysis.
Retail and e-commerce: Retailers can use logo detection to monitor and manage their inventory. For example, it can help identify counterfeit products or unauthorized sellers.
Sports sponsorship: Logo detection can quantify brand exposure during live broadcasts of sports events. It can provide insights into the value delivered to sponsors and advertisers.
Media and entertainment: In the entertainment industry, logo detection can be used to track product placements in movies and TV shows. It can also identify copyright infringements.
Security and surveillance: Logo detection can aid in identifying and tracking vehicles or objects based on company logos for security purposes.
Automotive: In the automotive industry, logo detection can help identify car makes and models, aiding in traffic analysis, parking management, or autonomous driving systems.
In this tutorial, we're going to delve into the world of logo detection from two distinct perspectives and levels. The first one is at the video level, where we tackle the entire video content as a single entity, seeking to unearth every bit of logo information it contains. The second approach, the index level, narrows our lens to concentrate on a specific logo or a group of logos. We'll employ natural language queries to conduct an exhaustive search across a rich library of videos indexed on the Twelve Labs platform.
Here's the best part – with Twelve Labs API at your fingertips, you can achieve all of this without getting bogged down in the intricacies of model training, deployment, inference, or load scaling that make up the detection process. We've got you covered from development to infrastructure, and even provide continuous support. So, buckle up and join us on this fascinating journey into the domain of logo detection.
Text-in-video vs Logo detection - potential overlap
There may be instances where a logo is simply the name of a brand or company, leading to questions about whether it could be treated as text on screen, and if text-in-video indexing and search options might suffice for logo detection. It's true that such text will be detected as it appears on screen during video playback. However, in cases where text might have different meanings in different contexts, specifically configuring the indexing and search options to detect logos is key.
For instance, 'Amazon' could refer to the multinational technology company or the South American river. If you employ logo detection, the system will differentiate between searches for Amazon's brand logo and the text 'Amazon'. Hence, even though text-in-video and logo detection may seemingly overlap in cases where the brand logo is text-based, choosing to use the logo detection feature should be intentional to ensure accurate results.
Prerequisites
The Twelve Labs platform is presently in open beta, and we are offering free video indexing credits for up to 10 hours upon sign-up. I'd recommend familiarizing yourself with the core aspects of the Twelve Labs platform prior to embarking on this tutorial. A solid understanding of concepts such as video indexing, indexing options, the Task API, and search options is essential to seamlessly navigate through this tutorial. I've covered these topics in depth in my first tutorial. Nonetheless, if you encounter any obstacles or find yourself stuck at any point, please feel free to reach out. I'm here to assist you on this exciting journey into the realm of logo detection. Additionally, our response times on our Discord server are lightning fast 🚅🏎️⚡️ if Discord is your preferred platform.
A Quick Guide to the Tutorial
In continuation with our previous discussion, we'll delve into logo detection from two distinct perspectives and levels. I've segmented this tutorial into two crucial sections, culminating in a final demonstration where we amalgamate all elements into a fully functional web-app:
Logo Detection in Three Easy Steps
The extraction of recognized logos from a specific video involves the following three steps:
Video indexing - There should be no surprises here; if you've been keeping up with my previous tutorials, this step will feel like second nature.
Retrieving the unique identifier of the video - Once the Twelve Labs platform completes the indexing of our video, we will fetch the unique identifier of the video we need the logo detection for.
Extracting the logos appearing on screen - We'll zero in on the video by utilizing the specific index we've created and the video id associated with the video we need logo detection for. The API will shoulder the heavy lifting, delivering the results we're seeking.
Logo Search - searching for specific logo(s) within all indexed videos
Applying logo detection on the entire video enabled us to scrutinize and distill it for all instances of logo pattern(s). Now, the logo search feature empowers us to zero in on precise moments or video snippets where the input or searched logo or brand name materializes. This greatly diminishes the time spent perusing a sizable catalogue of videos, yielding accurate search results predicated on alignment of search terms with the logo that becomes visible on screen during video playbacks.
In our earlier tutorials, we delved into content search within indexed videos, utilizing natural language queries and a variety of search options like visual (audio-visual search), conversation (dialogue search), and text-in-video (OCR). In this tutorial, we'll pivot our approach, harnessing exclusively the logo detection pipeline to search for logo(s) within indexed videos. To maximize processing efficiency and minimize costs, we'll establish an index using solely the 'logo' indexing option. Subsequently, we'll trigger our search query with the 'logo' search option, thereby enabling us to uncover relevant logo matches within the indexed videos.
Building the Demo App
To tie everything together, we will utilize the data generated by the API endpoints and present them on a webpage, spinning up a demo app based on Flask that hosts a minimalistic HTML page. The outcome of the logo detection process will be systematically tabulated, exhibiting timestamps and their corresponding logo names. The logo search section, on the other hand, will display the query we used and the relevant video segments we discovered in response.
Detecting logos in three simple steps
For the sake of simplicity, I've uploaded just five videos to an index using a pre-existing account. Feel free to sign up; given we're currently in open beta, you'll receive complimentary credits allowing you to index up to 10 hours of video content. If your needs extend beyond that, check out our pricing page for upgrading to the Developer plan.
Video Indexing
Here, we’re going to delve into the essential elements that we'll need to include in our Jupyter notebook. This includes the necessary imports, defining API URLs, creating the index, and uploading videos from our local file system to kick off the indexing process:
<pre><code class="python">%env API_URL = https://api.twelvelabs.io/v1.1 %env API_KEY= <your API key> !pip install requests import os import requests import glob from pprint import pprint # Retrieve the URL of the API and my API key API_URL = os.getenv("API_URL") assert API_URL API_KEY = os.getenv("API_KEY") assert API_KEY </code></pre>
<pre><code class="python"># Construct the URL of the `/indexes` endpoint INDEXES_URL = f"{API_URL}/indexes" # Set the header of the request default_header = { "x-api-key": API_KEY } # Define a function to create an index with a given name def create_index(index_name, index_options, engine): # Declare a dictionary named data data = { "engine_id": engine, "index_options": index_options, "index_name": index_name, } # Create an index response = requests.post(INDEXES_URL, headers=default_header, json=data) # Store the unique identifier of your index INDEX_ID = response.json().get('_id') # Check if the status code is 201 and print success if response.status_code == 201: print(f"Status code: {response.status_code} - The request was successful and a new index was created.") else: print(f"Status code: {response.status_code}") pprint(response.json()) return INDEX_ID # Create the indexes index_id = create_index(index_name = "extract_text", index_options=["logo"], engine = "marengo2.5") # Print the created index IDs print(f"Created index IDs: {index_id}") </code></pre>
Uploading five formula one race videos to the index we've just created. I have downloaded these videos from their some formula one related YouTube channels and saved them in a folder named 'static' on my local hard drive. We'll use these local files to index the videos onto the Twelve Labs platform:
<pre><code class="python">import os import requests from concurrent.futures import ThreadPoolExecutor TASKS_URL = f"{API_URL}/tasks" TASK_ID_LIST = [] video_folder = 'static' # folder containing the video files def upload_video(file_name): # Validate if a video already exists in the index task_list_response = requests.get( TASKS_URL, headers=default_header, params={"index_id": INDEX_ID, "filename": file_name}, ) if "data" in task_list_response.json(): task_list = task_list_response.json()["data"] if len(task_list) > 0: if task_list[0]['status'] == 'ready': print(f"Video '{file_name}' already exists in index {INDEX_ID}") else: print("task pending or validating") return # Proceed further to create a new task to index the current video if the video didn't exist in the index already print("Entering task creation code for the file: ", file_name) if file_name.endswith('.mp4'): # Make sure the file is an MP4 video file_path = os.path.join(video_folder, file_name) # Get the full path of the video file with open(file_path, "rb") as file_stream: data = { "index_id": INDEX_ID, "language": "en" } file_param = [ ("video_file", (file_name, file_stream, "application/octet-stream")),] #The video will be indexed on the platform using the same name as the video file itself. response = requests.post(TASKS_URL, headers=default_header, data=data, files=file_param) TASK_ID = response.json().get("_id") TASK_ID_LIST.append(TASK_ID) # Check if the status code is 201 and print success if response.status_code == 201: print(f"Status code: {response.status_code} - The request was successful and a new resource was created.") else: print(f"Status code: {response.status_code}") print(f"File name: {file_name}") pprint(response.json()) print("\n") # Get list of video files video_files = [f for f in os.listdir(video_folder) if f.endswith('.mp4')] # Create a ThreadPoolExecutor with ThreadPoolExecutor() as executor: # Use executor to run upload_video in parallel for all video files executor.map(upload_video, video_files) </code></pre>
Retrieving the unique identifier of the video
Now let's enumerate all the videos in our index. This allows us to retain the video ID of a specific video, the goal being to extract all the text embedded within it. Furthermore, akin to our methods in prior tutorials, I'm assembling a list of video IDs and their respective titles, designed to be subsequently fed into our Flask application.
<pre><code class="python"># List all the videos in an index default_header = { "x-api-key": API_KEY } INDEX_ID='##4a73aa8b1dd6cde172a9##' INDEXES_VIDEOS_URL = f"{API_URL}/indexes/{INDEX_ID}/videos" response = requests.get(INDEXES_VIDEOS_URL, headers=default_header) response_json = response.json() pprint(response_json) video_id_name_list = [{'video_id': video['_id'], 'video_name': video['metadata']['filename']} for video in response_json['data']] pprint(video_id_name_list) </code></pre>
Output:
<pre><code class="python">{'data': [{'_id': '##d978c86daab572f3481##', 'created_at': '2023-04-17T18:56:51Z', 'metadata': {'duration': 1800.56, 'engine_id': 'marengo2.5', 'filename': '20211113T190000Z.mp4', 'fps': 25, 'height': 396, 'size': 415876158, 'width': 704}, 'updated_at': '2023-04-17T19:01:32Z'}, {'_id': '##3d975786daab572f3481##', 'created_at': '2023-04-17T18:56:44Z', 'metadata': {'duration': 1800.56, 'engine_id': 'marengo2.5', 'filename': '20211114T170000Z.mp4', 'fps': 25, 'height': 396, 'size': 387273943, 'width': 704}, 'updated_at': '2023-04-17T19:00:39Z'}, {'_id': '##3d972e86daab572f3481##', 'created_at': '2023-04-17T18:56:38Z', 'metadata': {'duration': 1800.56, 'engine_id': 'marengo2.5', 'filename': '20211113T193000Z.mp4', 'fps': 25, 'height': 396, 'size': 386209689, 'width': 704}, 'updated_at': '2023-04-17T18:59:58Z'}, {'_id': '##3d96d386daab572f3481##', 'created_at': '2023-04-17T18:56:28Z', 'metadata': {'duration': 1800.52, 'engine_id': 'marengo2.5', 'filename': '20211121T133000Z.mp4', 'fps': 25, 'height': 396, 'size': 348611416, 'width': 704}, 'updated_at': '2023-04-17T18:58:27Z'}, {'_id': '##3d96af86daab572f3481##', 'created_at': '2023-04-17T18:56:08Z', 'metadata': {'duration': 1800.56, 'engine_id': 'marengo2.5', 'filename': '20211113T200000Z.mp4', 'fps': 25, 'height': 396, 'size': 327766175, 'width': 704}, 'updated_at': '2023-04-17T18:57:51Z'}], 'page_info': {'limit_per_page': 10, 'page': 1, 'total_duration': 9002.76, 'total_page': 1, 'total_results': 5}} [{'video_id': '##3d978c86daab572f3481##', 'video_name': '20211113T190000Z.mp4'}, {'video_id': '##3d975786daab572f3481##', 'video_name': '20211114T170000Z.mp4'}, {'video_id': '##3d972e86daab572f3481##', 'video_name': '20211113T193000Z.mp4'}, {'video_id': '##3d96d386daab572f3481##', 'video_name': '20211121T133000Z.mp4'}, {'video_id': '##3d96af86daab572f3481##', 'video_name': '20211113T200000Z.mp4'}] </code></pre>
Extracting the logo appearing on screen
Time to put our plan into action! We'll now proceed to extract all logo content from the chosen video:
<pre><code class="python">VIDEO_ID = '###a849b86daab572f349242' LOGO_URL = f"{API_URL}/indexes/{INDEX_ID}/videos/{VIDEO_ID}/logo" response = requests.get(LOGO_URL, headers=default_header) print (f"Status code: {response.status_code}") logo_data = response.json() pprint (logo_data) </code></pre>
Output:
<pre><code class="python">Status code: 200 {'data': [{'end': 16, 'start': 15, 'value': 'Ducati Corse'}, {'end': 23, 'start': 22, 'value': 'Bank of Jordan'}, {'end': 23, 'start': 22, 'value': 'Han Chiang High School'}, {'end': 24, 'start': 23, 'value': 'Peugeot'}, {'end': 25, 'start': 24, 'value': 'Dr Lal Path Labs'}, {'end': 26, 'start': 25, 'value': 'Z8Games'}, {'end': 29, 'start': 27, 'value': 'Sky Sports'}, {'end': 29, 'start': 28, 'value': 'Tout'}, {'end': 31, 'start': 30, 'value': 'Sky UK'}, {'end': 31, 'start': 30, 'value': 'New Balance'}, {'end': 31, 'start': 30, 'value': 'Industria'}, {'end': 33, 'start': 32, 'value': 'Esport3'}, {'end': 35, 'start': 32, 'value': 'Nissan'}, {'end': 33, 'start': 32, 'value': 'GoCar'}, {'end': 34, 'start': 33, 'value': 'Land Bank of the Philippines'}, {'end': 34, 'start': 33, 'value': 'Z8Games'}, {'end': 37, 'start': 36, 'value': 'Tout'}, {'end': 37, 'start': 36, 'value': 'Zazzle'}, {'end': 39, 'start': 38, 'value': 'Z8Games'}, {'end': 39, 'start': 38, 'value': 'Giochi Preziosi'}, {'end': 41, 'start': 40, 'value': 'Mini'}], 'id': '###a849b86daab572f349242', 'index_id': '###a73aa8b1dd6cde172a933'} </code></pre>
Clearly, the API skillfully extracted all the on-screen logos line by line. This information can be stored as metadata for subsequent workflows, including content filtering, classification, and search purposes. Please note that the output displayed here is abbreviated for conciseness - the actual output was considerably more extensive.
Logo Search - searching for specific logo(s) within all indexed videos
Launching our search query utilizing the logo search option to uncover pertinent logo pattern matches within our collection of indexed videos:
<pre><code class="python"># Construct the URL of the `/search` endpoint SEARCH_URL = f"{API_URL}/search/" # Declare a dictionary named `data` data = { "index_id": INDEX_ID, "query": "honda", "search_options": [ "logo" ] } # Extracting query to later pass it to flask application input_query = data["query"] # Make a search request response = requests.post(SEARCH_URL, headers=default_header, json=data) if response.status_code == 200: print(f"Status code: {response.status_code} - Success") else: print(f"Status code: {response.status_code}") pprint(response.json()) </code></pre>
Output:
<pre><code class="python">Status code: 200 - Success {'data': [{'confidence': 'high', 'end': 19, 'metadata': [{'text': 'Honda', 'type': 'logo'}], 'score': 92.28, 'start': 18, 'video_id': '###d96af86daab572f348###'}, {'confidence': 'high', 'end': 104, 'metadata': [{'text': 'Honda', 'type': 'logo'}], 'score': 92.28, 'start': 103, 'video_id': '###d978c86daab572f348###'}, {'confidence': 'high', 'end': 137, 'metadata': [{'text': 'Honda', 'type': 'logo'}], 'score': 92.28, 'start': 136, 'video_id': '###d978c86daab572f348###'}, {'confidence': 'high', 'end': 269, 'metadata': [{'text': 'Honda', 'type': 'logo'}], 'score': 92.28, 'start': 268, 'video_id': '###d96af86daab572f348###'}, {'confidence': 'high', 'end': 392, 'metadata': [{'text': 'Honda', 'type': 'logo'}], 'score': 92.28, 'start': 391, 'video_id': '###d96af86daab572f348###'}, {'confidence': 'high', 'end': 478, 'metadata': [{'text': 'Honda', 'type': 'logo'}], 'score': 92.28, 'start': 477, 'video_id': '###d975786daab572f348###'}, {'confidence': 'high', 'end': 483, 'metadata': [{'text': 'Honda', 'type': 'logo'}], 'score': 92.28, 'start': 482, 'video_id': '###d978c86daab572f348###'}], 'page_info': {'limit_per_page': 10, 'next_page_token': 'fc3c420a-5971-428a-8796-9e5c077754c0-1', 'page_expired_at': '2023-05-26T18:40:26Z', 'total_results': 47}, 'search_pool': {'index_id': '###d9556f607a5a7bd9ea###', 'total_count': 5, 'total_duration': 9003}} </code></pre>
Once more, the API proficiently scoured and retrieved all on-screen logos corresponding to the input logo name, but this time across the entire index of videos we've uploaded.
Preparing the data for the Flask application to ensure our results will be presented neatly:
<pre><code class="python">video_data = [{'start': d['start'], 'end': d['end'], 'confidence': d['confidence'], 'text': d['metadata'][0]['text']} for d in search_data['data']] video_search_dict = {} for vd in video_data: if search_data['data'][0]['video_id'] in video_search_dict: video_search_dict[search_data['data'][0]['video_id']].append(vd) else: video_search_dict[search_data['data'][0]['video_id']] = [vd] pprint(video_search_dict) </code></pre>
Output:
<pre><code class="python"> {'###d96af86daab572f348###': [{'confidence': 'high', 'end': 19, 'start': 18, 'text': 'Honda'}, {'confidence': 'high', 'end': 104, 'start': 103, 'text': 'Honda'}, {'confidence': 'high', 'end': 137, 'start': 136, 'text': 'Honda'}, {'confidence': 'high', 'end': 269, 'start': 268, 'text': 'Honda'}, {'confidence': 'high', 'end': 392, 'start': 391, 'text': 'Honda'}, {'confidence': 'high', 'end': 478, 'start': 477, 'text': 'Honda'}, {'confidence': 'high', 'end': 483, 'start': 482, 'text': 'Honda'}, {'confidence': 'high', 'end': 491, 'start': 487, 'text': 'Honda'}, {'confidence': 'high', 'end': 561, 'start': 560, 'text': 'Honda'}, {'confidence': 'high', 'end': 586, 'start': 585, 'text': 'Honda'}]} </code></pre>
Further data preparation for the logo detection results, followed by our standard procedure of pickling everything:
<pre><code class="python">video_id = ocr_data.get('id') data_list = logo_data.get('data') data_to_save = { 'video_id': video_id, 'data_list': data_list, 'video_id_name_list': video_id_name_list, 'video_search_dict': video_search_dict } import pickle # Save data to a pickle file with open('data.pkl', 'wb') as f: pickle.dump(data_to_save, f) </code></pre>
Building the Demo App
Now we've reached the last stretch of our current journey – integrating everything to make our outputs come to life. Besides the standard configuration we implement for fetching videos from the local folder and loading the pickled data dispatched from the Jupyter notebook, this time we have some additional requirements - a conversion of timestamps from a seconds-only format to a minutes-and-seconds format. This makes the data visualization on the webpage more intuitive. Here's the code for the app.py file:
<pre><code class="python">from flask import Flask, render_template, send_from_directory import pickle import os from collections import defaultdict app = Flask(__name__) # Load data from a pickle file with open('data.pkl', 'rb') as f: loaded_data = pickle.load(f) # Access the data video_id = loaded_data['video_id'] data_list = loaded_data['data_list'] video_id_name_list = loaded_data['video_id_name_list'] video_search_dict = loaded_data['video_search_dict'] VIDEO_DIRECTORY = os.path.join(os.path.dirname(os.path.realpath(__file__)), "static") @app.route('/<path:filename>') def serve_video(filename): print(VIDEO_DIRECTORY, filename) return send_from_directory(directory=VIDEO_DIRECTORY, path=filename) @app.route('/') def home(): for item in data_list: if ":" not in str(item['start']): item['start'] = int(item['start']) item['start'] = f"{item['start'] // 60}:{item['start'] % 60:02}" if ":" not in str(item['end']): item['end'] = int(item['end']) item['end'] = f"{item['end'] // 60}:{item['end'] % 60:02}" video_id_name_dict = {video['video_id']: video['video_name'] for video in video_id_name_list} # video_name = video_id_name_dict.get(video_id) return render_template('index.html', data=data_list[:10], video_id_name_dict=video_id_name_dict, video_id=video_id, video_search_dict = video_search_dict) if __name__ == '__main__': app.run(debug=True) </code></pre>
HTML Template
Now, it's time to weave together the final piece: our Jinja-2 based HTML template code. This pulls together all the data we've transmitted through the Flask app.py file. We'll kick things off by showcasing the logo detection results. The video player will cover the entire duration of the video, and just below it, a table will display the start, end, and text identified during that specific duration on the screen. To improve clarity, timestamps will be formatted in minutes-and-seconds and will be interactive, allowing us to jump to the exact timestamp and commence video playback from there. Keep in mind, I've converted the timestamps back to seconds when passing them to the JavaScript function playVideo, as this function is designed to accept timestamps in a seconds-only format for video playback.
<pre><code class="language-html"><!DOCTYPE html> <html> <head> <link rel="shortcut icon" href="#" /> <title>Logo Detection</title> <style> body { text-align: center; font-family: Arial, sans-serif; color: #333; background-color: #f5f5f5; } h1, h2 { color: #444; } table { margin: 0 auto; border-collapse: collapse; width: 80%; margin-top: 20px; } th, td { border: 1px solid #ddd; padding: 8px; text-align: center; } th { padding-top: 12px; padding-bottom: 12px; text-decoration: underline; color: black; } video { width: 40%; height: auto; margin-top: 20px; } /* search style */ .video-container { text-align: center; margin-bottom: 2em; padding: 1em; background-color: #fff; border: 1px solid #ddd; border-radius: 4px; box-shadow: 0 2px 4px rgba(0,0,0,0.1); } table { margin: 0 auto; margin-bottom: 1em; } th, td { padding: 0.5em; border: 1px solid #ddd; } </style> <script> function playVideo(timeString) { var timeParts = timeString.split(":"); var time = parseInt(timeParts[0]) * 60 + parseInt(timeParts[1]); var video = document.querySelector('#mainVideo'); video.currentTime = time; video.play(); } </script> </head> <body> <h1>Logo detection in the entire Video</h1> <h3>Video file: <i>{{ video_id_name_dict[video_id]}}</i></h3> <video id="mainVideo" controls> <source src="{{ url_for('static', filename=video_id_name_dict[video_id]|string) }}" type="video/mp4"> Your browser does not support the video tag. </video> <br /> <br /> <br /> <table> <tr> <th>Start</th> <th>End</th> <th>Value</th> </tr> {% for item in data %} <tr> <td><a href="javascript:void(0)" onclick="playVideo('{{ item['start'] }}')">{{ item['start'] }}</a></td> <td>{{ item['end'] }}</td> <td>{{ item['value'] }}</td> </tr> {% endfor %} </table> <br /> <br /> {% for video_id, results in video_search_dict.items() %} <div class="video-container"> <h1>Logo search results</h1> <h2>Video file: <i>{{ video_id_name_dict[video_id] }}</i></h2> <h2>Entered query: <i>{{input_query}}</i></h2> {% for result in results %} <video controls preload="metadata" style="width: 40%;"> <source src="{{ url_for('static', filename=video_id_name_dict[video_id]) }}#t={{ result['start'] }},{{ result['end'] }}" type="video/mp4"> Your browser does not support the video tag. </video> <table> <tr> <th>Start</th> <th>End</th> <th>Confidence</th> <th>Text</th> </tr> <tr> <td>{{ result['start'] }}</td> <td>{{ result['end'] }}</td> <td>{{ result['confidence'] }}</td> <td>{{ result['text'] }}</td> </tr> </table> {% endfor %} </div> {% endfor %} </body> </html> </code></pre>
Running the Flask app
Awesome! let’s just run the last cell of our Jupyter notebook to launch our Flask app:
<pre><code class="python">%run app.py </code></pre>
You should see an output similar to the one below, confirming that everything went as anticipated 😊:
After clicking on the URL link http://127.0.0.1:5000, you should be greeted with the following web page:
Here's the Jupyter Notebook containing the complete code that we've put together throughout this tutorial - https://drive.google.com/drive/folders/1D97_UU2Z0lvp3y52BHV5GKkSNOQKv3Xi?usp=share_link
Outro
Expect more exciting content coming your way! If you haven't already, I cordially invite you to join our vibrant Discord community, populated with individuals who share a passion for multimodal AI.
See you next time,
Ankit
Crafting stellar Developer Experiences @Twelve Labs
Cheers!
Related articles

The Apparatus: Building the Machine That Runs While We Don't

How TwelveLabs Saves Hours of Manual Video Annotation with a Few API Calls

From Raw Surveillance to Training-Ready Datasets in Minutes: Building an Automated Video Curator with TwelveLabs and FiftyOne

From Manual Review to Automated Intelligence: Building a Surgical Video Analysis Platform with YOLO and Twelve Labs




© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved
© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved
© 2021
-
2026
TwelveLabs, Inc. All Rights Reserved